
Reddit vs. Anthropic—The Legal Battle Over AI and User Data

In the ever-evolving landscape of artificial intelligence, a new chapter has emerged that could shape the future of data rights and corporate accountability. On June 4, 2025, Reddit, the popular user-generated content platform, filed a high-profile lawsuit against Anthropic, the AI research firm behind the Claude family of large language models. The crux of the legal complaint centers on accusations that Anthropic exploited Reddit’s vast troves of user data—without authorization—to train and improve its generative AI models.
Reddit’s lawsuit is not occurring in isolation. It is part of a broader reckoning between digital platforms that host vast user interactions and AI developers who rely on large, diverse datasets to fuel their models. This conflict touches on multiple critical issues: the legality of scraping public web data, the ethics of using user-generated content without explicit consent, the future of data licensing, and the responsibilities that AI firms bear in respecting digital platform terms of service.
What makes this case particularly compelling is the growing value of Reddit’s data in the AI race. Reddit’s forums, known as “subreddits,” span virtually every conceivable topic and are rich in human conversation, reasoning, and opinion. Such content is a goldmine for training chatbots and LLMs to sound natural, persuasive, and context-aware. As large language models increasingly depend on nuanced human discourse to improve performance, Reddit’s data has become more than a digital archive—it’s become intellectual capital.
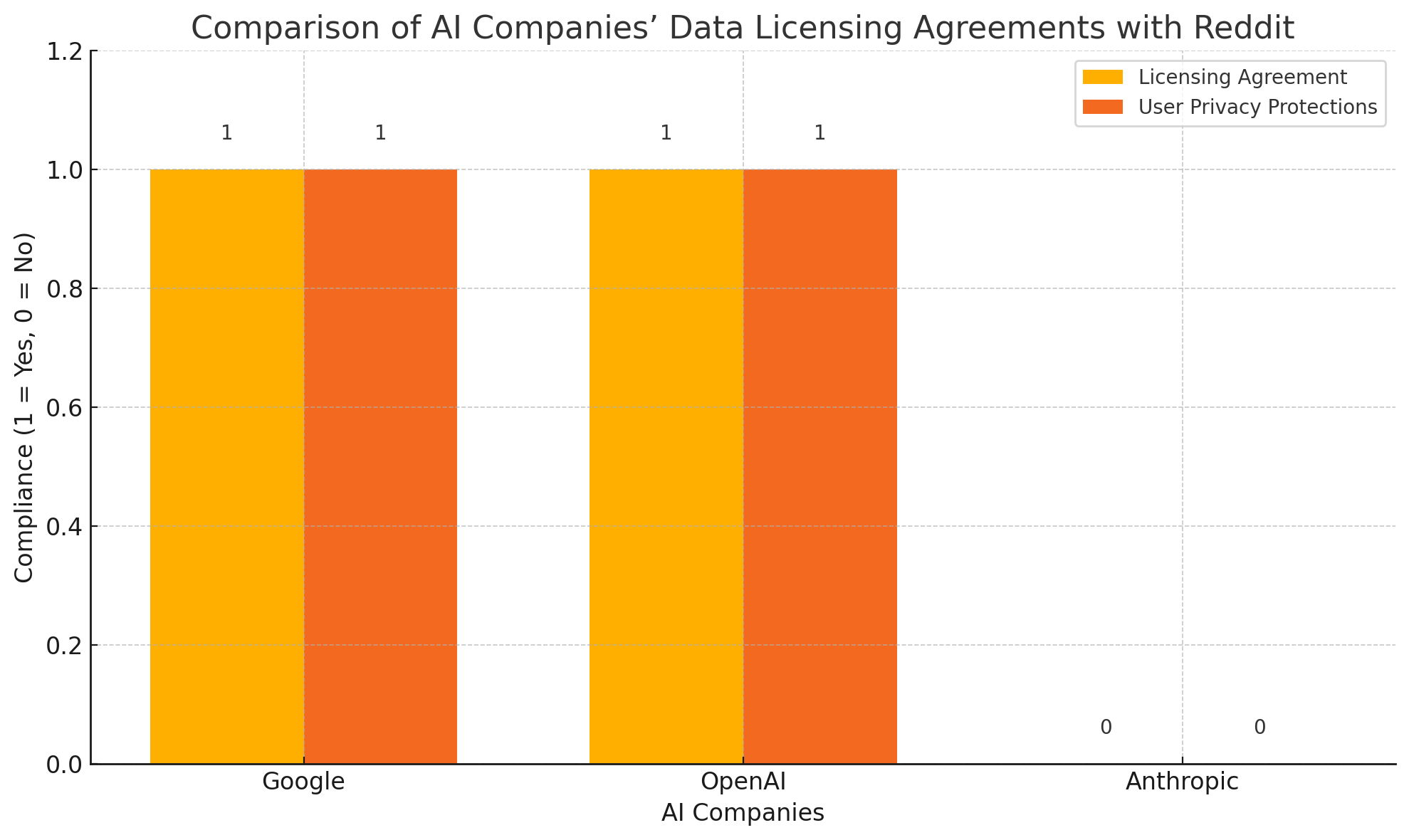
In its filing, Reddit claims that Anthropic performed over 100,000 automated data requests against Reddit’s servers beginning in mid-2024. These requests, Reddit argues, constituted repeated and systematic scraping in violation of the platform’s robot exclusion protocols and its updated terms of service. Crucially, Reddit alleges that Anthropic failed to engage in licensing negotiations, unlike other AI firms such as Google and OpenAI, which secured data partnerships with Reddit earlier in the year. Anthropic’s alleged refusal to comply with Reddit’s usage policies or pursue a formal agreement, Reddit asserts, gives rise to claims of unjust enrichment, breach of contract, and unfair competition.
Anthropic, for its part, has responded publicly with a measured denial. The company states that its AI models are trained on “a broad range of data sources, including publicly available materials and licensed content.” It maintains that it operates within the bounds of fair use and current industry standards for AI training data. While the company has not commented directly on Reddit’s allegations, it has indicated an intention to contest the claims vigorously in court.
This legal confrontation between Reddit and Anthropic comes at a particularly sensitive time in the AI industry. As the generative AI boom continues to escalate, regulatory scrutiny has intensified globally. Lawmakers in the U.S., European Union, and China are actively drafting legislation to define how companies may collect, store, and process data—especially data used to train AI systems. Against this regulatory backdrop, legal actions like Reddit’s may serve as de facto benchmarks, influencing future policy decisions and corporate behavior.
Moreover, the Reddit-Anthropic lawsuit has major implications for users. At the heart of Reddit’s complaint is the concern that Anthropic’s data scraping may have involved not only public posts but potentially deleted content or private information stored in metadata. This raises serious questions about user consent, data permanence, and digital privacy. If Reddit prevails, the precedent could empower other platforms—and by extension, their users—to demand compensation and safeguards when AI companies mine their content. If Anthropic succeeds, it could legitimize widespread scraping of publicly available internet content, so long as it is not explicitly restricted or protected by copyright.
This case is also emblematic of the monetization strategies now being adopted by previously open platforms. Reddit, like many others, has begun transforming its content archive into a revenue-generating asset by licensing data to AI developers. While this move has generated new income streams, it has also triggered backlash from users who believe their unpaid contributions are being commercialized without their consent. The Reddit-Anthropic dispute shines a spotlight on this tension between platform monetization and user rights—particularly as content from online communities becomes foundational training material for generative AI systems.
Beyond legal ramifications, the lawsuit signals a critical inflection point in how the tech industry approaches the use of user-generated content. It raises fundamental questions: Who owns internet discourse? Is public data on social platforms truly free to use for commercial AI training? Can platform policies override the assumption that anything posted publicly is fair game? These questions are increasingly urgent as more AI companies scramble for high-quality datasets to maintain competitive advantage.
Over the course of this blog post, we will dissect the Reddit-Anthropic case across four major dimensions. First, we will explore the core legal allegations and Reddit’s detailed complaint. Then, we will compare this case with other AI firms’ licensing deals to contextualize Anthropic’s approach within broader industry norms. Next, we will assess the ethical and legal implications of using public data to train AI, particularly in terms of user privacy and digital consent. Finally, we will conclude with an examination of the case’s potential outcomes and their long-term impact on AI development, data governance, and digital content platforms.
The stakes are high. With billions invested in AI development and billions of users generating data daily, the boundaries between fair use, intellectual property, and personal privacy are increasingly blurred. Reddit’s lawsuit against Anthropic may very well help define those boundaries, shaping the rules of engagement for an industry racing ahead of regulation.
The Core Allegations: Reddit's Claims Against Anthropic
The lawsuit filed by Reddit against Anthropic marks a pivotal moment in the ongoing debate over the boundaries of data usage and AI model training. At its center are a series of legal claims rooted in the unauthorized extraction and utilization of Reddit’s user-generated content. Reddit contends that Anthropic’s actions not only violated contractual and technological protections, but also constituted a fundamental breach of digital ethics and commercial fairness.
Systematic Data Scraping at Scale
The foundation of Reddit’s complaint lies in what it describes as a “massive and unauthorized data scraping operation.” According to the lawsuit, Anthropic began a systematic campaign to extract data from Reddit’s servers starting in July 2024, using automated means—known as web crawlers or bots—to conduct more than 100,000 separate requests. Reddit claims these activities directly contravened the site’s robots.txt protocols, which are intended to communicate with web crawlers about which areas of the site can and cannot be accessed or indexed.
Reddit argues that Anthropic disregarded these protocols and instead circumvented technological safeguards to harvest a significant volume of content across thousands of subreddit communities. These included posts, comments, discussions, upvote/downvote patterns, and potentially even metadata associated with user behavior. This data, Reddit asserts, was then fed into Anthropic’s large language models (LLMs)—particularly the Claude series—without authorization, compensation, or user consent.
Importantly, Reddit maintains that this activity was not incidental or accidental but instead a deliberate and continuous effort to build Anthropic’s commercial product offering. The complaint outlines server logs and technical analysis suggesting consistent IP-based scraping activity originating from infrastructure associated with Anthropic or its affiliates. Reddit characterizes this as “industrial-scale extraction of proprietary conversational content.”
Breach of Reddit’s API Terms and User Agreement
Beyond technical violations, Reddit’s legal argument emphasizes contractual breaches. In April 2023, Reddit instituted a revised data access policy requiring third-party entities to license data through its paid Application Programming Interface (API). These changes were part of Reddit’s broader strategic pivot toward monetizing its content in the face of growing demand from AI companies seeking rich, real-world data sources for model training.
Reddit contends that Anthropic refused to comply with these revised API terms, choosing instead to exploit legacy access mechanisms or direct scraping rather than paying for an official license. This, the lawsuit argues, constitutes a breach of Reddit’s Developer Terms of Service, as well as a violation of its broader User Agreement. Reddit emphasizes that its terms explicitly prohibit the reproduction, republication, or commercial exploitation of its platform’s content without permission.
The lawsuit further claims that Anthropic had ample opportunity to enter into good-faith negotiations with Reddit, as other leading AI firms—most notably OpenAI and Google—had already done. According to internal correspondence cited in the filing, Reddit had attempted to reach out to Anthropic for licensing discussions in early 2024 but was either ignored or rebuffed. Reddit alleges that Anthropic made a calculated business decision to bypass licensing in order to save costs and accelerate model development.
Claims of Unjust Enrichment and Commercial Exploitation
Reddit’s complaint goes beyond alleging procedural violations to assert that Anthropic has been unjustly enriched through its use of Reddit’s content. Specifically, the platform argues that Anthropic’s Claude models derive measurable benefit—financial and technological—from training on Reddit’s data. The performance of large language models is significantly influenced by the diversity, quality, and context of the text used during training. Reddit’s forums, with their lively debates, long-form answers, and rich interaction structures, are considered especially valuable for developing models that simulate human-like reasoning and dialogue.
By incorporating this data into Claude, Reddit asserts, Anthropic has gained a competitive edge in the AI marketplace without paying for the underlying resource. This amounts to “commercial exploitation of digital labor,” Reddit claims—referring to the unpaid contributions of its users who generated the content being repurposed. Reddit positions itself as the steward of that collective digital asset and insists that it must be compensated for the role it plays in creating and curating one of the internet’s most content-rich ecosystems.
In legal terms, Reddit accuses Anthropic of unjust enrichment, a common law doctrine that applies when one party benefits at the expense of another in a manner deemed inequitable. The lawsuit calls for disgorgement of profits derived from the use of Reddit data and demands both compensatory and punitive damages.
Potential Exposure of Private or Deleted Content
One of the more concerning dimensions of the complaint is Reddit’s claim that Anthropic may have accessed data not meant for public consumption, including deleted posts, edited comments, or content behind user-specific privacy settings. Although not substantiated with direct forensic evidence at this stage, Reddit raises the issue as part of its broader claim of harm, suggesting that indiscriminate scraping may have bypassed protections designed to shield such data.
This raises serious implications for user trust and data permanence. Unlike static websites, Reddit is a dynamic and interactive platform where users often revisit and revise content, and where the visibility of certain data is managed through community rules or privacy settings. Reddit argues that if Anthropic’s scraping infrastructure did not distinguish between visible and restricted content, it may have inadvertently ingested sensitive user information—information that was not only unlicensed but also potentially subject to data protection regulations such as the GDPR or CCPA.
Although Anthropic has denied any wrongdoing, Reddit’s emphasis on this point is likely a strategic legal maneuver to expand the scope of potential damages and introduce questions of digital privacy into the litigation. If courts find that private or non-public data was accessed and used in model training, the legal consequences for Anthropic could extend far beyond mere breach of terms—they could include violations of data privacy laws and platform liability doctrines.
Reddit’s Strategic Positioning in the AI Economy
Another underlying theme of Reddit’s complaint is the company’s assertion of its own relevance and control over its data assets. As one of the few major social platforms that has remained largely text-based, Reddit occupies a unique role in the modern AI ecosystem. Its user-generated content provides not only linguistic variety but also real-time cultural insight, making it invaluable for training models that are conversationally aware and socially calibrated.
By framing Anthropic’s actions as a challenge to its economic model, Reddit positions itself not merely as a victim but as a legitimate stakeholder in the AI economy. The platform argues that it has the right to choose how and with whom its data is shared and monetized. The lawsuit thus becomes as much about defending platform sovereignty as it is about enforcing terms of service. It is a declaration that Reddit intends to assert ownership over the digital discourse it hosts and ensure it is not commoditized without consent.
Licensing Deals and Industry Practices: A Comparative Perspective
As the Reddit-Anthropic legal dispute unfolds, it is critical to evaluate the broader industry context in which this lawsuit resides. The controversy is not occurring in a vacuum; rather, it sits at the center of a growing debate around the norms, standards, and expectations governing how large language model (LLM) developers source the data used to train their AI systems. This section explores the nature of licensing deals between platforms and AI firms, contrasts Reddit’s proactive approach with Anthropic’s alleged conduct, and situates the case within evolving industry practices.
The Emergence of Data Licensing as a Monetization Strategy
Over the past two years, platforms with extensive repositories of user-generated content have begun to recognize the commercial potential of their datasets. As AI models grew increasingly dependent on large-scale corpora of human language to improve performance, companies like Reddit, Stack Overflow, Tumblr, and X (formerly Twitter) moved to monetize their content archives through data licensing agreements. These deals allow AI developers to legally access structured, high-quality text while ensuring that content platforms receive compensation and retain a degree of oversight.
Reddit, in particular, has been among the most aggressive in this regard. In early 2024, it announced major licensing partnerships with both Google and OpenAI, reportedly worth $60 million annually. These agreements grant the AI firms access to Reddit’s public data via its commercial API, under terms that are designed to safeguard user anonymity, respect privacy constraints, and comply with evolving content usage policies. Importantly, these deals include contractual obligations that prohibit the collection of deleted or private data and incorporate provisions for auditing, revocation, and content use transparency.
By formalizing these arrangements, Reddit not only unlocked a new revenue stream but also positioned itself as a key gatekeeper in the AI ecosystem. The company now maintains tight control over how its platform’s content is accessed and used, insisting that all parties—regardless of size or intent—must adhere to its licensing framework.
Anthropic’s Divergence: Refusal to License and Alleged Circumvention
In contrast to Reddit’s licensing partners, Anthropic is accused of taking a markedly different approach—one that Reddit characterizes as both evasive and exploitative. According to the complaint, Anthropic never sought to negotiate a licensing agreement, even after Reddit publicly revised its terms of service and introduced a formal API monetization model. Instead, Reddit asserts that Anthropic chose to bypass these mechanisms altogether, opting to scrape content directly and at scale.
This alleged refusal to engage in licensing negotiations is one of the core differentiators in the lawsuit. Where OpenAI and Google recognized the need for legal and ethical compliance and entered into partnerships that acknowledged Reddit’s intellectual property rights, Anthropic is portrayed as having attempted to exploit publicly accessible data under a broad and informal interpretation of “fair use.”
Anthropic’s public statements suggest that it sources its training data from “a mixture of licensed, public, and open-source materials,” without providing specific details. This level of opacity stands in contrast to the detailed transparency reports issued by other AI leaders, which often disclose data sources, usage rationale, and steps taken to mitigate privacy or copyright risks.
If Reddit’s claims are substantiated, the implication is that Anthropic not only failed to license the content but also willfully circumvented the commercial framework Reddit had put in place—a move that, if left unchallenged, could undermine industry efforts to normalize ethical data procurement standards.
Industry Norms: Growing Momentum for Structured Agreements
The AI industry is undergoing a shift toward formalized content sourcing. This trend is partly a reaction to regulatory pressure, including the European Union’s AI Act, the Digital Markets Act, and a series of copyright infringement cases in the United States and United Kingdom. These regulations and legal precedents are prompting AI firms to reevaluate their data collection strategies and move away from informal scraping toward structured, permission-based access.
In addition to Reddit’s licensing deals, notable examples include:
- Stack Overflow & OpenAI: In March 2025, Stack Overflow signed a multi-year agreement with OpenAI to allow the use of its question-answer data for LLM training while receiving attribution and financial compensation.
- Midjourney & Shutterstock: Image-generating AI firm Midjourney now sources training data exclusively from licensed image platforms like Shutterstock, following a wave of copyright lawsuits.
- YouTube & Google DeepMind: Although both owned by Alphabet, YouTube and DeepMind have established internal data use protocols to comply with content creator rights and data protection laws.
These partnerships are illustrative of a growing consensus that access to high-quality data must be negotiated, not assumed. Consent, attribution, and compensation are becoming core pillars of responsible AI development.
Legal and Commercial Implications of Licensing Divergence
The Reddit-Anthropic case puts a spotlight on the risks faced by AI firms that eschew licensing. From a legal standpoint, scraping protected content in defiance of terms of service can give rise to claims of breach of contract, unfair competition, unjust enrichment, and even violations of anti-hacking statutes such as the U.S. Computer Fraud and Abuse Act (CFAA). Commercially, the reputational damage from being portrayed as a non-compliant actor may deter investors, partners, and customers who are increasingly attuned to AI ethics and governance.
Conversely, companies that embrace licensing gain not only legal cover but also potential brand advantages. Partnerships with platforms confer legitimacy and trustworthiness, helping to distinguish responsible AI development from practices that may be perceived as extractive or opportunistic. As public discourse around AI transparency grows more intense, firms seen as playing by the rules are more likely to gain regulatory goodwill and long-term user acceptance.
Data Licensing as a Competitive Differentiator
Beyond legal safety, licensing agreements can serve as competitive differentiators in the AI market. Firms with access to unique and high-fidelity datasets—whether through licensing Reddit’s nuanced conversations or Stack Overflow’s technical exchanges—can train more capable and context-aware models. These advantages may translate directly into market share, product quality, and monetization opportunities.
Reddit’s willingness to enter into high-value data licensing deals shows its recognition of this dynamic. By suing Anthropic, Reddit is not merely defending its intellectual property; it is also signaling to the AI industry that its data is a premium resource—not a free commodity. The lawsuit reinforces Reddit’s position as a data licensor and may prompt other platforms to follow suit, especially as competition intensifies and proprietary content becomes a prized input in AI innovation.
Broader Implications: AI Ethics, Data Privacy, and Legal Precedents
The legal dispute between Reddit and Anthropic extends far beyond a binary disagreement over licensing fees or contractual compliance. It represents a flashpoint in the broader conversation surrounding AI ethics, data governance, digital rights, and the responsibilities of technology companies operating in the generative AI space. The outcome of this case, and the arguments it presents, could significantly influence not only how AI developers interact with user-generated content (UGC) platforms, but also how governments and regulatory bodies frame future laws around AI training data and online privacy.
Reframing the Ethics of Data Usage in AI Training
At its core, the Reddit-Anthropic lawsuit raises an ethical dilemma: should AI companies be allowed to use publicly accessible data without consent if it was not explicitly posted for that purpose? The boundaries of what constitutes “public” and “permissible” in the context of web-based data have always been murky. However, with the rise of LLMs that ingest and replicate massive quantities of online dialogue, the stakes have escalated.
Reddit’s argument challenges the implicit assumption that public availability equals ethical or legal usability. By asserting that Anthropic’s actions amounted to a “digital expropriation” of its content and the unpaid labor of its users, Reddit is pushing back against a data economy model that prioritizes technical accessibility over ethical consideration. This stance aligns with a growing school of thought in the AI ethics community, which posits that context and consent must play a central role in determining the legitimacy of data sourcing practices.
For example, a Reddit user may willingly share a personal story or opinion on a public subreddit for community discussion, not for AI ingestion. When this content is scraped, repackaged, and potentially reproduced by a chatbot like Claude, users may feel their intent and privacy have been violated—even if no direct legal boundaries were breached. The ethical implication is clear: AI companies need to reckon with the spirit, not just the letter, of content usage.
Data Privacy: Blurring the Line Between Public and Private
Closely tied to these ethical concerns are the evolving standards around data privacy. Reddit’s claim that Anthropic may have scraped not just visible content, but also edited or deleted posts, introduces a troubling possibility—that LLMs could be trained on content that users intended to retract. Whether or not this allegation can be substantiated, it speaks to a larger concern: AI systems, if indiscriminately trained on dynamic platforms, may become repositories for data that was never meant to persist.
This has significant implications in jurisdictions governed by strict privacy legislation, such as the European Union’s General Data Protection Regulation (GDPR) or California’s Consumer Privacy Act (CCPA). Under these laws, individuals have the right to delete personal data and limit how it is processed. If AI companies train models on content that users later erase, they may inadvertently create irreversible data retention scenarios, potentially putting them at odds with regulatory mandates.
Furthermore, privacy is no longer solely about identifiable information. Behavioral patterns, emotional expressions, political beliefs, and medical disclosures shared in Reddit threads—though often pseudonymous—can be revealing in aggregate. AI models trained on such content, even in de-identified form, may still propagate sensitive or controversial views, raising concerns about bias, discrimination, and manipulation.
In this context, Reddit’s lawsuit may be viewed not just as a commercial protection effort, but as a privacy advocacy move—one that demands a more nuanced understanding of how AI intersects with personal expression online.
Legal Precedents: Defining Boundaries for AI Development
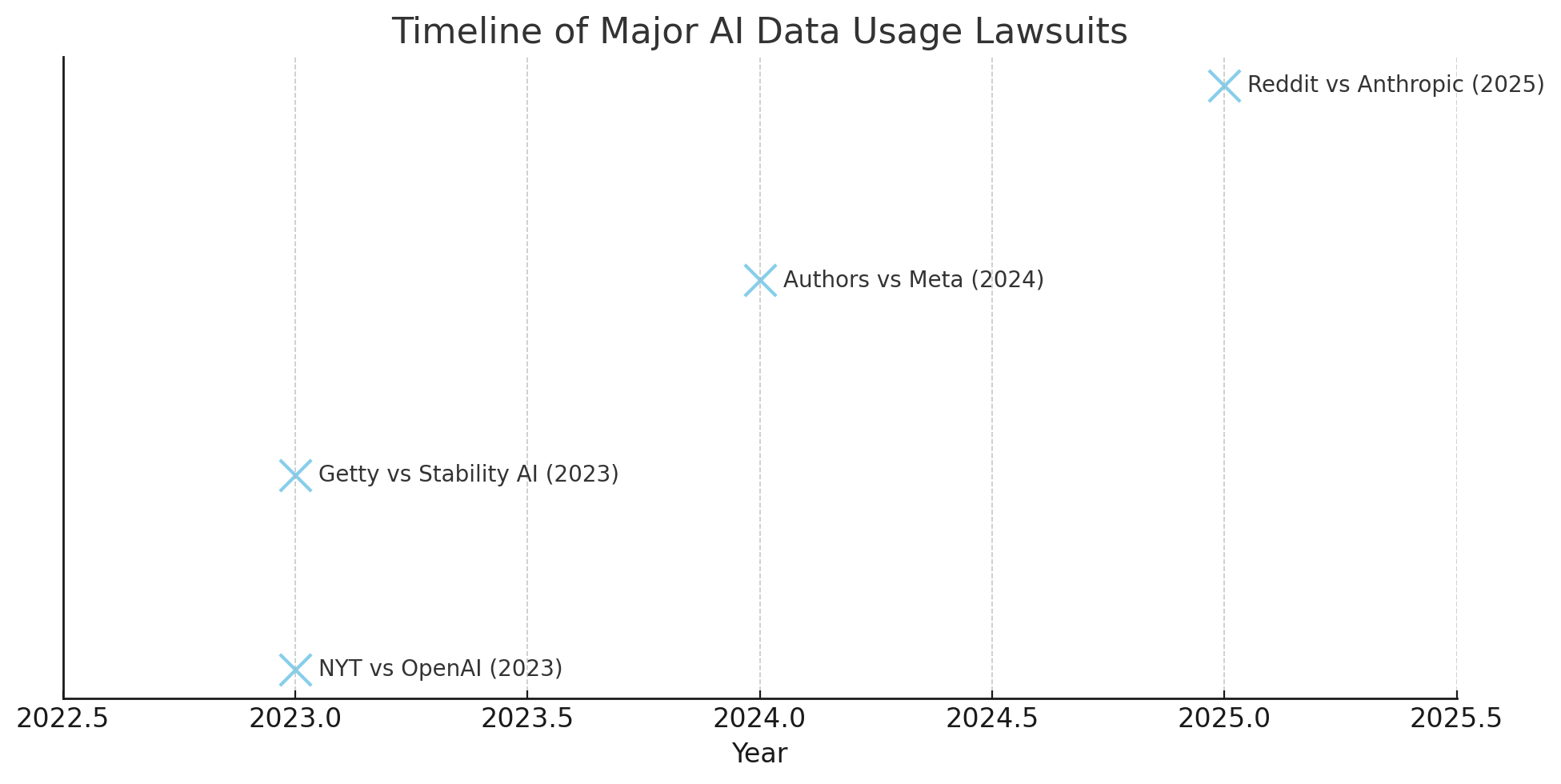
Legally, Reddit’s case marks a departure from many prior lawsuits involving AI data usage. Most prominent cases to date—such as those filed by publishers against OpenAI and Stability AI—have focused on copyright infringement, often involving creative works like books, news articles, or images. Reddit’s action, however, is rooted in breach of contract, violation of terms of service, and unfair competition.
This shift is significant. By focusing on platform policies rather than IP law, Reddit is broadening the legal playbook available to content hosts seeking to restrict AI usage of their data. If the court sides with Reddit, it could set a precedent affirming that online platforms have the right to enforce API access conditions and prohibit scraping—regardless of whether the data is copyrighted. This would empower companies to assert contractual control over their digital ecosystems, and simultaneously discourage AI developers from bypassing platform rules under the guise of “public domain.”
Such a ruling could also reshape the technical norms of AI development. Developers may be forced to abandon indiscriminate scraping in favor of verified data partnerships, potentially increasing training costs but improving legal defensibility. Alternatively, firms may shift toward synthetic data or user-contributed datasets with clear consent trails, prompting innovation in data generation rather than extraction.
Industry Self-Regulation vs. Government Oversight
The lawsuit also raises questions about the appropriate balance between industry self-regulation and government intervention. To date, much of the AI sector has operated in a largely unregulated environment, where best practices are informal and compliance is voluntary. However, as disputes like Reddit vs. Anthropic become more frequent—and more public—pressure is mounting for governments to step in.
Reddit’s case could accelerate legislative interest in establishing clear data usage guidelines for AI training. Lawmakers may be prompted to define what constitutes permissible use of online content, clarify the legal weight of robots.txt files and API policies, and codify the rights of digital platforms to enforce licensing regimes.
Already, signals from the U.S. Federal Trade Commission (FTC) and the European Commission indicate a willingness to investigate AI training data practices. If Reddit’s claims succeed in court, regulators may use the decision as a blueprint for broader policy enforcement. Conversely, a dismissal of Reddit’s claims could embolden AI firms to continue training on any publicly accessible data, absent explicit copyright or statutory protections.
Either way, the case is likely to influence how regulatory bodies perceive the AI data pipeline—and whether more structured oversight is necessary to preserve user trust, platform autonomy, and democratic data governance.
Implications for Platform Governance and User Relationships
Lastly, the Reddit-Anthropic lawsuit has important implications for how platforms manage their relationships with users. While Reddit is advocating for data control, critics argue that the platform is also monetizing content contributed by users without offering them direct compensation or participation in licensing decisions. This paradox—platforms suing AI companies for exploiting content while simultaneously licensing it themselves—may create tensions within online communities.
Going forward, platforms may need to revisit how they communicate data policies to users, provide transparency around data monetization, and offer clearer options for consent and opt-out. Some may even explore revenue-sharing models, where users who generate valuable training data receive micro-compensation or platform perks in exchange for licensing rights. These moves could bolster trust and set a higher ethical bar for data usage across the board.
For Reddit, the legal challenge against Anthropic is thus more than a defensive maneuver—it is a strategic assertion of platform governance and a test of whether digital infrastructure operators can reclaim authority over how their data is used in the AI age.
Navigating the Future of AI and Data Rights
The lawsuit between Reddit and Anthropic represents a watershed moment in the intersection of artificial intelligence, data governance, and platform accountability. What initially appears to be a dispute over unauthorized data scraping quickly unfolds into a far-reaching legal and ethical confrontation that may shape the future rules of engagement between AI developers and content-hosting platforms. As generative AI models continue to proliferate and grow in sophistication, the boundaries of fair use, data consent, and digital ownership are being actively renegotiated in courtrooms, boardrooms, and regulatory agencies around the world.
At its essence, Reddit's complaint against Anthropic is not simply a matter of enforcing technical terms of service. It is a decisive assertion of platform sovereignty—a declaration that content generated by its community is a proprietary asset, not an open-access utility. By alleging that Anthropic bypassed licensing protocols and harvested Reddit content without consent or compensation, Reddit is challenging a status quo in which data-rich platforms have historically been treated as low-hanging fruit for AI model training. The company’s message is clear: the rules have changed, and content is no longer free for the taking.
This legal action is emblematic of a larger trend among digital platforms to reclaim control over the monetization and distribution of their data. With the rise of API paywalls, licensing frameworks, and content usage audits, platforms like Reddit, Stack Overflow, and X are seeking to transform user-generated data into regulated economic assets. These moves are not only motivated by revenue generation but also by the desire to shape how their data is interpreted, repurposed, and presented by downstream AI systems. As AI-generated content becomes more common in consumer interactions, these platforms recognize the reputational and strategic risks associated with being uncredited or misrepresented in model training.
At the same time, the lawsuit spotlights the evolving expectations placed on AI companies themselves. In the early stages of LLM development, developers often relied on broadly accessible web data under the assumption that public availability implied permissibility. But as AI systems grow more integrated into commercial products and services—and as their influence on society deepens—this assumption is increasingly challenged by legal, ethical, and regulatory scrutiny.
Anthropic’s alleged refusal to license data from Reddit stands in contrast to peers like Google and OpenAI, which have secured formal agreements. This divergence not only fuels Reddit’s legal argument but also reflects the lack of uniform standards across the AI sector. Without consistent guidelines on data sourcing, each company is left to interpret the limits of fair use, leading to fragmented practices and heightened legal risk. The Reddit case, depending on its outcome, could catalyze the formation of industry-wide norms and usher in a new era of structured data acquisition in AI development.
Another critical implication of this lawsuit lies in its potential to influence how regulatory bodies craft and enforce future policy. Whether the U.S. courts uphold Reddit’s claims or dismiss them on the grounds of public domain, the ruling is likely to be closely watched by lawmakers in the United States, the European Union, and Asia. Issues raised by the case—ranging from user consent to platform rights and competitive fairness—are central to ongoing discussions about AI accountability. For regulators drafting the next generation of AI laws, the Reddit-Anthropic dispute may provide a concrete template for codifying permissible data practices.
Equally important is the impact on end users—the individuals whose contributions form the foundation of both Reddit’s value and the training datasets of AI models like Claude. Although Reddit is not seeking to represent its users directly, its lawsuit underscores a growing tension between user expectations and platform monetization strategies. On one hand, users may feel their privacy and agency are compromised when their content is used to train commercial AI systems without their knowledge. On the other hand, platforms like Reddit argue that licensing and enforcement are necessary to preserve the quality and sustainability of user communities in an increasingly AI-driven digital ecosystem.
This tension is unlikely to be resolved easily. In fact, the Reddit-Anthropic lawsuit may accelerate calls for greater user control over data contributions, including opt-out mechanisms, consent layers, and compensation models. Platforms that once viewed users primarily as content creators may need to reimagine them as stakeholders with rights and interests in how their content is commercialized. In the long term, this could give rise to a more participatory model of digital content governance—one in which platforms, users, and AI developers negotiate access and value more transparently.
Furthermore, the outcome of this case may influence the trajectory of generative AI model design. If courts impose stricter constraints on the use of public content, AI companies may need to pivot toward curated datasets, synthetic data generation, or direct licensing from content owners. These approaches, while potentially more costly and resource-intensive, could also yield benefits in terms of accuracy, bias mitigation, and regulatory compliance. In this way, the Reddit-Anthropic lawsuit might serve as a corrective force—pushing AI development away from opportunistic data harvesting and toward more ethical, reliable, and human-centered practices.
From a strategic perspective, Reddit’s lawsuit is also a signal to other AI companies: data ownership matters, and cutting corners to gain training data may not only damage reputations but also invite significant legal liability. As the generative AI space becomes more competitive and regulated, those who prioritize ethical data sourcing and transparent partnerships may enjoy long-term advantages over those who engage in opaque or adversarial practices.
In closing, the Reddit v. Anthropic case is not just a legal dispute; it is a defining moment for the AI industry. It underscores the urgent need for clearer standards, mutual respect between platforms and AI developers, and meaningful protections for users whose voices and stories fuel the generative technologies of tomorrow. Whether Reddit prevails or not, the case has already advanced the conversation about data rights in the AI era—and forced a reckoning that the industry can no longer postpone.
References
- Reddit sues Anthropic over data scraping
https://apnews.com/article/reddit-sues-anthropic-ai-data-privacy - Reddit files lawsuit against Anthropic for unauthorized use of data
https://www.theverge.com/2025/06/04/reddit-lawsuit-anthropic-claude - Anthropic’s Claude under fire in Reddit legal complaint
https://techcrunch.com/reddit-anthropic-lawsuit-ai-models - Google and OpenAI sign licensing deals with Reddit
https://www.wsj.com/tech/reddit-licenses-content-ai - The rise of AI data licensing among tech platforms
https://www.cnbc.com/reddit-google-openai-licensing - Anthropic’s data sourcing practices questioned
https://www.bloomberg.com/news/articles/anthropic-data-use-ai-training - Ethical dilemmas in AI model training
https://www.nature.com/articles/ai-data-ethics-analysis - How Reddit’s API changes impacted AI companies
https://www.reuters.com/technology/reddit-api-policy-ai-industry - Legal challenges shaping AI regulation
https://www.lawfaremedia.org/article/legal-frameworks-generative-ai - Timeline of major AI lawsuits and their impact
https://www.wired.com/story/ai-lawsuits-training-data