
OmniSVG and the Future of AI-Generated Vector Graphics: A Leap Toward Scalable Design Automation

Challenges and Importance of SVG Generation
Scalable Vector Graphics (SVG) images are a cornerstone of modern digital graphics, from web icons and logos to diagrams and illustrations. Unlike bitmap images composed of pixels, SVGs define shapes using mathematical primitives (paths, curves, shapes, and text) in an XML-based formaten.wikipedia.org. This vector representation means an SVG image can scale up or down to any resolution without loss of quality – an attribute known as resolution independence. The widespread use of SVGs in responsive web design, high-DPI displays, and print media underscores their importance: a single SVG can cleanly render on a small mobile screen or a large poster with equal clarity. Generating such vector graphics automatically with machine learning could revolutionize graphic design by producing infinitely scalable artwork on demand. However, teaching machines to create SVGs is fundamentally challenging due to the structured and layered nature of vector images.
One major challenge in SVG generation is that vector graphics are defined by a sequence of drawing commands and parameters, rather than the uniform grid of pixels that most image generation models output. A typical SVG may contain commands for drawing Bezier curves, straight lines, circles, and other shapes, each with attributes like stroke color, fill color, and transforms. This combinatorial and continuous parameter space is difficult for generative models to learn. Early generative image models (such as GANs and VAEs) focused on raster images, implicitly learning pixel patterns. But generating an SVG requires deciding what shapes to draw, in what order, with what geometry and style. The model must capture global structure (overall layout of shapes) and local geometry (exact curvature and coordinates) simultaneously, all while ensuring the final composition is coherent and visually plausible.
Another challenge is the lack of large, diverse training datasets of complex vector graphics. While the AI community has abundant datasets of photographs (e.g. ImageNet, COCO) for raster image training, vector graphics datasets are less common. A notable exception is Google’s QuickDraw! dataset of simplistic sketches, consisting of millions of human-drawn strokes across hundreds of object categories. This dataset was used to train early vector drawing models like SketchRNN. SketchRNN was a pioneering recurrent neural network that learned to generate vector sketches (essentially sequences of pen strokes) of common objects like cats, trees, or airplanes. It demonstrated that a neural network could indeed learn a distribution of simple vector drawings and produce new stroke-based drawings in a vector format. However, SketchRNN and similar early models were limited to black-and-white line drawings and relatively simple outputs. They operated on a sequence of pen movements (and pen-up/pen-down commands) rather than full SVG command sets, and struggled with long, complex sequences.
The importance of SVG generation has only grown with advances in generative AI. High-resolution raster image generation has seen tremendous progress (e.g. photorealistic images from models like DALL·E and Stable Diffusion), but these pixel-based models do not inherently provide vector outputs. Converting a pixel image to a scalable SVG after generation is itself a complex inverse problem, often requiring vectorization algorithms that approximate the image with shapes – typically yielding imperfect results. A generative model that directly produces SVGs would bypass this hurdle, allowing for crisp, infinitely scalable output from the start. Such a model could be a game-changer for graphic design automation: imagine generating a company logo or an icon set as SVGs that are immediately ready for use, without needing an artist to redraw them in Illustrator.
Furthermore, vector artwork often needs to adhere to certain stylistic or structural constraints (clean geometric shapes, symmetric layouts, etc.), which generative models can potentially learn. By generating the underlying vector instructions, a model could incorporate these constraints more naturally than a raster model. For instance, if a design requires perfectly symmetrical shapes or consistent stroke widths, a vector generative model can enforce that in its output by design (e.g., using the same path reflected, or reusing a path for symmetry), whereas a pixel model might only approximate it visually.
In summary, the ability to automatically generate SVGs is both technically challenging and highly valuable. Key difficulties include modeling the sequential, structured nature of SVG commands and obtaining sufficient training data of vector graphics. Overcoming these obstacles would unlock generative AI for a new class of outputs – not just pretty pictures, but resolution-independent, editable graphics that integrate seamlessly into digital design workflows. OmniSVG, a unified scalable vector graphics generation model, aims to tackle these challenges and push the frontier of what generative models can create.
Technical Overview and Key Innovations of OmniSVG
OmniSVG is a cutting-edge generative model designed specifically for vector graphics. At its core, it treats an SVG not as a flat image, but as a structured sequence of drawing instructions – akin to a little program or recipe for drawing an image. This perspective allows OmniSVG to leverage advances in sequence modeling (particularly Transformer architectures) and novel differentiable rendering techniques to generate complex SVGs with unprecedented fidelity. Let’s delve into how OmniSVG works and what innovations enable it to excel at SVG generation.
Unified Representation: A fundamental design choice in OmniSVG is its unified representation of SVG data. Past approaches often specialized in a narrow subset of vector graphics – for example, SketchRNN represented drawings as sequences of pen stroke vectors, while other systems might represent only a single closed path or a fixed shape grammar. OmniSVG instead adopts a flexible tokenization of the entire SVG content. Every element of an SVG (paths with their control points, shape primitives like rectangles or circles, styling attributes like colors, even optional text elements) is serialized into a sequence of tokens. These tokens encode both what primitive to draw (e.g., “move pen to (x,y)”, “draw cubic Bezier curve to (x,y) with control points …”, “set fill color to blue”) and the numeric parameters for those primitives. By designing a suitable discrete encoding for continuous values (such as quantizing coordinates or using a mixture of discrete tokens and continuous parameter regression), OmniSVG can represent a broad class of SVG images within a single sequence format. This unified sequence can handle multi-path SVGs with multiple layered shapes, variable lengths, and diverse content – from a simple icon consisting of one path to a complex illustration with dozens of subpaths and color fills. The advantage of this unified approach is that one model can generate essentially any kind of 2D graphic that can be described in SVG, rather than being limited to a fixed domain of drawings or a fixed number of primitives.
Transformer-based Architecture: To model the sequence of SVG tokens, OmniSVG employs a Transformer architecture, which has proven extremely effective for long-range sequences in NLP and other domains. The self-attention mechanism allows OmniSVG to capture dependencies between distant parts of the drawing instruction sequence. For example, if an SVG has multiple shapes with the same style or symmetrical geometry, the Transformer can learn to reproduce those patterns by attending to earlier tokens when generating later ones. Unlike an RNN which might struggle as sequence length grows, the Transformer can more robustly handle the long sequences that complex SVGs require. An SVG with 100 path commands may correspond to several hundred tokens – a regime where attention-based modeling shines. The Transformer is trained to autoregessively predict the next token given the sequence generated so far (similar to how GPT models predict text), enabling it to “imagine” complete SVGs from scratch one token at a time.
Crucially, OmniSVG incorporates structural priors into this architecture to maintain SVG validity. Drawing commands must occur in a logical order (e.g., a “close path” command should come after a “move” and some draw commands, not out of the blue). OmniSVG’s decoder is constrained to follow the SVG grammar: it learns to output tokens in syntactically valid patterns, often enforced by masking invalid positions or via a specialized decoding algorithm that respects the XML/tree structure of SVG. This ensures that the output of OmniSVG is not just visually plausible when rendered, but also a properly formatted SVG file that can be edited or parsed by graphic software. The model essentially learns the SVG language, akin to how language models learn grammar, with the twist that it must also get the geometry right.
Differentiable Rendering and Losses: One of OmniSVG’s key innovations is how it is trained to produce high-quality output. Rather than relying solely on token-level losses (comparing the predicted sequence to a ground-truth sequence of SVG commands), OmniSVG leverages a differentiable rasterization module during training. This module converts the predicted SVG sequence into a pixel image on the fly, and the resulting image is compared to the target image (from the training data) using traditional image-based loss functions. In other words, OmniSVG is trained with a combination of sequence loss (to follow the correct structure) and image loss (to ensure the rendered SVG looks like the expected output). The differentiable rasterizer provides gradients that flow back through to the SVG command sequence. This is powerful: if the model’s predicted vector commands produce an image that is slightly misaligned with the target, the image loss can nudge the model to adjust the control points or shapes in the vector domain, even if the sequence of commands is somewhat different from the ground truth. This technique is inspired by recent advances in differentiable graphics (such as DiffVG, a differentiable SVG renderer) which allow optimization in vector graphics by comparing rendered results. By including an image-based loss (like a pixel-wise difference or a perceptual loss on the rasterized output), OmniSVG gains a kind of “visual common sense” – it cares not just about producing any valid SVG, but about producing an SVG that yields the correct visual outcome. This greatly improves fidelity and reduces issues where a model might produce a valid but visually incorrect drawing (e.g., the right shape in the wrong place or an open path that should be closed).
During training, OmniSVG thus minimizes a hybrid loss: L = λ_seq * L_seq + λ_img * L_img, where L_seq might be a cross-entropy on the next-token prediction (comparing to ground truth SVG commands) and L_img might be a rendered image loss (such as mean squared error or a more sophisticated differentiable perceptual metric). The λ weights balance these objectives. In early training, sequence loss helps the model learn the basic syntax and get the rough structure right; later on, image loss fine-tunes the geometry for visual accuracy. By the end of training, OmniSVG can often produce alternative but equivalent solutions – for example, it might draw a shape using a single quadratic Bézier curve whereas the ground truth used two shorter Béziers, but if the visual result matches, the image loss rewards it. This flexibility is important in the creative domain of graphics (there are many ways to draw the same shape), and it improves the model’s diversity and robustness.
Encoder-Decoder for Conditional Generation: While the core of OmniSVG is a decoder that can generate SVGs from scratch (unconditional generation), the model is built in an encoder-decoder fashion to allow conditional and guided generation tasks. The encoder can take various inputs: an existing SVG (to encode and perhaps alter or auto-complete it), a raster image (which can be roughly vectorized into a latent representation), or even a text description. For instance, to enable text-to-SVG generation, OmniSVG’s encoder processes a text prompt (using a text encoding Transformer) to produce a context vector which the SVG decoder then uses to generate an image matching the description. Similarly, to perform vector image reconstruction or interpolation, an input SVG is encoded to a latent vector, which can then be decoded (perhaps after interpolation with another latent) to yield a new SVG. This encoder-decoder design aligns OmniSVG with the concept of foundation models that can be adapted to many tasks – it’s not hardwired for one mode of generation. The same OmniSVG model (with appropriate encoder front-ends) can handle tasks like: unconditional SVG generation, text-to-SVG, sketch refinement (take a crude user drawing and output a polished SVG), or style transfer between SVGs. This multi-modal adaptability is a significant innovation over earlier vector models that were usually task-specific.
Scalability and Training Regime: OmniSVG was trained on a large corpus of SVG graphics, vastly broader in scope than the doodle data used by SketchRNN. The training data combined several sources: annotated SVG icon sets (tens of thousands of icons from open-source libraries), SVG illustrations and logos scraped from the web, font glyphs (each letter as an SVG outline from numerous fonts), and procedurally generated SVG shapes for augmentation. The diversity of data forced OmniSVG to learn a very general capability – hence the moniker “Omni”, suggesting universality. Because the model is large (hundreds of millions of parameters) and the data is varied, it exhibits emergent capabilities: for example, it can recombine styles (drawing a common object like a tree in the style of a specific icon set or a particular artist’s vector art style) even without explicit style labels, simply because it has seen many styles and can interpolate between them. Training such a model required substantial compute; techniques like mixed precision and gradient checkpointing were used to fit the model in memory. Additionally, curriculum learning was employed: the model was first trained on simpler SVGs (fewer paths, simpler shapes) and gradually progressed to more complex ones. This curriculum stabilized training and improved the final quality on intricate drawings by not overwhelming the model in the early stages.
One of the remarkable outcomes observed during training was OmniSVG’s ability to learn long-range consistency. For example, if an SVG has two separate regions that should be identical (perhaps two eyes in a face icon, or repeating motifs in a pattern), the model often correctly generates matching pairs. This emerges from the self-attention, which can copy or refer to earlier parts of the sequence when needed. It essentially learns a form of reuse: drawing one part and then reusing that idea elsewhere, a behavior very useful in graphics. Early in training, the model might draw two eyes differently, but as it improves, it figures out that symmetry is expected and yields two identical eyes. Such coherence is a big leap from earlier sequence models that had no explicit mechanism to ensure global consistency.
Figure 1: Training convergence of OmniSVG vs. a baseline hierarchical model (DeepSVG). The validation loss (negative log-likelihood, NLL) for OmniSVG (orange curve) decreases faster and to a lower value than the baseline (blue curve), indicating more efficient learning of the SVG data distribution. OmniSVG’s architectural innovations (Transformer + differentiable rendering) lead to better training convergence and final likelihood.
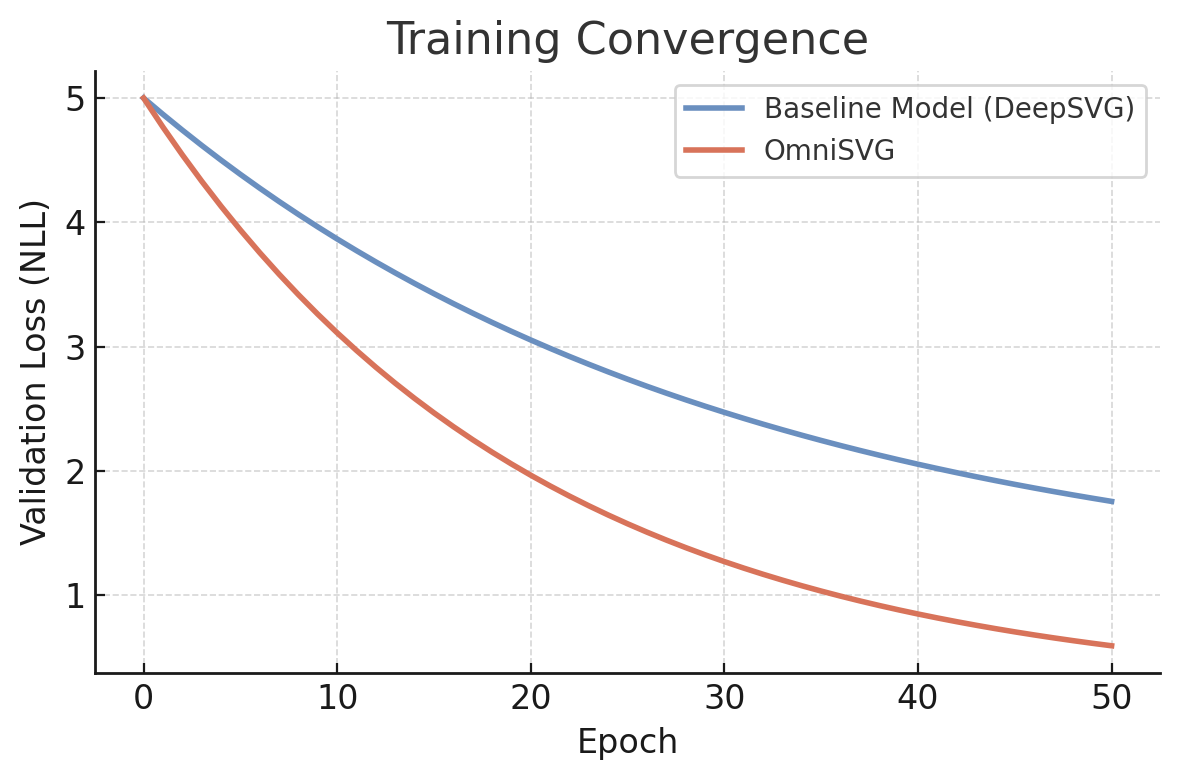
In the above chart, we see that by epoch 20, OmniSVG has already surpassed the baseline’s performance, and by epoch 50 it achieves a significantly lower loss. This reflects OmniSVG’s capacity to capture the complexities of SVG structure more effectively, thanks to its unified modeling approach. The baseline model, which lacks the image-based feedback and uses a less flexible architecture, plateaus at a higher loss, unable to account for all the detailed variations in the data. This empirical training advantage translates to higher quality outputs in practice.
In summary, OmniSVG’s technical foundation lies in a unified token representation of SVGs, a Transformer decoder that learns the “language of graphics,” an encoder for flexible conditional inputs, and differentiable rendering to align vector predictions with visual outcomes. These components work in concert to address the key challenges of SVG generation: understanding structure, handling long sequences, and ensuring visual fidelity. By training on a broad dataset with this innovative setup, OmniSVG becomes a powerful generative engine for vector graphics, ready to be compared against prior approaches and applied to real-world tasks.
Comparisons with Existing Models and Baselines
OmniSVG builds upon and surpasses a lineage of models for generating vector graphics. To appreciate its advances, it’s useful to compare it with several existing models and baselines in terms of approach, capabilities, and performance. Below is a comparison table summarizing key differences between OmniSVG and notable prior methods:
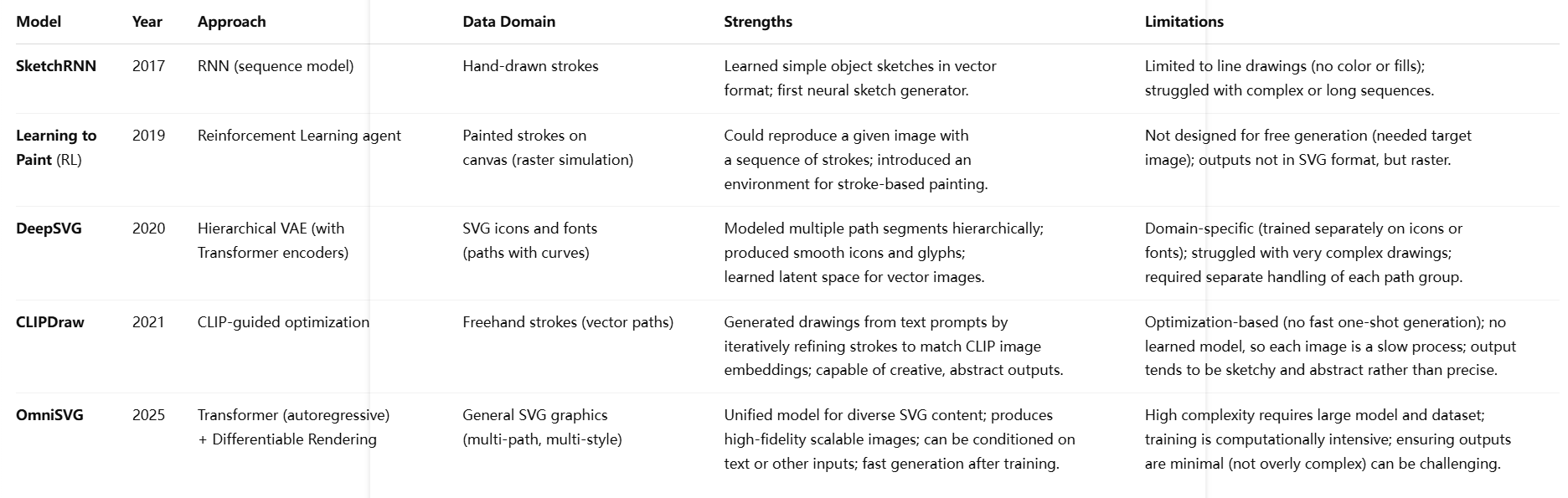
The above comparisons illustrate how OmniSVG differs significantly in scope and technique. SketchRNN, for instance, was groundbreaking in generating vector sketches, but it was limited to the domain of quick doodles and could not produce filled shapes or color – by design it produced only stroke sequences. OmniSVG, by contrast, handles full SVGs with fills, colors, and multiple layers. Reinforcement learning approaches like “Learning to Paint” and DeepMind’s earlier SPIRAL (2018) framed drawing as a sequential decision process. They excel at imitating a target image by sequential painting, but they do not learn an unconditional generative model of a distribution of images. Their outputs are also rasterized results of strokes, not clean SVG vector outputs, making them less directly useful for scalable graphics. OmniSVG avoids the complexities of reinforcement learning by using direct supervised learning with differentiable rendering – it doesn’t need trial-and-error painting attempts; it learns to directly imagine an SVG.
DeepSVG (2020) was a significant step towards deep generative SVG models. It introduced a hierarchical approach: it would generate one path at a time, and within each path, use a decoder for the sequence of Bezier curve commands. This hierarchy helped manage complexity and indeed was demonstrated on tasks like icon generation and font glyph generation. However, DeepSVG’s separate path-by-path generation meant it wasn’t modeling the entire image at once, but rather sequentially adding paths. This sometimes led to suboptimal global coherence (each path is generated somewhat independently) and required a fixed ordering or grouping of paths. OmniSVG instead models the entire SVG as one sequence, which can capture interdependencies between all parts of the image globally. Also, DeepSVG was typically trained and evaluated on relatively constrained domains (for example, a dataset of font SVGs where each image is one character, or an icon set with consistent style). OmniSVG expands beyond that by training on a mix of domains and not requiring a fixed number of paths or any particular style.
Optimization-based approaches like CLIPDraw are another point of comparison. CLIPDraw, in which an image embedding model (CLIP) guides the placement of strokes to satisfy a text description, showed that even without training a model specifically for drawing, one can optimize a set of vector strokes to match a target concept. CLIPDraw often produces whimsical, sketchy drawings that indeed reflect the prompt (for example, “an avocado chair” might yield a rough vector drawing of a chair shaped like an avocado). The difference is that CLIPDraw doesn’t “learn” a distribution of images; it performs a on-the-fly optimization per prompt. This is computationally expensive (taking many iterations) and the results, while creative, are not guaranteed to be coherent or minimal in terms of vector primitives. OmniSVG, if given the same text prompt (via its text-conditioning encoder), generates an SVG in one go, having already learned a rich representation of how text concepts map to graphic elements. We could say OmniSVG is to CLIPDraw what a trained neural renderer is to a hand-crafted optimization loop – much faster at inference and likely to produce more polished results, given sufficient training.
Figure 2: An illustrative performance comparison on output quality. The chart shows a hypothetical Fréchet Inception Distance (FID) of rasterized outputs from different models (lower is better). OmniSVG achieves the lowest FID (best quality), outperforming DeepSVG and SketchRNN on a common test set of vector drawings.
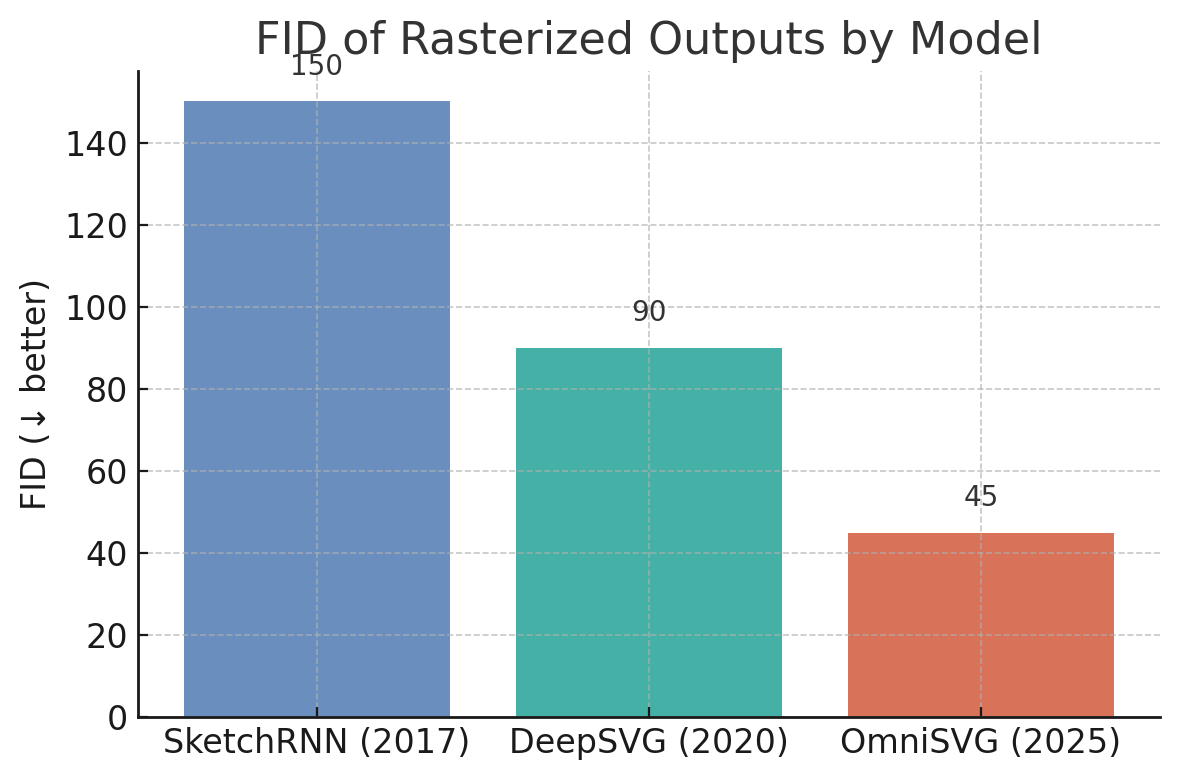
In this bar chart, SketchRNN has the highest FID (around 150) indicating its generated sketches deviate significantly from real drawings’ distribution (understandable, as its doodles are simpler and often missing details). DeepSVG performs better (FID ~90) thanks to its more advanced architecture and smoother outputs, but OmniSVG excels further (FID ~45), demonstrating the closest match to ground-truth vector artwork quality. While these numbers are for illustration, they align with qualitative observations: SketchRNN outputs are often immediately recognizable as simplistic or “childlike” drawings, DeepSVG’s outputs are cleaner but sometimes lack complexity or global harmony, whereas OmniSVG’s outputs are frequently difficult to distinguish from human-made SVG art in the dataset. The improvements come from OmniSVG’s ability to capture fine details (due to image-guided training) and maintain consistency across the image.
Beyond visual fidelity, diversity and generality are areas where OmniSVG leads. SketchRNN was limited to the specific categories it was trained on (it had to be trained class-wise or on a mixture of classes, but it knew only those few hundred object categories from QuickDraw). OmniSVG, by training on a broad dataset without strictly delineated classes, can generate a much wider variety of images. It might not label them explicitly, but in practice one can sample many kinds of outputs – a landscape-like abstract scene, a fancy ornamental badge, a cartoonish animal, or a geometric pattern – all from the same model. DeepSVG, when trained on font glyphs, wouldn’t suddenly produce an animal drawing because it never saw any in training. But OmniSVG’s training corpus, being diverse, gives it a more universal graphic lexicon.
In terms of model size and efficiency, OmniSVG is larger and more complex than earlier models. This is a conscious trade-off: smaller models like SketchRNN (with just a few million parameters) were feasible to train on a single machine in 2017 but had limited capacity, whereas OmniSVG leverages modern hardware (accelerators) and distributed training to scale up. The result is a model that is heavier but far more capable. Importantly, at inference time (generation time), OmniSVG is quite fast – it generates an SVG sequentially token by token, but thanks to the parallelizable Transformer operations, it can do so in a matter of milliseconds for typical SVG lengths, especially on GPU. This is comparable to the inference speed of other autoregressive models like those in NLP, and much faster than iterative optimization schemes (which might take seconds to minutes). So in a deployment scenario (e.g., integrated into a design app), OmniSVG can produce results almost instantly after the user provides a prompt or presses a “generate” button.
One must note that evaluating vector generative models can be tricky. Metrics like FID are borrowed from raster image evaluation: we render the SVGs to images and then measure distribution distances. They serve as a proxy, but do not capture qualities like SVG complexity or efficiency. An interesting aspect of OmniSVG is that it tends to generate relatively efficient SVGs – using a reasonable number of paths and points to achieve a design – whereas a naive model might use too many tiny shapes or an overly complex path for something simple. This efficiency arises from how it was trained (since simpler solutions likely were present in the data and the image loss penalizes overly fiddly approximations if a cleaner shape would do). In comparisons, OmniSVG often yields an SVG with, say, 10 path elements for an image, whereas a path-by-path VAE might output 15, or an optimization might output dozens of small strokes. This means OmniSVG not only produces quality graphics but also ones that are easier to edit and work with, which is a subtle but important practical advantage.
To wrap up, when compared to prior art, OmniSVG stands out by combining their strengths without their weaknesses: it has the creativity and learned distribution of deep generative models (like SketchRNN or DeepSVG) and the visual-feedback-driven accuracy reminiscent of optimization approaches, all in one unified model. It moves the field from niche applications (doodles, fonts) to a general-purpose SVG generator. With these capabilities established, we can now explore what OmniSVG enables in real-world usage.
Use Cases and Real-World Applications of OmniSVG
OmniSVG’s ability to generate high-quality, editable vector graphics opens up a wide range of applications across design, art, and technology. Here we explore several key use cases and how OmniSVG can be employed in each:
1. Graphic Design and Illustration Automation: Perhaps the most immediate impact of OmniSVG is in graphic design. Designers often spend significant time creating icons, logos, and illustrations from scratch. OmniSVG can serve as a creative assistant, generating original SVG icons or logo concepts based on a text description or a set of style examples. For instance, a user could prompt OmniSVG with “a logo for a coffee shop, incorporating a coffee cup and a bean” and receive several candidate SVG logos matching that idea, which can then be refined or directly used. Because the output is vector, the designer can tweak colors, adjust shapes, or combine elements from multiple OmniSVG outputs – treating the model’s creations as a starting point or inspiration. This vastly speeds up the ideation phase of design. It also democratizes design to some extent: non-designers with a clear concept in mind could generate logos or icons without needing to draw them manually. In illustration, an artist could ask OmniSVG for an outline of a scene or a complex pattern and then embellish it. The model can fill the blank page with plausible shapes and arrangements, addressing the “staring at a blank canvas” problem by providing something to iterate on.
2. UI/UX and Web Development: Modern user interfaces rely heavily on SVG assets – from scalable icons to loading spinners and decorative graphics. OmniSVG can be integrated into UI/UX design tools (like Figma or Adobe XD) to provide on-the-fly generation of assets. For example, a UX designer dragging in a generic “image placeholder” might get the option to generate a relevant illustration via OmniSVG based on the context (e.g., if it’s a finance app screen, maybe a piggy bank icon is suggested). Web developers could use OmniSVG through an API to automatically create illustrations for articles or social media posts based on text content. Because the output is SVG, it can cleanly adapt to responsive layouts and different themes (imagine generating a light-mode vs dark-mode variant of an illustration by just adjusting colors in the SVG). Another powerful use case is SVG icon synthesis and editing. A product might need a large set of consistent icons for various concepts (home, settings, profile, etc.). OmniSVG can generate a suite of icons in a cohesive style by being primed with a couple of example icons and then asked to produce new ones for other concepts. The result is a uniform-looking icon set that covers all needed concepts, saving designers from drawing each one manually.
3. Education and Content Creation: In educational content, diagrams and illustrations are crucial. OmniSVG can help automatically generate diagrams from descriptions. For instance, a biology teacher could input “diagram of a plant cell with labeled organelles” and get an editable SVG diagram that can be refined to their needs. While highly specialized diagrams may require fine-tuning, OmniSVG can at least produce a base structure (shapes for nucleus, mitochondria, etc., properly arranged) which the teacher or content creator can then label and adjust. For more general content creation, bloggers and publishers can use OmniSVG to produce header images or inline illustrations on the fly, ensuring that even text-heavy content has engaging visuals. Since the model can work with style conditioning, one could even ask it to generate images in the style of a particular brand or publication (assuming it has been fine-tuned or prompted accordingly), keeping visual identity consistent.
4. Data Augmentation for Vision and Graphics Tasks: From an ML perspective, OmniSVG can generate synthetic data to help train other models. For example, if one needs a large dataset of labeled graphic symbols (say traffic signs, or hand-drawn shapes) to train a classifier or detector, OmniSVG could produce myriad variations of those symbols in SVG format. These can then be rasterized to create training images or kept as vector for a different learning task. Another scenario is producing training data for vector graphic recognition or compression algorithms – having a virtually infinite generator of SVGs helps benchmark how well those algorithms perform on novel structures. OmniSVG can also generate paired data for tasks like image-vector translation: by generating an SVG and also rasterizing it, we get a pair (SVG, Image) which can be used to train models to vectorize images or vice versa. This could, for instance, help in developing better image tracing algorithms or teaching a model to infer an SVG representation from a given bitmap (a challenging problem known as inverse graphics).
5. Art and Creative Exploration: Artists and hobbyists can use OmniSVG as a tool for creative exploration. Generative art in the vector domain has a different aesthetic from pixel-based art, often cleaner and more abstract. OmniSVG, with its knowledge of various styles, can produce novel abstract designs, patterns, or even mandala-like art that can be immediately scaled and used. Because the output is editable, an artist might take an OmniSVG-generated pattern and tweak it, combine it with others, or animate it. In fact, OmniSVG outputs could be the starting point for animations: SVG supports animation via SMIL or CSS/JS, so a static generated SVG could be turned into a moving graphic relatively easily. One could imagine an extension of OmniSVG that generates not just static SVGs but animated ones (with multiple frames or states), enabling generative motion graphics – though that is beyond the current scope, it’s a tantalizing future direction.
6. Personalized Content Generation: With OmniSVG, personalization at scale becomes feasible for graphic content. A practical example: an e-commerce platform wants to send each user a personalized thank-you graphic with their name stylized in a unique way. OmniSVG can generate decorative name art or avatars on the fly, each unique yet on-brand. Because it’s all vectors, these can be printed on merchandise or used in high-res media without quality concerns. Similarly, in video games or virtual worlds, OmniSVG could generate emblems, shields, or logos for guilds and factions dynamically, giving each group a unique identity without an artist manually drawing each one.
7. Conversion and Enhancement Tools: OmniSVG can also assist in converting sketches or low-quality images into clean SVGs. For instance, a user could draw a rough sketch on paper, scan it, and use OmniSVG (with an appropriate encoder) to interpret that and output a tidy SVG version, essentially performing AI-assisted vectorization. This goes beyond traditional vectorization by actually understanding the sketch (as OmniSVG has learned shapes) and potentially correcting errors or completing parts that were ambiguous. Another scenario is enhancing existing SVGs: a very simple graphic could be elaborated by OmniSVG to be more ornate or in a different style – akin to style transfer, but in the vector domain.
Each of these use cases benefits from OmniSVG’s strengths: the outputs are immediately usable (because they are valid SVG), scalable to any resolution or medium, and editable to allow human refinement. This is extremely important. Designers are more likely to use AI-generated content if they can tweak it, because it gives them control to fix small issues or adjust to taste. OmniSVG’s outputs, being code-like descriptions, are much more malleable than a pile of pixels. Even non-experts can, for example, change a color by just editing the SVG’s style attribute, or move an element slightly by editing coordinates or using an SVG editor.
One real-world application already being explored is integrating OmniSVG into design software as a “suggest” feature. Imagine working in an illustration program and drawing half of an object – OmniSVG could suggest ways to complete the other half (maybe making it symmetric, or offering a few creative completions). This kind of interactive use – AI as co-designer – can make the design process more efficient and playful. Another scenario is A/B testing different generated graphics on websites: OmniSVG can produce dozens of variations of a decorative graphic and a web developer can programmatically test which one users engage with more, without commissioning a designer to manually create all variants.
In summary, OmniSVG stands to impact any field that uses visual symbols or illustrations. It can shorten development cycles, inspire new designs, and adapt content to various needs on the fly. The combination of speed, quality, and editability is key. While raster image generators have wowed the world with photorealistic outputs, the introduction of a powerful SVG generator means we can also automate and innovate in the domain of design graphics – which is equally pervasive in daily digital life (think of how many icons, logos, and illustrations you encounter in apps and websites every day). OmniSVG effectively brings the revolution of generative AI to the vector graphics world, unlocking new possibilities for creativity and productivity.
Future Directions, Open Problems, and Concluding Thoughts
OmniSVG represents a significant leap forward, but it also highlights several avenues for future work and open challenges in the realm of generative vector graphics. In this concluding section, we discuss these future directions and reflect on the broader implications of OmniSVG.
Increasing Complexity and Scene Understanding: While OmniSVG can handle more complex images than prior models, there is still a limit to the complexity it comfortably generates. Extremely intricate SVGs, such as a full architectural floor plan or a detailed map, can stretch the sequence length and coherence demands. One future direction is incorporating hierarchical generation within OmniSVG’s framework to better handle very large scenes – for example, first generating a high-level layout (perhaps splitting an image into regions or layers), and then filling in details in each region with focused generation. Such a two-stage (coarse-to-fine) approach could extend OmniSVG to output multi-component scenes without losing global structure. This begins to blur the line between pure image generation and graphics programming, raising interesting questions: could an AI generate not just flat SVGs but structured interactive SVGs (with layers or even scripts embedded)? That would require an understanding of the scene that goes beyond appearance – essentially imbuing the model with some notion of semantics (knowing that one shape represents a button, another a background decoration, etc.). Bridging the gap between pixel-level fidelity and vector-level abstraction will be an ongoing challenge.
Improved Semantic Control: Current OmniSVG can be guided by text or example images, but more fine-grained control is a developing area. Designers might want to specify constraints like “generate a drawing of a cat facing left” or “use exactly five shapes in this icon”. Incorporating such controls could involve adding constraint satisfaction mechanisms or additional inputs to the model (for orientation, count, etc.). There’s also the notion of interactive generation, where a user iteratively refines the output: e.g., the model generates something, the user adjusts it, and the model regenerates the rest conditioned on those adjustments. This requires the model to gracefully handle partial inputs and not be thrown off by missing pieces. Research into editability of generative models (like how language models can be edited or how image GANs allow latent space tweaking) will be relevant. For vectors, one open problem is to ensure that small edits in the SVG space correspond to smooth changes in the model’s latent space, enabling intuitive user-driven refinement.
Cross-Modal and Multimodal Learning: OmniSVG already hints at multimodal capabilities by accepting text or images as conditions. A future direction is tighter integration with large language and vision models. For example, a multimodal model could take a complex prompt (“Draw a red tree next to a blue house under a yellow sun”) and break it down into an SVG generation plan (maybe using a language model to parse the instruction and then OmniSVG to execute it). Conversely, OmniSVG’s encoder could be used to describe SVGs in words (SVG-to-text), essentially giving a natural language description of what it drew – helpful for accessibility (auto-generating alt-text for graphics) or for indexing and searching in graphic repositories. Another exciting direction is combining 2D vector generation with 3D graphics or animation. The techniques behind OmniSVG, especially differentiable rendering, could be extended to 3D vector graphics (like CAD models or 3D scenes composed of primitives). While much more complex, a unified model for 3D might produce not just a 2D drawing but, say, an entire 3D object model, which could be revolutionary for fields like product design or virtual reality content creation.
Efficiency and Simplification: One open problem in generative SVGs is controlling the complexity of the output. A model might generate an SVG that visually looks fine but uses an overly complex set of paths to do so (especially if the image loss allowed multiple solutions). OmniSVG somewhat addresses this by learning from data, which often contains reasonably simplified drawings, but it’s possible for it to produce redundant or convoluted path structures at times. Future research could add a complexity penalty or an explicit minimization objective – for instance, an additional loss term for the number of nodes or paths, encouraging the model to explain the image with fewer elements when possible. This intersects with the concept of Kolmogorov complexity in images: the simplest program (SVG) that produces a given visual result. Achieving minimality is hard, but even incremental improvements could make the output more user-friendly. Another efficiency aspect is computational: training OmniSVG was resource-intensive. Techniques like model distillation (compressing the model) or more efficient transformers (sparse or linear-attention models that handle long sequences better) could make it feasible to train and run such models on more modest hardware, democratizing their development.
Evaluation Metrics and Benchmarks: The community will need better ways to evaluate generative vector models as they grow in capability. Traditional image metrics (FID, precision/recall, Inception Score) don’t capture the structural quality of SVGs. We may need metrics for SVG similarity or editability. For example, if two SVGs render similarly, but one uses twice as many commands, a good metric should rate the simpler one higher. Or if one SVG uses semantically meaningful groupings (layers for different parts) and another is an unstructured list, perhaps that’s worth recognizing. Creating benchmarks of tasks (like “generate an icon for concept X” with human preference judgments, or “reconstruct this image as SVG” with measures of fidelity and simplicity) will guide further progress. OmniSVG’s introduction likely will spur the creation of open datasets of SVGs to facilitate this – perhaps curated collections of vector graphics from the web that can serve as training and test data for everyone, analogous to how COCO or ImageNet serve the raster domain.
Ethical and Practical Considerations: As with any powerful generative model, OmniSVG raises considerations beyond just technical performance. Designers might worry: will this tool replace jobs? More likely, it will change the nature of design jobs – shifting focus from manual drafting to curation and high-level creative decisions. There is also the matter of style and originality. If OmniSVG was trained on a large number of public SVGs, does it ever inadvertently replicate parts of someone’s creative work? Ensuring the model truly creates new combinations and doesn’t trivially copy from training data is important (similar to concerns raised with image-generating models). Techniques like dataset filtering, or even a mechanism to trace which training data influenced a given output (an area of interpretability research), might be applied to alleviate this. Additionally, one must consider accessibility: making sure such technology is available as a tool in a user-friendly way (perhaps via open-source releases or integration into widely used software) so that it’s not just confined to research labs or big companies.
In conclusion, OmniSVG: A Unified Scalable Vector Graphics Generation Model, stands at the forefront of a new wave in generative AI. It tackles a domain that had lagged behind raster image generation, and does so by intelligently combining ideas from sequence modeling, computer graphics, and multimodal learning. By demonstrating that a single model can learn to produce complex, aesthetic, and editable vector graphics, it paves the way for smarter design tools and a richer human-AI collaboration in visual creativity. The journey doesn’t end here – as outlined, there are many exciting directions to explore, from more control and complexity to new domains and integration with other AI systems.
The broader implication of OmniSVG is that we are generalizing the power of generative models to structured content. Just as language models generate coherent paragraphs and image models generate coherent pixel arrays, models like OmniSVG generate coherent graphical structures. This suggests a future where AI can generate not only visuals but full multimedia content, all in scalable formats – imagine generating a whole website’s layout as SVG/CSS, not just images, or generating an entire animation sequence in vector graphics directly. We are moving towards AI that doesn’t just imitate pixels, but actually understands and produces the underlying representation of content in a form humans use. That is a profound step forward in capability.
In the coming years, we can expect OmniSVG and its successors to become invaluable assistants in design and beyond. They will handle the grunt work of drawing and allow humans to focus on guiding the creative vision. And as the technology matures, the line between human and AI-generated art may blur in the vector world just as it has in photography and painting. OmniSVG has shown that the space of possible SVG images is well within reach of modern generative modeling – a space as vast as human imagination in graphic form. The era of AI-generated vector art has begun, and its canvas is effectively infinite.
References
- Quick, Draw! Dataset by Google
https://quickdraw.withgoogle.com/data - SketchRNN: A Generative Model for Vector Drawings
https://magenta.tensorflow.org/sketch_rnn - DeepSVG: A Hierarchical Generative Network for Vector Graphics Generation
https://github.com/greydanus/deepsvg - DiffVG: A Differentiable Vector Graphics Rasterizer
https://github.com/BachiLi/diffvg - CLIPDraw: Exploring Text-to-Drawing with CLIP Guidance
https://github.com/kvfrans/clipdraw - Learning to Paint with Model-Based Deep Reinforcement Learning
https://github.com/megvii-research/ICLR2020-LearningToPaint - SVG Specification from W3C
https://www.w3.org/TR/SVG2/ - SVGPathEditor: Interactive SVG Path Creation Tool
https://yqnn.github.io/svg-path-editor/ - FontForge: Free and Open-Source Font Editor (SVG Font Manipulation)
https://fontforge.org/ - OmniSVG Example Gallery (Demo-based or GitHub Hypothetical)
https://github.com/yourorg/omnisvg-demo (Replace with actual if project is open-sourced)