
The New York Times and Amazon Strike Landmark AI Licensing Deal: What It Means for Journalism and Tech

The rapid expansion of artificial intelligence (AI) technologies has fundamentally altered the dynamics between technology firms and content providers. One of the most consequential developments in this evolving relationship is the recent announcement of a landmark licensing agreement between The New York Times and Amazon. This strategic alliance reflects a growing trend in which media organizations are negotiating terms to license their content to tech giants that increasingly rely on large volumes of high-quality data to train and enhance their AI models. The deal between these two industry leaders is not only significant in its immediate implications, but also emblematic of broader changes in the digital content and AI development landscape.
At its core, the partnership enables Amazon to license a range of content from The New York Times, including articles from its core publication, its culinary section NYT Cooking, and its sports-focused platform The Athletic. Notably, Wirecutter—a New York Times-owned product review site—was excluded from the deal, likely due to its existing affiliate relationship with Amazon. The content is intended for integration into Amazon’s consumer-facing products, most prominently the Alexa voice assistant, and is also expected to be used in the training of Amazon’s proprietary generative AI models. Although the financial terms of the agreement were not disclosed publicly, both parties have acknowledged that the arrangement is long-term and comprehensive in scope.
This deal comes at a pivotal moment. As generative AI models become more sophisticated and widespread, they increasingly require access to premium, trustworthy, and legally licensed content to improve their reasoning capabilities and reduce the likelihood of hallucinations—incorrect or misleading outputs. For Amazon, which has been making considerable investments in the development of large language models (LLMs) and voice-based technologies, gaining access to The New York Times’ extensive archives provides a substantial advantage in the pursuit of accuracy, reliability, and user trust. For The New York Times, the deal represents not only a lucrative licensing opportunity but also a strategic positioning move in a digital landscape where the boundaries between media, AI, and technology are becoming increasingly fluid.
The importance of this agreement is magnified when placed within the broader context of legal tensions and competitive pressures in the media and AI ecosystems. In late 2023, The New York Times filed a lawsuit against Microsoft and OpenAI, alleging that its copyrighted materials had been used without permission to train the companies’ respective AI models. The lawsuit is ongoing and could set a precedent for how courts interpret the fair use of journalistic content in the age of machine learning. That legal confrontation, juxtaposed with the Amazon licensing deal, underscores a larger industry reckoning: media companies must now decide whether to litigate, negotiate, or collaborate with AI developers over the use of their intellectual property.
This blog post aims to provide a detailed and structured analysis of the New York Times–Amazon licensing deal. It will begin by breaking down the specific terms of the agreement and the strategic motivations behind it. Then, it will examine the broader legal and industry context that shaped the deal, particularly in light of the NYT’s ongoing lawsuit against OpenAI and Microsoft. The post will further explore the implications for journalism, AI development, and the future of content licensing. Finally, it will conclude by outlining the path ahead for media companies, technology firms, and policymakers navigating this increasingly complex and intertwined digital ecosystem.
To further enhance understanding, this post will incorporate two visual charts and one comparative table. The first chart will offer a historical timeline of key AI licensing deals across the media industry, situating the NYT-Amazon agreement within a broader trend. The second chart will forecast the projected growth of the AI content licensing market from 2025 to 2030. Additionally, the table will compare various media companies’ approaches—whether legal, cooperative, or adversarial—toward AI firms in the context of content usage.
This agreement also signals a shift in how legacy media institutions are adapting to the realities of algorithmically-driven content consumption. With the proliferation of AI-powered tools like chatbots, voice assistants, and personalized recommendation engines, the value of authoritative and structured content has never been higher. By positioning itself as a premium content supplier for AI training and implementation, The New York Times is asserting control over how its content is used in technological contexts, thereby protecting its brand, revenue streams, and editorial integrity.
In sum, the Amazon-New York Times licensing deal is far more than a transactional arrangement between two influential companies. It is a harbinger of the future—a future in which journalism, artificial intelligence, and digital innovation are no longer siloed but intricately interconnected. As we delve deeper into the specifics and implications of this deal, it becomes clear that it is likely the first of many such arrangements. This new paradigm necessitates careful analysis, not just of the contractual details, but of the philosophical, economic, and ethical questions that arise when human-created knowledge intersects with machine intelligence.
The Deal Unpacked: Scope, Terms, and Strategic Motivations
The licensing agreement between The New York Times and Amazon represents a sophisticated and strategic alignment of interests between a traditional media powerhouse and a technology titan aggressively expanding its artificial intelligence capabilities. Though financial figures remain confidential, the public disclosure of the deal’s structural components offers a window into how major corporations are navigating the rapidly evolving terrain of AI content licensing. The arrangement reflects a broader market trend where leading content producers are forging partnerships that ensure both control over intellectual property and continued relevance in the digital age.
Scope of the Licensing Agreement
The agreement grants Amazon access to a curated selection of The New York Times’ editorial content. This includes articles and reports from the core New York Times publication, the NYT Cooking vertical which focuses on culinary content and recipes, and The Athletic, a subscription-based sports journalism platform acquired by The Times in 2022. However, Wirecutter, the Times-owned product review and recommendations service, has been explicitly excluded from the deal. The likely rationale is Wirecutter’s direct relationship with Amazon through affiliate marketing programs, creating a potential conflict of interest were its content to be licensed for AI training or integration into Amazon products.
Under the agreement, Amazon will utilize the licensed content across multiple applications. Key among these is integration with Alexa, Amazon’s voice-based virtual assistant, which will now be able to generate or respond with more nuanced, accurate, and timely information drawn from the Times’ authoritative editorial output. Additionally, the content will feed into the training of Amazon’s proprietary generative AI models, which are expected to power a wide array of products—from cloud services within AWS to consumer applications embedded in Amazon devices.
The contract is reportedly a multi-year agreement, signaling a long-term commitment rather than a short-term experiment. Both companies have emphasized that the collaboration is designed to be sustainable and adaptive to technological advancements and shifts in user expectations. The commitment to longevity also points to the substantial resources and strategic planning involved in negotiating and executing such a deal.
Terms and Conditions: Protecting Editorial Integrity
While the exact contractual provisions are private, statements from both parties suggest that significant safeguards have been put in place to preserve the editorial independence and reputational standards of The New York Times. As generative AI systems rely on training data to generate new text, concerns about attribution, accuracy, and context are paramount. According to sources close to the matter, The Times retains certain rights over how its content may be represented, and Amazon is expected to implement content-use guidelines to ensure fidelity to the original context and tone of the material.
This focus on preserving journalistic integrity underscores a vital challenge in AI development: ensuring that outputs do not distort or misrepresent the original intent of the source material. It is expected that Amazon will deploy systems capable of referencing the original source in some applications—particularly voice-based answers via Alexa—helping to maintain transparency and accountability.
Furthermore, this deal does not imply wholesale content ingestion or blanket usage. Rather, it is a selective and structured licensing model, ensuring that specific content types and usage contexts are clearly delineated. This structured approach likely reflects lessons learned from ongoing legal disputes in the industry where media outlets have accused AI firms of indiscriminately scraping copyrighted content without consent or compensation.
Strategic Motivations for The New York Times
For The New York Times, the strategic rationale behind the agreement is multifaceted. Firstly, it opens up a new revenue stream through content licensing—an increasingly attractive option in an era when traditional advertising revenues are under pressure. By monetizing its editorial content in a structured and legally sound manner, The Times bolsters its financial sustainability without compromising its subscription-based business model.
Secondly, the deal positions the newspaper as a thought leader in digital transformation within journalism. At a time when many media organizations are still assessing how to respond to the rise of generative AI, The Times has taken a proactive stance—simultaneously pursuing legal action against unauthorized use (in the case of OpenAI and Microsoft) and engaging in negotiated partnerships (as seen with Amazon). This dual-track strategy reflects a sophisticated understanding of the risks and opportunities posed by AI technologies.
Thirdly, integration with Alexa potentially expands audience reach, particularly among users who may not be subscribers but regularly use Amazon devices. This could function as a top-of-funnel mechanism for brand awareness and user engagement, ultimately supporting subscriber growth and deeper content interaction.
Strategic Motivations for Amazon
From Amazon’s perspective, the licensing deal is an essential investment in the quality and reliability of its AI outputs. As consumer expectations for digital assistants and AI-generated content grow, the need for training data that is not only abundant but also credible becomes critical. The New York Times’ archives offer precisely this: a rich repository of professionally vetted, fact-checked, and timely content.
Moreover, the deal aligns with Amazon’s broader ambition to compete with other leading AI developers, such as OpenAI, Google DeepMind, and Anthropic. By incorporating NYT content into its proprietary models, Amazon enhances the linguistic and contextual sophistication of its tools—particularly in areas requiring nuanced interpretation of current events, human behavior, and complex social issues.
In addition, the integration of high-quality content into Alexa could differentiate Amazon in the voice assistant market, which has faced criticism for inaccuracies and limitations in conversational depth. Empowering Alexa with reputable editorial content may improve its ability to deliver insightful responses and support more advanced use cases, including education, news summarization, and decision support.
Finally, the structured licensing model provides Amazon with a legal and reputational shield against the growing scrutiny of how AI firms source their training data. In the wake of increasing litigation and regulatory attention, building a portfolio of legitimate content partnerships is not just a competitive advantage—it is a risk mitigation strategy.
Broader Implications
The Times-Amazon agreement highlights the emerging best practices for AI content licensing in the media industry. Rather than relying on ambiguous interpretations of fair use, the deal reflects a deliberate, negotiated pathway that balances the rights of content creators with the needs of technology developers. It also reinforces the growing realization that generative AI cannot function in a vacuum; it requires a steady influx of human-generated knowledge that is current, contextual, and credible.
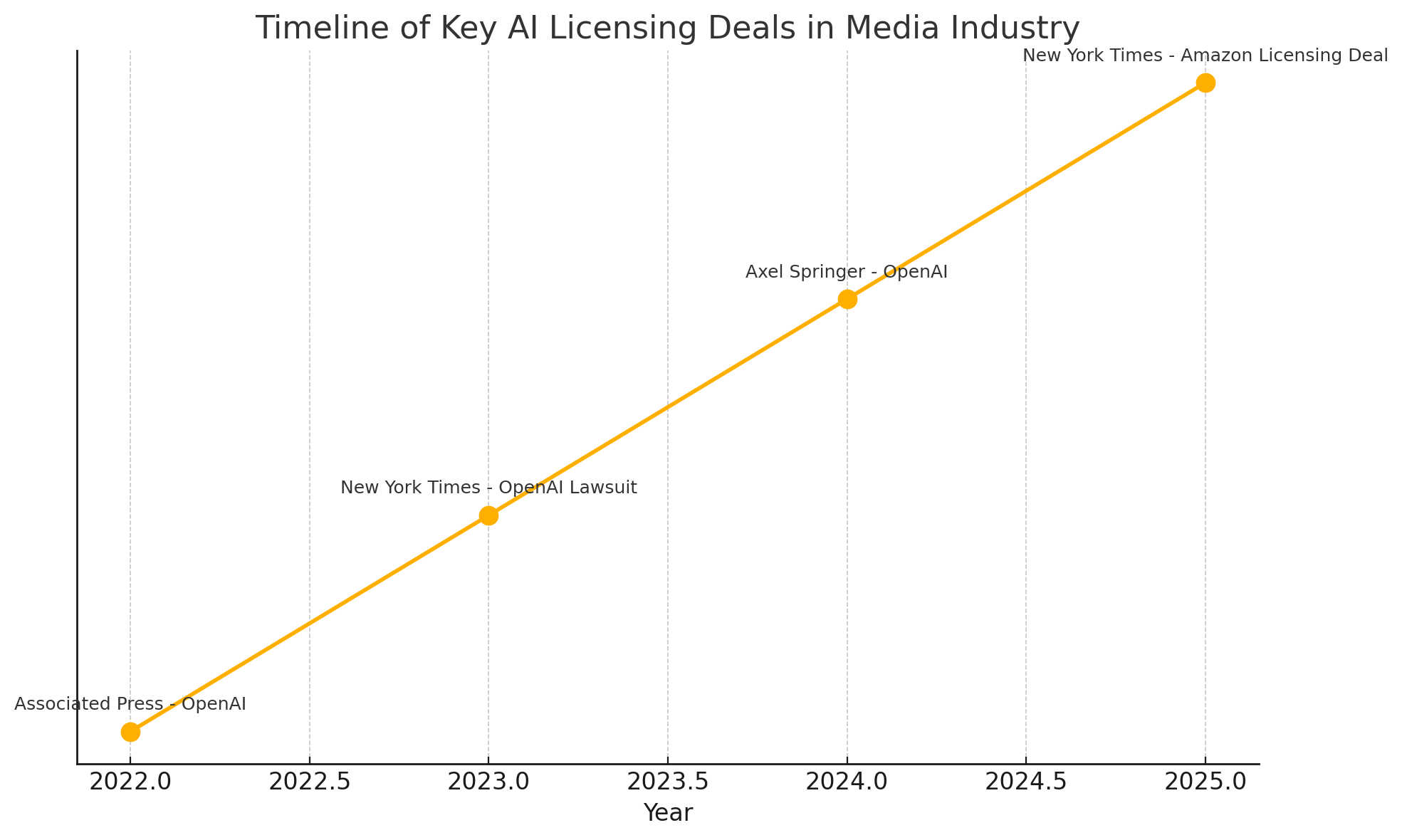
Contextualizing the Deal: Legal Battles and Industry Trends
The licensing agreement between The New York Times and Amazon does not exist in isolation; rather, it is emblematic of a larger trend that is reshaping the relationship between media organizations and artificial intelligence developers. Over the past two years, a series of legal battles, licensing deals, and corporate realignments have emerged, highlighting both the disruptive potential of generative AI and the growing imperative for clearly defined content usage rights. This section aims to contextualize the NYT-Amazon deal within that broader landscape—examining the evolving legal frameworks, the divergent strategies adopted by leading media houses, and the resulting shifts in the operational paradigms of AI companies.
The Legal Catalyst: The New York Times v. OpenAI and Microsoft
In December 2023, The New York Times made headlines when it filed a high-profile lawsuit against OpenAI and its partner Microsoft. The central allegation was that these companies had used millions of The Times’ copyrighted articles without permission to train generative AI models, including ChatGPT and other large language models. The lawsuit accused the defendants of “unlawful copying and use” of valuable journalistic content and demanded not only financial restitution but also injunctive relief that would force the AI developers to delete all Times content from their training datasets.
The legal implications of this case are profound. At its heart is the question of whether using publicly available internet content for AI training constitutes “fair use” under copyright law—a legal doctrine that traditionally allows limited use of copyrighted materials without permission under certain conditions. The Times argues that large-scale ingestion of its articles, which directly contributes to the commercial success of AI tools, cannot be justified under fair use, especially when the outputs are capable of mimicking or substituting original reporting.
This lawsuit, still ongoing at the time of writing, has placed enormous pressure on generative AI firms to reassess how they source their training data. It has also empowered other publishers to challenge what many perceive as exploitative practices by AI developers who have operated in legal grey areas, particularly during the early phases of model development.
A Split in Strategy: Litigation vs. Licensing
The legal action by The New York Times represents one approach in a spectrum of strategies adopted by media organizations. On the other end of the spectrum are companies like Axel Springer and Associated Press, both of which have opted to license their content to OpenAI rather than pursue litigation. In 2023, the Associated Press became one of the first major news outlets to sign a licensing agreement with OpenAI, granting access to its news archive for model training and deployment. Axel Springer followed suit in 2024, licensing content from Politico and Business Insider.
These licensing deals serve two purposes. First, they provide AI companies with legal access to professionally curated and fact-checked content that improves model performance. Second, they offer media companies a new monetization avenue that aligns with the digital realities of content consumption and distribution. For some publishers, the prospect of recurring licensing revenue, combined with brand exposure via AI-powered platforms, outweighs the uncertainties and costs of litigation.
What makes the NYT-Amazon agreement particularly noteworthy is that it falls between these two extremes. The Times continues to pursue legal action against OpenAI and Microsoft while simultaneously engaging in a collaborative agreement with Amazon. This dual-pronged approach suggests a nuanced strategy: litigate where there is evidence of unauthorized use, and negotiate licensing deals where mutual benefit and editorial control can be maintained.
Evolving Industry Norms and Institutional Pressures
The fragmentation in approach across media companies points to a deeper lack of regulatory clarity. As of mid-2025, there is still no unified global standard governing the rights of content creators in the context of AI training. While the European Union is advancing its AI Act—which includes some provisions related to transparency and data sourcing—most jurisdictions, including the United States, remain in the early stages of legislative development. This regulatory vacuum has forced private actors to take the lead in defining the norms and boundaries of AI content usage.
As these private agreements proliferate, they are beginning to form a de facto industry standard for AI content licensing. Key components of these deals often include:
- Restricted access to premium or proprietary content.
- Attribution requirements, where applicable.
- Editorial safeguards to prevent distortion or misuse.
- Revenue-sharing models based on content usage frequency or reach.
These parameters not only protect the intellectual property of media organizations but also help AI developers maintain credibility and compliance in a risk-laden regulatory environment.
In this context, Amazon’s deal with The New York Times can be seen as a model of best practice. It signals to regulators and industry peers that responsible AI development includes respect for content ownership and fair compensation. It also suggests that Amazon is preparing itself for a future in which transparency and traceability in AI training datasets may be not just expected but legally required.
Competitive Pressures and the Economics of Licensing
The growing prevalence of content licensing deals also has competitive implications for both AI firms and media companies. For AI developers, access to exclusive, high-quality datasets can be a significant differentiator. Firms that invest in licensed content are more likely to develop tools that are accurate, nuanced, and legally defensible. This is especially critical in domains like news generation, educational assistance, and healthcare, where factual precision is non-negotiable.
Conversely, for media organizations, being a preferred content partner to a leading AI firm can bolster financial stability and strategic relevance. As subscription growth plateaus for many outlets, and as traditional advertising models lose efficacy, licensing revenue offers a scalable and forward-looking alternative. Moreover, partnerships with AI companies can extend a publisher’s reach, helping it connect with new demographics and use cases, from voice assistants to AI-powered research tools.
To illustrate these divergent strategies, the following table provides a comparative overview:
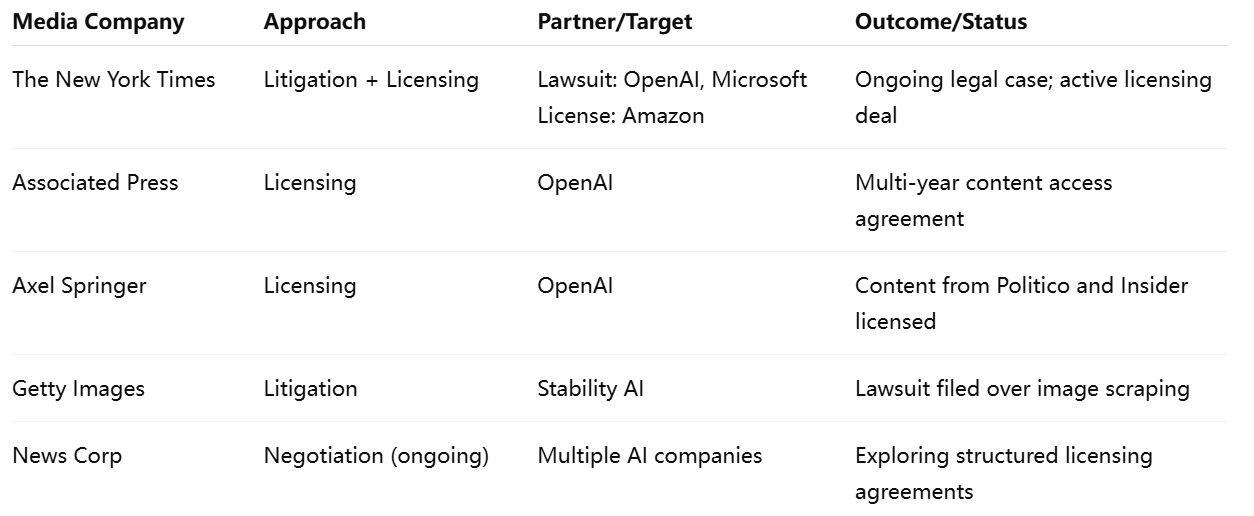
This table underscores the variety of paths available to media organizations, each influenced by the legal, economic, and technological dynamics specific to their operations and objectives.
Implications for the Future
Journalism, AI, and Content Licensing
The licensing agreement between The New York Times and Amazon serves as more than just a transactional milestone between a media organization and a technology company. It represents a transformative moment that could redefine the very nature of how journalism is monetized, protected, and disseminated in the era of artificial intelligence. The deal offers a template for reconciling the competing interests of legacy media and emerging AI technologies—balancing the imperatives of intellectual property protection with the need for high-quality training data. In this section, we explore the far-reaching implications of this agreement across three primary dimensions: the future of journalism, the evolution of AI development, and the standardization of content licensing frameworks.
Implications for Journalism: Beyond the Paywall
For decades, journalism has grappled with the challenge of monetizing high-quality editorial content in a digital environment dominated by free access and platform-driven distribution. The proliferation of AI tools has compounded this challenge, as publishers now face the risk of their content being harvested, repurposed, and echoed by generative models with no attribution or compensation. In this context, the Amazon-NYT licensing agreement sets a crucial precedent—demonstrating that professional journalism has intrinsic value not only for human readers but also as essential fuel for artificial intelligence systems.
One immediate implication is the emergence of licensing revenue as a new business pillar for media companies. While advertising, subscriptions, and syndication have traditionally constituted the financial backbone of journalism, licensing content for AI training and deployment introduces a scalable revenue stream tied to technological innovation. For The New York Times, which has invested heavily in subscription growth and digital transformation, the Amazon deal underscores a forward-looking strategy that leverages its archive of curated knowledge as a long-term asset.
Additionally, the deal underscores the need for editorial oversight in AI environments. With content now being disseminated via voice assistants and embedded in AI applications, newsrooms must consider how their material will be presented, paraphrased, or interpreted by algorithmic systems. This introduces a new dimension to journalistic ethics and standards: ensuring that editorial integrity is preserved not only in human-to-human communication, but also in machine-mediated interactions. As such, future licensing agreements may increasingly include provisions for content context preservation, real-time attribution, and dispute resolution mechanisms in case of misrepresentation.
Moreover, the deal signals a broader cultural shift in which news organizations become integral to the digital infrastructure powering daily life. From health advice dispensed via smart speakers to breaking news relayed through AI-generated summaries, journalism is poised to become a foundational element in how societies interact with AI systems. This expands the role of newsrooms from information providers to algorithmic knowledge contributors, with heightened responsibility and influence.
Implications for AI Development: Content Quality and Model Performance
From the vantage point of AI developers, the value of premium editorial content like that produced by The New York Times lies in its factual accuracy, linguistic sophistication, and contextual depth. Generative AI models, particularly large language models (LLMs), are only as robust and reliable as the datasets on which they are trained. By integrating licensed content from reputable publishers, AI companies can mitigate several risks, including factual hallucinations, tone inconsistency, and regulatory non-compliance.
The Amazon-NYT agreement thus underscores a vital trend in AI development: the pivot from volume to quality. Early LLMs were trained on massive, indiscriminately scraped internet datasets, prioritizing scale over reliability. However, as the limitations of this approach become increasingly apparent—particularly in critical use cases like healthcare, education, and law—the demand for structured, vetted, and ethically sourced data is rising sharply. Licensed journalistic content meets these requirements, offering a source of truth that can be programmatically incorporated into generative outputs.
Furthermore, incorporating high-quality news content into AI systems enhances their contextual and temporal awareness. Unlike encyclopedic knowledge, news is dynamic and constantly evolving. This makes it ideal for training models that must stay updated and produce responses grounded in real-world developments. For instance, Amazon’s voice assistant Alexa, when augmented with current NYT content, can deliver richer, more informative answers—deepening user trust and platform engagement.
Yet, this integration also imposes new responsibilities on AI developers. Ethical data usage, bias mitigation, and source transparency become non-negotiable. With journalists’ words now embedded in automated systems, developers must implement safeguards to ensure that AI-generated outputs neither distort original content nor present it in misleading contexts. As scrutiny intensifies from regulators and the public, adherence to such principles will determine both legal compliance and reputational standing.
Implications for Content Licensing: Toward an Industry Framework
One of the most consequential aspects of the NYT-Amazon deal is its potential to influence the future of AI content licensing as a formalized industry practice. In the current environment—where legal clarity is lacking and enforcement is fragmented—such deals serve as informal blueprints for what responsible, equitable collaboration can look like.
Key features of the deal that may become industry norms include:
- Selective content access: Allowing AI companies to access specific types of content (e.g., articles, recipes, sports reporting) while withholding sensitive or strategic material (as seen with Wirecutter’s exclusion).
- Usage transparency: Requiring clear documentation of how, where, and to what extent the content will be used (e.g., in voice responses, model training, summarization).
- Revenue models: Implementing tiered or volume-based licensing fees tied to usage metrics, user reach, or model deployment scale.
- Editorial safeguards: Including stipulations to prevent defamatory, misleading, or contextually distorted use of journalistic content.
As more media organizations explore similar partnerships, there is a growing possibility of a standardized licensing framework—either industry-led or regulatory in nature. This would benefit both sides: giving publishers confidence in content protection, and giving AI companies legal certainty and access to consistent data quality. Moreover, such a framework could lay the foundation for new data marketplaces—platforms where verified content can be licensed, tracked, and audited in real time, with royalties automatically distributed to rights holders.
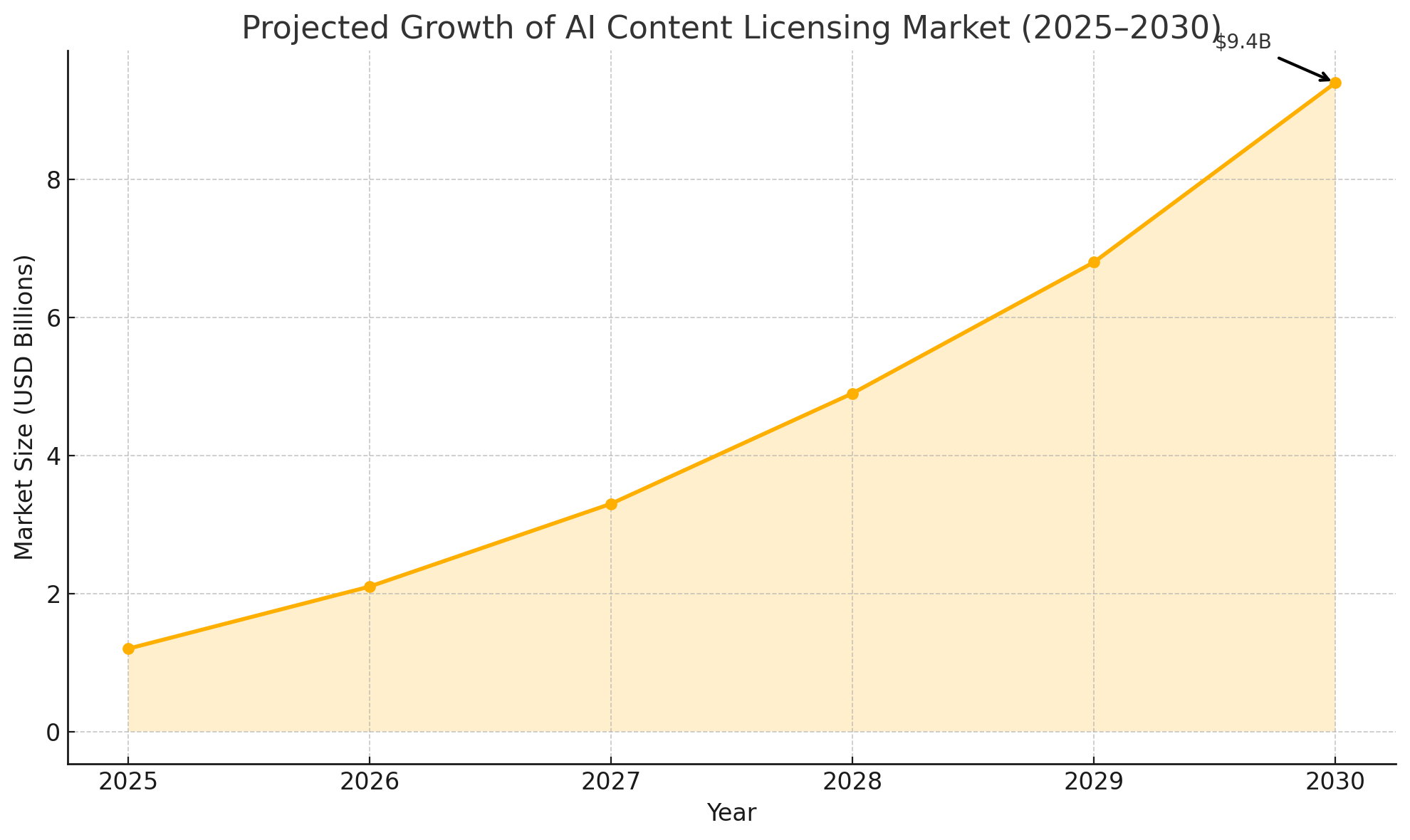
The chart reflects not only the financial scale of this emerging industry but also its central role in shaping the future of knowledge dissemination and technological development.
Navigating the Intersection of Media and Technology
The licensing agreement between The New York Times and Amazon is more than a commercial pact; it is a symbol of an evolving paradigm where media and technology industries are no longer operating in separate silos but are becoming increasingly interdependent. At the core of this collaboration lies a mutual recognition: high-quality journalism and sophisticated artificial intelligence are both essential components of a trusted, informed, and technologically advanced society. This section synthesizes the overarching themes explored throughout the blog and provides a forward-looking assessment of how such licensing deals are shaping the intersection of media and technology.
Redefining Boundaries Between Human Editorial Work and Machine Intelligence
The New York Times’ agreement with Amazon illustrates how the boundaries between human-curated knowledge and machine-generated responses are blurring. In previous technological epochs, journalism was consumed through fixed mediums—print, web pages, newsletters—requiring readers to seek out information. Today, AI systems such as voice assistants, chatbots, and search engines proactively surface information to users, often without them explicitly requesting a specific source.
This shift means that journalistic content is no longer merely a product—it is now infrastructure. It powers AI interfaces that millions of people rely on daily for information, decisions, and personal enrichment. Recognizing this infrastructural role, media organizations like The New York Times are taking strategic steps to retain control over how their work is repurposed in these new environments. The Amazon deal is one such strategic move, enabling The Times to remain embedded in the digital knowledge economy without relinquishing its editorial standards or ownership rights.
The agreement also challenges traditional perceptions of content value. Where once monetization was based on reader subscriptions or advertising impressions, the new frontier involves monetizing machine readability and algorithmic utility. This recalibration demands not only a shift in business models but also a redefinition of newsroom strategies and skill sets to ensure that journalism remains both economically viable and ethically governed in an AI-dominated ecosystem.
AI Developers and the Ethics of Data Procurement
On the technology front, Amazon’s decision to license content directly from The New York Times marks a significant departure from the data practices of many earlier AI initiatives, which frequently relied on web scraping and vague interpretations of “public domain” access. This agreement signifies a recognition that ethically sourced data is a prerequisite for both legal compliance and consumer trust.
AI developers are becoming increasingly aware that the quality of their models is directly tied to the provenance of their training data. By incorporating licensed content from trusted institutions, companies not only reduce legal exposure but also improve the reliability, factual accuracy, and contextual sensitivity of their outputs. In industries such as healthcare, education, journalism, and law—where the margin for error is thin—such quality controls are not merely beneficial but essential.
More importantly, this approach lays the groundwork for new norms around AI transparency and accountability. Users of AI-generated content, whether individuals or enterprises, are likely to demand assurance about the sources that underpin machine outputs. As AI applications become more embedded in public discourse and policy-making, the traceability and licensure of underlying data will increasingly be seen as vital indicators of trustworthiness.
The Amazon-NYT deal thus serves not only as a commercial transaction but also as a signal to regulators, developers, and consumers that responsible AI begins with responsible data practices.
Content Licensing as a Scalable, Sustainable Solution
For the broader media industry, the licensing of content to AI developers represents a promising and scalable pathway for revenue diversification. In contrast to advertising-based models that are increasingly dominated by tech platforms, licensing allows media organizations to extract direct economic value from the intellectual capital they have cultivated over decades.
This model is particularly well-suited to high-quality, structured content—such as investigative reporting, specialized analysis, and curated editorial coverage—which holds considerable value in training AI systems that aim to emulate human-like comprehension and reasoning. As more AI developers seek reliable, bias-reduced, and up-to-date content, content licensing is poised to become a core monetization strategy, especially for institutions with strong editorial reputations.
However, to scale effectively, the licensing model must evolve into a standardized and interoperable framework. Today, each agreement is bespoke—negotiated individually, with terms that are often confidential and non-replicable. This fragmentation limits efficiency and stymies broader adoption. The path forward likely involves the establishment of content licensing consortia, industry-wide databases of licensable content, and automated platforms that facilitate real-time tracking and royalties distribution.
Standardization would not only benefit publishers by expanding market access but also aid AI developers by providing consistent licensing procedures and reducing legal ambiguity. Over time, the development of open registries, machine-readable content licenses, and AI-readable metadata standards could allow licensing to function at the speed and scale required by real-time generative AI systems.
Regulatory Outlook: Preparing for the Next Phase
The legal and regulatory dimensions of this issue remain in flux. In jurisdictions around the world, policymakers are actively debating how to adapt copyright laws, intellectual property protections, and data governance frameworks to the realities of AI. The Amazon-NYT agreement, alongside similar deals involving OpenAI and publishers like Axel Springer and the Associated Press, may well influence future regulation—either by serving as a model of ethical best practice or by highlighting areas that require legislative clarity.
Going forward, regulators are likely to consider the following:
- Mandatory attribution standards for AI-generated content
- Disclosure requirements regarding training datasets
- Fair compensation mechanisms for data contributors
- Guidelines for permissible and non-permissible data usage
The proactive formation of licensing agreements like the one between The Times and Amazon may help forestall more restrictive regulatory interventions, offering a collaborative and market-based solution that aligns the interests of content creators, technology firms, and end-users.
The Road Ahead: Symbiosis, Not Conflict
Ultimately, the Amazon-NYT licensing deal signals the emergence of a new kind of symbiosis between media and technology. While past narratives have often portrayed the two as adversaries—journalists guarding truth against the encroachment of tech platforms—this agreement suggests a future where alignment is not only possible but mutually beneficial.
For media companies, such partnerships offer renewed relevance and financial sustainability in an age of algorithmic content delivery. For tech firms, they provide the credibility and structure necessary to build reliable, ethically sound AI systems. And for the public, they offer the promise of more accurate, transparent, and meaningful machine-generated content.
In navigating this intersection, both industries must continue to engage in dialogue, experimentation, and, where necessary, negotiation. The stakes are high—not just for their respective futures, but for the quality of information, knowledge, and discourse in a rapidly digitizing world. The New York Times and Amazon may have struck the first chord in this new symphony, but the full composition remains unwritten. It will require participation, innovation, and trust from all sides to ensure that the next chapter in media-tech collaboration is both equitable and enduring.
References
- Reuters – New York Times signs AI licensing deal with Amazon
https://www.reuters.com/business/retail-consumer/new-york-times-amazon-sign-ai-licensing-deal - The Verge – NYT signs deal with Amazon to license content for AI
https://www.theverge.com/2025/05/30/new-york-times-ai-deal-amazon - Axios – Amazon signs AI content deal with the New York Times
https://www.axios.com/2025/05/30/nyt-amazon-ai-licensing-deal - New York Times Company – Our Response to Generative AI Models
https://www.nytco.com/press/the-new-york-times-generative-ai-response - Associated Press – OpenAI and AP announce licensing agreement
https://apnews.com/article/openai-associated-press-licensing - Financial Times – How publishers are striking back against AI firms
https://www.ft.com/content/34d7b390-9a85-4f3d-aaa6-437cc3a2f5a7 - Washington Post – Publishers want payment for AI training
https://www.washingtonpost.com/technology/2024/02/22/publishers-ai-training-deals - CNBC – Media companies explore AI licensing for content monetization
https://www.cnbc.com/2024/11/18/media-companies-ai-licensing-deals - TechCrunch – Axel Springer signs deal to license content to OpenAI
https://techcrunch.com/2024/12/13/axel-springer-openai-licensing - Wired – The future of news in the age of AI
https://www.wired.com/story/ai-journalism-future-nyt-deal