
Smarter Databases: How Google Cloud is Redefining Data Management with AI

In the era of big data and artificial intelligence, cloud databases are evolving from mere data storage engines into intelligent systems that actively optimize and analyze data. Google Cloud – a major player in cloud computing – has been steadily infusing its database services with AI-driven capabilities to meet the needs of developers, business leaders, and data analysts. These enhancements range from built-in machine learning (ML) inside the database, to self-tuning and self-healing operations, to new features that support generative AI applications. The goal is to make databases not only faster and more scalable, but also smarter – improving performance, automating routine tasks, providing deeper analytics, and optimizing costs. This blog post provides a detailed look at Google Cloud’s database offerings in historical context, examines the recent AI-powered enhancements (spanning products like BigQuery, Cloud Spanner, AlloyDB, and more), and compares Google’s approach with similar advancements from AWS and Azure.
We will explore how Google Cloud’s integration of AI into its databases works and the benefits it brings in terms of performance, automation, analytics, and cost optimization. We’ll also review how these features stack up against Amazon Web Services (AWS) and Microsoft Azure – the other top cloud providers – as all three race to add AI capabilities to their database services. Two charts are included to illustrate key trends, and a comparison table summarizes the AI-powered database features across Google, AWS, and Azure. Let’s begin with a brief history of Google Cloud’s database services to understand the foundation on which these new AI features are built.
Evolution of Google Cloud’s Database Services
Google’s expertise in large-scale data management predates Google Cloud Platform (GCP) itself. Many of Google Cloud’s database technologies have roots in Google’s internal systems. For example, BigQuery, Google’s flagship analytics data warehouse, is built on Dremel, an internal query engine unveiled in 2010. BigQuery launched as a cloud service in 2011 and became generally available in 2012, offering fully managed, serverless analytics on massive datasets. From the start, BigQuery stood out for its ability to run SQL queries on trillions of rows with high performance, thanks to Google’s innovations under the hood. Over time, BigQuery expanded its feature set (adding support for standard SQL, federated queries, etc.), and notably in 2018 introduced BigQuery ML, bringing machine learning capabilities into the data warehouse so users could create and execute ML models using SQL commands. This was an early example of integrating AI with a cloud database – allowing analysts to perform predictive analytics without moving data to a separate ML platform.
In the realm of operational databases, Google Cloud initially provided Cloud SQL (a managed database-as-a-service for MySQL) around 2011, making it easier for developers to host relational databases on Google’s infrastructure. Support for PostgreSQL and SQL Server in Cloud SQL came later, turning it into a family of managed relational services. For non-relational needs, Google offered Cloud Datastore (a NoSQL document database derived from Google’s App Engine Datastore) and Cloud Bigtable, a petabyte-scale NoSQL database based on the Bigtable paper Google published in 2006. Cloud Bigtable became publicly available on GCP in 2015 as a fully managed NoSQL store for large analytical and IoT workloads, inheriting the scalability of the original Bigtable system. Similarly, Google’s internally famous distributed database Spanner – known for synchronizing data with TrueTime and the Paxos algorithm across data centers – was launched as Cloud Spanner on GCP in 2017. Cloud Spanner brought something unique: global strong consistency and horizontal scalability for relational data. It was born from Google’s F1 database (which replaced a sharded MySQL system for AdWords), and when Google offered Spanner to cloud customers in 2017, it introduced a “no-compromise” database that combined relational semantics with planet-scale distribution.
In 2017, Google also introduced Cloud Firestore, a schemaless NoSQL document database, as the successor to Datastore, targeting mobile and web app developers with real-time syncing features. By this time, GCP’s lineup included: Cloud SQL for managed MySQL/PostgreSQL, Cloud Spanner for global relational needs, Cloud Bigtable for wide-column NoSQL, Firestore for document data, and BigQuery for analytics. These offerings addressed a wide spectrum of use cases. Each had some degree of automation (for example, Cloud Spanner automatically handles replication and sharding across regions), but the integration of intelligent features was just beginning.
Fast forward to the 2020s, and cloud database services have become ever more sophisticated. Google launched AlloyDB for PostgreSQL in 2022 (with general availability in 2023) as a new fully managed relational database engine. AlloyDB is PostgreSQL-compatible but enhanced by Google to deliver higher performance – Google claims up to 4× faster throughput for transactional workloads and up to 100× faster analytical queries compared to standard PostgreSQL (figures from internal benchmarks). Under the hood, AlloyDB incorporates techniques like adaptive caching and fine-grained indexing, and it sets the stage for deeper AI integration in relational workloads.
Across this evolution, a clear pattern emerges: Google Cloud’s database services leveraged Google’s research innovations (BigQuery from Dremel, Spanner from F1/TrueTime, Bigtable from internal Bigtable, etc.) to offer differentiators in scale and consistency. Initially, these services focused on reliability, scalability, and ease of management (e.g. no-ops or serverless usage). However, as data volumes grew and use cases shifted to real-time analytics and AI, Google Cloud began embedding more machine learning and automation into its databases. Early steps included BigQuery ML for in-database ML modeling and Spanner’s automation of replication and splitting, but recent developments have greatly expanded the role of AI.
Today, Google Cloud’s databases not only store and retrieve data, but can also learn from workload patterns, recommend optimizations, automatically index or scale as needed, and enable advanced analytics like similarity searches and natural language queries. In the next section, we’ll delve into these AI-powered enhancements and how they work across Google’s database services, from analytics engines like BigQuery to operational databases like Spanner and AlloyDB.
AI-Powered Enhancements in Google Cloud Database Services
Google Cloud has introduced a range of AI-driven features across its database portfolio in the last couple of years. These enhancements are designed to improve performance, reduce manual administration, enable new types of queries (especially for AI/ML use cases), and optimize costs. Below, we highlight the key AI-powered features by category and product, explaining how they work and their benefits:
- Machine Learning Inside the Data Warehouse (BigQuery ML): Google BigQuery was an early adopter of built-in ML capabilities. BigQuery ML allows developers and analysts to create, train, and execute machine learning models using standard SQL queries, right within the data warehouse. For example, with a simple SQL command, one can train a regression model to forecast sales or a classification model to segment customers. The benefit is huge: it eliminates the need to move large datasets to external ML tools – the computation happens next to the data. This improves performance (by avoiding data export/import) and analytics capabilities (since analysts familiar with SQL can apply predictive models on their data directly). Over time, BigQuery ML has expanded to support a variety of model types (linear/logistic regression, XGBoost, deep neural networks via TensorFlow, even time-series forecasting and matrix factorization for recommendations) and can import/export models to TensorFlow or TensorFlow Lite. The result is a more automated analytics workflow, where building an ML model is as straightforward as writing a SQL query. BigQuery ML exemplifies how AI features can be embedded in a database service to empower users to do more with their data. (AWS and Azure have analogous capabilities – Amazon Redshift ML and Azure’s integration of ML in Synapse – which we’ll compare later.)
- AI for Performance Tuning and Autonomy: Managing and optimizing databases traditionally requires a lot of manual effort – e.g. creating indexes, tuning queries, configuring replicas, etc. Google Cloud is applying AI to make its databases more autonomous in this regard. A recent innovation is Database Center, an AI-powered unified management platform for Google Cloud databases. Introduced in 2024, Database Center uses machine learning to provide actionable recommendations for performance and reliability across a fleet of databases. It consolidates metrics from all your Google Cloud databases and can advise on things like index creation, query optimizations, or configuration changes to improve efficiency. This kind of AI-driven advisory service turns raw monitoring data into useful insights automatically, reducing the burden on database administrators. Another example is the use of AI in Cloud Spanner and Cloud SQL for automatic optimizations. Cloud Spanner, by design, already automates tasks like sharding (splitting data across servers) and replication. But Google has continued to refine Spanner’s performance using learned patterns from workloads. In late 2023, Google announced that Cloud Spanner received a 50% throughput increase (and 2.5× storage increase per node) with no price change, just from under-the-hood improvements. These improvements are delivered to customers automatically, a form of learned optimization at scale. Google highlighted that Spanner’s price-performance leap now makes it half the cost of Amazon DynamoDB for comparable workloads, showcasing how continuous AI-driven engineering can yield cost optimization benefits. Similarly, Cloud SQL (Google’s managed MySQL/PostgreSQL/SQL Server) now offers Query Insights and smart tuning recommendations that leverage Google’s analytic algorithms to detect slow queries and suggest indexes. While not branded as “AI,” these features often use heuristic learning from many customers’ workloads to identify common patterns and improvements – a crowdsourced intelligence, if you will. The result is more automation in administration, allowing developers and DBAs to rely on the cloud service to self-optimize.
- Generative AI and Natural Language Interfaces: One of the most exciting recent enhancements is the ability to interact with databases using natural language, powered by Google’s generative AI models. In 2024, Google previewed natural language querying in AlloyDB, and in 2025 it launched the next-generation of this capability. This feature, often termed AlloyDB AI’s natural language interface, allows developers (or even end-users of applications) to query data in AlloyDB by writing questions in plain English, which the system then translates into SQL securely and accurately. Under the hood, this uses large language models (LLMs) to interpret the user’s intent and generate the appropriate SQL, with context from the database schema and optionally additional instructions. Google emphasizes security in this process: developers can define which data is accessible via natural language queries using parameterized secure views, ensuring the AI only reveals authorized information. The AI also engages in interactive clarification if it’s unsure, rather than running a possibly incorrect query. The benefit of this natural language querying is increased productivity and accessibility – non-SQL experts can ask questions of their data, and developers can build AI-powered features (like a chatbot that answers questions from a database) without reinventing the wheel. Google is not alone in this trend – Microsoft Azure’s Power BI has a “Q&A” feature for natural language queries, and startups are building “ChatGPT for databases” – but Google baking it into AlloyDB indicates how core this is becoming. Another generative AI integration is Google’s Duet AI for Cloud, an AI assistant that helps with writing SQL queries, managing infrastructure as code, etc. For instance, Duet AI can suggest SQL commands in BigQuery’s UI or help generate schemas from examples. Though Duet AI spans more than just databases, it’s part of Google’s holistic approach to use generative AI as a co-pilot for developers on its platform.
- Vector Search and AI-Powered Data Retrieval: As AI applications like semantic search, recommendation engines, and chatbots that use embeddings (numerical representations of unstructured data) become widespread, databases are being extended to natively support vector data and similarity search. Google Cloud has made significant moves in this area. It introduced AlloyDB AI with vector search in 2024, enabling AlloyDB (a relational database) to store vectors and perform high-speed nearest neighbor searches on them – crucial for things like finding similar images or text embeddings. Google implemented a state-of-the-art vector indexing library called ScaNN (Scalable Nearest Neighbor) in AlloyDB, which is optimized for performance. According to Google, AlloyDB’s ScaNN index offers up to 10× faster vector search queries with filters compared to a popular alternative (the HNSW algorithm). This means AI-driven queries that combine vector similarity (e.g. “find items most similar in meaning to this document embedding”) with traditional SQL filters (e.g. “where category = 'Tech'”) run much faster, benefiting applications that mix unstructured and structured data. An example use-case is a recommendation system that matches user profiles (vectors) to content metadata (SQL filters). The performance boost directly translates to better user experiences (faster responses) and the ability to do more complex analysis in real-time – a big analytics win. After refining AlloyDB’s vector search (Google noted a 7× increase in adoption of this feature since launch), Google expanded vector search capabilities to its other databases. As of 2025, Bigtable, Cloud SQL, Firestore, Memorystore (Redis), and Cloud Spanner all support vector search in some form. In practice, this means whether you are using a document store (Firestore), a key-value store (Redis Memorystore), a wide-column NoSQL (Bigtable), or a relational DB (Spanner, AlloyDB, Cloud SQL PostgreSQL), you can now store embedding vectors and perform similarity queries directly in those services. This ubiquity is aimed at making Google Cloud a convenient platform for building AI applications – you can choose the database that fits your data model, and still get first-class vector search without introducing a separate vector database. It’s a blend of performance (optimized native execution) and automation (managing vector indexes for you) that reduces complexity for developers.
- AI-Driven Data Management and Integration: Google is also leveraging AI to simplify data integration and migration tasks, which can be costly and time-consuming for businesses. A noteworthy example is the use of generative AI in Database Migration Service (DMS). In 2024, Google announced that DMS (which helps migrate databases to Cloud SQL or AlloyDB) now supports SQL Server to PostgreSQL migrations with an AI-assisted conversion tool. This tool uses a combination of rule-based algorithms and a specially-trained Google Gemini model (Google’s family of advanced foundation models) to automatically convert database schema and business logic from Microsoft SQL Server (which uses T-SQL and proprietary types) to PostgreSQL equivalents. Traditionally, database migrations between engines involve a lot of manual fixes – for instance, translating T-SQL stored procedures to PL/pgSQL. By training an AI model on this problem, Google Cloud can automate the hardest parts of migration, saving organizations effort and reducing errors. This directly contributes to cost optimization, because it lowers the barrier to move off expensive legacy databases onto open-source based services like AlloyDB. Another integration-related tool is the Generative AI Toolbox for Databases that Google released as open source. This toolbox helps developers connect agent-based AI applications (think of complex workflows with multiple AI “agents” solving tasks) to Google Cloud databases in a secure and scalable way. It provides pre-built connectors and observability for databases like AlloyDB, Spanner, Cloud SQL, as well as open-source databases. Essentially, Google is acknowledging that modern AI applications may use multiple data stores and is offering AI-driven orchestration to manage those connections – ensuring that agents can discover and use data from various sources without custom glue code for each. This is more of an AI facilitator feature than the database engine itself doing something, but it’s part of the ecosystem.
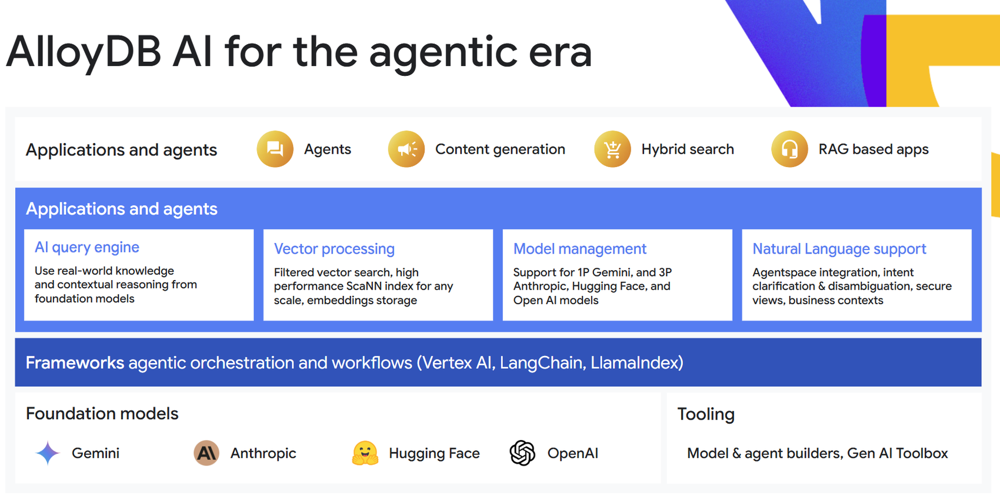
Figure 1: AlloyDB AI for the agentic era – a Google Cloud diagram highlighting new AI-driven features in AlloyDB, including an AI query engine (natural language to SQL using foundation models), vector processing with the high-performance ScaNN index, model management integrations (supporting Google’s Gemini and third-party models), and natural language support with intent clarification and secure views. These features enable developers to build intelligent applications (or “AI agents”) that can interact with AlloyDB using vectors and natural language, ushering in what Google calls the “agentic era” of applications.
The cumulative effect of these enhancements is that Google Cloud’s databases are becoming smarter and more versatile platforms. They can handle traditional transactions and analytical queries and power AI-driven workloads – often simultaneously. For example, an application can use Cloud Spanner as its system-of-record database and also leverage Spanner’s new vector search and graph query capabilities (now GA in 2025) to support, say, a recommendation feature or a knowledge graph traversal without moving data to a separate engine. Developers benefit from faster development (less infrastructure to stitch together) and better performance (since data stays in place and specialized indexes like ScaNN accelerate the heavy AI tasks). Businesses benefit through automation – fewer hours spent on tuning and maintenance – and cost savings by consolidating capabilities in one platform and using intelligent features to optimize resource usage. Google’s integration of AI also opens up new use cases, like building AI agents that use real-time database data. As Google Cloud’s GM of Databases Andi Gutmans noted, operational databases are now “powering new AI agents and multimodal applications, and enhancing existing applications with AI capabilities”, which is why Google is embedding gen AI technologies directly into its database services.
It’s worth mentioning that Google’s strategy involves not just adding AI within each individual database service, but also creating a unified data+AI experience. All these DB services tie into Google’s broader AI ecosystem (for instance, BigQuery can directly integrate with Vertex AI for model training, and AlloyDB’s vectors can be used by AI models in TensorFlow or JAX). Moreover, Google has ensured that these features are accessible via standard APIs and SQL so that the learning curve is minimal. In the next section, we’ll put Google Cloud’s approach in perspective by comparing it with what AWS and Azure are doing. This will help highlight similarities (all cloud providers are moving in this direction) and differences (each has a slightly different approach to marrying AI and databases).
Comparative Analysis: Google Cloud vs AWS vs Azure in AI-Powered Databases
All leading cloud providers recognize that AI and databases are a powerful combination, and they have been introducing their own AI enhancements in database services. However, there are some differences in focus and approach between Google Cloud, Amazon Web Services, and Microsoft Azure. Below, we compare how each of the “big three” cloud providers is infusing AI into their database offerings, looking at key features like automated tuning, integrated machine learning, support for vector search, and more.
Amazon Web Services (AWS): AWS has a wide array of database services (relational, NoSQL, analytical, graph, etc.) and has added AI capabilities to many of them, though often in a slightly different way than Google. For instance, AWS’s data warehouse Amazon Redshift introduced Redshift ML in 2021, which allows SQL users to create and train ML models on Redshift data. Redshift ML integrates with Amazon SageMaker (AWS’s ML platform) behind the scenes – when you issue a CREATE MODEL command in Redshift, it can spin up a SageMaker Autopilot job to train a model, then import the model into Redshift for in-database predictions. This is conceptually similar to BigQuery ML (bringing ML to the data) and provides the benefit of in-place analytics, though it relies on an external service for the heavy lifting. On the operational side, AWS offers Amazon Aurora, a high-performance relational database compatible with MySQL and PostgreSQL. Rather than embedding ML algorithms inside Aurora’s engine, AWS took an approach of tightly integrating Aurora with AI services. Amazon Aurora Machine Learning allows Aurora to call out to AWS AI services like Amazon Comprehend (for NLP) or Amazon SageMaker during SQL queries. For example, a user can run a SQL quey that uses a function to perform sentiment analysis on text stored in a table – under the hood, Aurora will send that text to Amazon Comprehend and return the result, all within the SQL query. This design lets developers enrich their data with AI insights without leaving the database context. AWS has recently expanded this with integrations to Amazon Bedrock (a service providing access to multiple foundation models for generative AI). In effect, AWS’s philosophy often is to keep the database stable and let it call specialized AI services on demand. The benefit is access to very advanced AI models (like Amazon’s Titan or third-party models via Bedrock) for any application using the database. The trade-off is that it may not feel as native as Google’s approach, and performance depends on network calls between the database and AI services.
AWS also emphasizes AI for DevOps and performance management. A notable service is Amazon DevOps Guru for RDS, which uses machine learning to automatically detect operational issues in Amazon RDS databases (which include Aurora, MySQL, Postgres etc.). It can identify anomalies like sudden spikes in read latency or CPU usage, correlate them with probable causes (e.g., a certain slow query or a configuration change), and even suggest remedial actions – essentially an AI ops tool for databases. This parallels Google’s Database Center recommendations, with AWS leveraging its expertise in monitoring and the huge telemetry data from RDS to train anomaly detection models. On the NoSQL side, AWS’s DynamoDB has an auto-scaling feature and capacity forecasting that could be considered AI-driven, though it’s largely policy-based (DynamoDB will increase throughput capacity if your usage hits certain thresholds). AWS has also brought AI to its graph database: Amazon Neptune ML (announced in late 2020) integrates graph neural network algorithms to make predictions on graph data (for example, predicting missing relationships or classifying nodes), using SageMaker to train those models. This is a specialized but powerful addition for graph analytics and demonstrates AWS’s approach of pairing a DB service with an AI service to extend its capability. For text search and vector search, AWS has chosen to offer separate services like Amazon Kendra (an AI-powered enterprise search) and added vector search to OpenSearch (their Elasticsearch-derived service). As of 2023, Amazon OpenSearch Service supports vector embeddings and kNN search for similarity, which developers can use alongside their traditional full-text search. Additionally, Amazon Athena (interactive query service) and AWS Glue (data integration) have started to incorporate ML for data cleansing and anomaly detection in datasets.
Microsoft Azure: Microsoft’s strategy with Azure databases has been heavily focused on what they call “SQL Intelligence” – building autonomous features into the core relational database offerings. Azure SQL Database, the fully managed cloud version of SQL Server, has had built-in intelligence for many years. It can learn the patterns of your application’s workload and adapt to maximize performance. Concretely, Azure SQL’s automatic tuning feature will automatically create, drop, or reorganize indexes based on usage patterns, and automatically fix query plan regressions by forcing last-known-good plans if a new plan performs worse. Microsoft reported that this can lead to significant and continual performance gains without human intervention. The database observes query performance, identifies indexes that would help, creates them, and later drops them if they are not beneficial – all autonomously. This is a clear parallel to Google’s self-driving efforts, though Microsoft was one of the first to do it at scale in a commercial cloud DB. Azure SQL’s Intelligent Insights feature similarly monitors databases and detects anomalies or incidents (e.g., “wait times on IO have increased 30% due to X query”), providing diagnostics to developers. These features use a mix of heuristics and machine learning models trained on telemetry from millions of databases running on Azure, giving Azure a strong story on automation and performance optimization via AI.
On the analytics side, Azure’s answer to BigQuery and Redshift is Azure Synapse Analytics (formerly SQL Data Warehouse). Synapse integrates with Azure Machine Learning and Azure Cognitive Services. While Synapse itself can execute ML models (for example via the PREDICT T-SQL function that applies a machine learning model to your result set), Microsoft often highlights using Spark within Synapse or sending data to Azure ML notebooks for advanced ML tasks. However, Microsoft has a unique asset: Azure OpenAI Service, which provides API access to OpenAI’s GPT-4, GPT-3, etc., with enterprise security. Microsoft has been rapidly integrating this into its data stack – for example, Power BI (their BI tool) features an AI assistant (Power BI Copilot) that can generate visuals and insights from natural language questions, some of which ultimately translate to SQL against Synapse or other databases. In databases directly, Microsoft introduced previews of natural language to SQL capabilities as well, leveraging GPT. We can expect Azure to soon allow developers to query Cosmos DB or Azure SQL by simply asking in natural language, similar to AlloyDB’s capability, given Microsoft’s heavy investment in generative AI and Copilot experiences. Additionally, Azure’s Cosmos DB (a multi-model NoSQL database) now offers an autopilot mode for throughput and had early features like Built-in Jupyter notebooks for machine learning experimentation on data, and integration of Cognitive Search (which itself now supports vector search) with Cosmos DB for AI-driven search scenarios.
One more area of differentiation: Microsoft’s embrace of graph and time-series within its cloud databases with intelligent features. Azure Cosmos DB’s Gremlin API allows graph queries, and while it doesn’t have a dedicated ML feature like Neptune ML yet, Microsoft research in embeddings for graph data could roll in. Meanwhile, Azure SQL Edge (for IoT) even has on-device ML support for time-series analysis. Microsoft, like Google, also provides a unified management view called Azure SQL Insights and advisors that use AI to guide optimizations across databases.
In summary, all three providers are converging on a set of AI-enhanced database capabilities: in-place machine learning, automated performance tuning, anomaly detection, natural language interfaces, and vector similarity search to support AI applications. The approach differs: Google tends to bake these capabilities inside the database engines (e.g. AlloyDB’s native vector search, BigQuery’s native ML, Spanner’s native multi-model queries), whereas AWS often integrates the database with external AI services (Aurora calling SageMaker/Comprehend, Redshift offloading training to SageMaker). Azure is somewhat in between, with a strong focus on autonomous database operations and leveraging its OpenAI partnership for new experiences.
The benefit for customers is that regardless of cloud, databases are becoming smarter and easier to manage. But the differences might affect architecture choices: for example, if you want a one-stop-shop database that can do vector search and graph queries on transactional data, Google’s Spanner with its new features or AlloyDB might simplify your stack. If you prefer to use best-of-breed AI services alongside a lean database, AWS’s approach might suit you (though it may involve more moving parts). Azure’s long experience with self-tuning can be attractive if you want a lot of hands-off management in a traditional relational database.
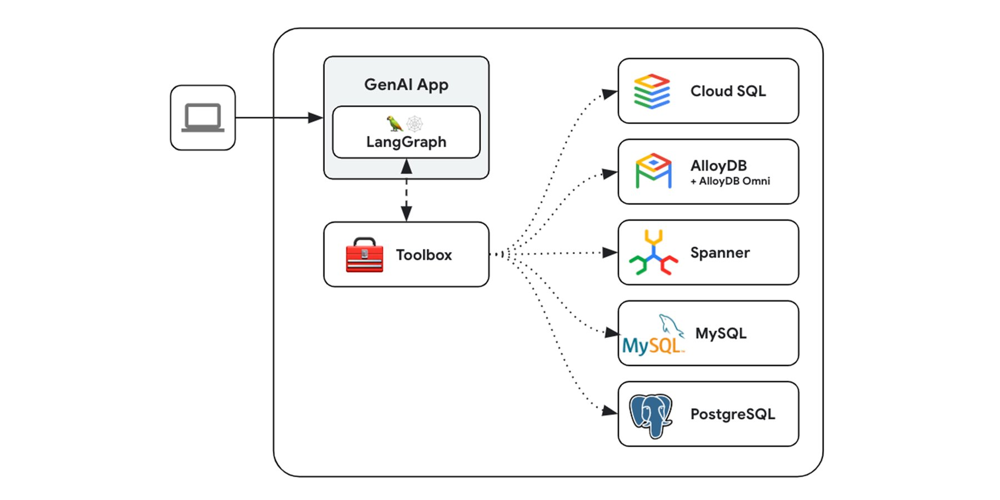
Figure 2: An example architecture (from Google’s GenAI Toolbox for Databases) showing how a generative AI application can connect to multiple databases through a “Toolbox” layer. In this diagram, an AI app (which could be using a framework like LangChain) sends queries to the Toolbox, which then securely interfaces with various databases – Cloud SQL, AlloyDB, Spanner, MySQL, PostgreSQL, etc. – to retrieve or modify data. This kind of tooling illustrates how cloud providers are enabling AI agents to seamlessly interact with enterprise data across different storage engines. By integrating vector search and natural language capabilities into databases, and providing connectors like this, Google Cloud (and similarly Azure and AWS) help developers build AI-driven workflows that can reason over real-time database information, not just static data.
Conclusion
The infusion of artificial intelligence into cloud database services represents a significant shift in how we manage and derive value from data. Google Cloud’s recent enhancements – from BigQuery’s in-situ machine learning and AlloyDB’s AI-driven query processing, to Spanner’s autonomous operations and vector search across databases – demonstrate a clear commitment to making data infrastructure smarter. These AI features are not just gimmicks; they address real needs by improving performance (e.g. faster similarity searches and optimized queries), increasing automation (self-tuning and anomaly detection), enriching analytics (built-in ML and natural language querying), and driving cost optimization (reducing manual labor and making existing services more efficient). For developers and businesses on Google Cloud, this means faster development cycles (less tweaking, more building) and the ability to incorporate advanced AI functionalities into applications without managing complex pipelines or additional systems.
Comparatively, AWS and Azure are on parallel journeys, each leveraging their strengths – AWS tying in its rich AI/ML ecosystem, and Azure leaning on its decades of database optimization experience and OpenAI collaboration. This competition is beneficial for customers, as it pushes all providers to innovate. Five years ago, the idea of a database service that could understand a natural language question or automatically transform your schema using an AI model might have sounded futuristic. Today, those are real features either already available or on the near horizon.
Looking forward, we can expect even deeper integration of AI in database services. Possible future directions include: fully autonomous databases that repair and optimize themselves in real-time (beyond the current indexing and tuning capabilities), more widespread use of AI for query optimization (the SQL query planner could use machine learning to choose better execution plans), and richer multi-modal queries (e.g., a single query that can join a SQL table with the results of an ML model or a vector search seamlessly). We might also see AI helping with data governance – e.g., automatically detecting sensitive data or suggesting data quality improvements. And as foundation models get more sophisticated, the line between databases and AI will blur further: we might “query” an LLM and a database in one breath, and the cloud platform will orchestrate the best way to get the answer, whether from stored data or AI reasoning.
For developers, the key takeaway is that cloud databases are no longer passive data stores – they are becoming active participants in data processing and insight generation. Embracing these AI features can lead to simpler architectures (since you can do more within the managed service) and more powerful applications (since you can offer end-users intelligent features with relative ease). For business leaders, the convergence of AI and databases means the data platforms you invest in can directly contribute to AI initiatives like predictive analytics, personalization, and automation, often with lower total cost of ownership due to the efficiency gains.
Google Cloud’s enhancements showcase how a unified strategy of blending operational data with AI can “supercharge the AI developer experience”, as their executives put it. And in doing so, Google is positioning its cloud not just as a place to store data, but as the place where data becomes insight and action. The same is true of its rivals – each wants to be the go-to platform for intelligent applications.
In conclusion, the evolution of database services with AI is transforming the industry. Cloud databases are getting smarter, faster, and more user-friendly. Whether you choose Google, AWS, or Azure, the message is clear: the future of data management is inextricably linked with AI. By harnessing these new capabilities, organizations can unlock more value from their data with less effort, ushering in a new era of intelligent data-driven applications. It’s an exciting time to be both a database enthusiast and an AI practitioner, as these technologies converge to open up possibilities we could only hint at just a few years ago.
References
- Google Cloud Blog – Introducing AlloyDB AI: A New Era for AI-Enabled Applications
https://cloud.google.com/blog/products/databases/introducing-alloydb-ai - Google Cloud Documentation – BigQuery ML Overview
https://cloud.google.com/bigquery-ml/docs/introduction - Google Cloud Blog – Cloud Spanner: Performance Enhancements and Price Reductions
https://cloud.google.com/blog/products/databases/cloud-spanner-performance-and-price-enhancements - Google Cloud – Database Center Overview
https://cloud.google.com/database-center - Google Cloud Blog – Vector Search Now Available Across Google Cloud Databases
https://cloud.google.com/blog/products/databases/vector-search-now-available-in-google-cloud-databases - AWS Documentation – Amazon Aurora Machine Learning
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-machine-learning.html - AWS Blog – Redshift ML: Create, Train, and Deploy ML Models Using SQL
https://aws.amazon.com/blogs/big-data/use-amazon-redshift-ml-to-create-train-and-deploy-machine-learning-models-using-sql/ - Microsoft Azure – Built-in Intelligence in Azure SQL Database
https://learn.microsoft.com/en-us/azure/azure-sql/database/intelligent-performance-overview - Microsoft Azure Blog – Power BI Copilot and Natural Language Querying
https://techcommunity.microsoft.com/t5/power-bi-blog/introducing-power-bi-copilot-your-ai-powered-data-assistant/ba-p/3771515 - Google Cloud GitHub – Generative AI Toolbox for Databases
https://github.com/GoogleCloudPlatform/generative-ai-toolbox-for-databases