
Meta Bets on AI for Ethics: Replacing Human Oversight in Privacy and Risk Decisions

In a move that has reignited debate over the role of artificial intelligence in safeguarding human values, Meta, the parent company of Facebook, Instagram, and WhatsApp, has announced its intention to transition critical risk assessments—particularly those involving privacy and societal impact—from human oversight to AI-powered systems. This development marks a significant pivot in how one of the world’s most influential technology companies manages its responsibilities in shaping digital discourse, personal privacy, and global public opinion.
Historically, Meta has relied on a combination of internal teams and external contractors to assess and mitigate a range of risks arising from its platform operations. These risks span a spectrum that includes user privacy violations, algorithmic discrimination, mental health implications of social media use, political misinformation, and the broader consequences of content amplification. Human reviewers, ethics teams, and policy experts played a central role in monitoring and flagging these challenges. However, according to recent internal briefings and public statements from company executives, Meta now believes artificial intelligence systems can assume the majority of these responsibilities with greater efficiency, consistency, and at scale.
This shift is not without precedent. Tech giants across the industry have been steadily expanding the use of AI to automate complex processes previously handled by human decision-makers. Whether it is content moderation, ad targeting, or cybersecurity detection, machine learning algorithms have proven their capability to operate faster and with fewer resource constraints than human analysts. Meta’s latest move, however, pushes the envelope even further—suggesting that AI can replace human judgment not just in operational tasks, but in areas requiring moral reasoning and ethical discernment.
At the heart of this transition is Meta’s growing portfolio of large language models (LLMs), computer vision systems, and behavior analysis engines trained on billions of data points gathered across its platforms. These systems are being fine-tuned to identify patterns associated with potential privacy breaches, discriminatory outcomes, and adverse societal consequences long before they reach public scrutiny. Meta claims that these tools offer a more proactive and data-driven approach to risk evaluation—one that mitigates the bottlenecks and inconsistencies traditionally associated with human-led review processes.
Yet, the decision to place machines at the helm of risk evaluation raises several thorny questions. Can algorithms truly comprehend the nuanced cultural, ethical, and social implications of digital content and platform design? Are AI systems transparent and accountable enough to make decisions that affect the rights and well-being of billions of users? What happens when these systems fail—or worse, when they inherit the same biases they were intended to eliminate?
Meta’s announcement arrives at a time of heightened scrutiny over the power and reach of Big Tech. Policymakers in the European Union, the United States, and several other jurisdictions are ramping up efforts to regulate AI-driven systems, especially those that exert influence over public opinion, personal data, and democratic institutions. Advocacy groups and independent watchdogs have expressed concern that removing humans from the equation could lead to a vacuum in ethical oversight and exacerbate existing accountability challenges.
Moreover, this initiative reflects a deeper philosophical shift occurring within Silicon Valley: the belief that machines, with enough data and computational power, can effectively model—and perhaps even replace—human judgment in complex, value-laden domains. This techno-solutionist mindset, while seductive in its promise of scalability and objectivity, risks undermining the very social contracts that technologies are meant to uphold.
As Meta pushes forward with its AI transition, the implications will reverberate far beyond its own platforms. If successful, the move could set a new standard across the tech industry, encouraging other firms to adopt similar practices. If unsuccessful, the consequences could be severe—ranging from erosion of public trust to new regulatory crackdowns and reputational damage.
This blog post seeks to explore Meta’s decision in depth, examining the motivations behind it, the technical infrastructure supporting it, and the broader ethical and societal implications. In the sections that follow, we will first analyze why Meta believes replacing human reviewers with AI is a strategic imperative. We will then examine the specific technologies underpinning this shift, followed by a discussion of the regulatory and social impact landscape. Finally, we will assess whether AI is truly capable of assuming the mantle of ethical arbiter in the digital age—or whether it is simply a convenient shield against human accountability.
Through this exploration, we aim to address a central question confronting the intersection of technology and society: As AI becomes more capable, should it also become more responsible—or must responsibility always remain a uniquely human endeavor?
Why Meta Is Replacing Human Reviewers: Motivations and Mechanisms
Meta’s decision to replace human reviewers with artificial intelligence in evaluating privacy and societal risks is not a sudden departure from its broader strategic direction but rather a calculated extension of ongoing automation efforts. To understand this shift, one must look at both the operational pressures facing the company and the ideological foundations driving its leadership. The motivations are multilayered—spanning economic, technological, and reputational considerations—and reveal a systemic attempt to reconfigure oversight in a way that aligns with Meta’s aspirations to scale, control, and depersonalize risk management.
Efficiency and Scale in Risk Assessment
One of the primary motivators for this transition lies in Meta’s need to scale its risk assessment infrastructure. With over 3.1 billion users across its suite of platforms—Facebook, Instagram, WhatsApp, and Threads—Meta is inundated with content and user interactions every second. Human reviewers, despite their training and contextual awareness, are inherently limited in capacity. They can only process a finite volume of material and often require more time to deliberate on complex ethical scenarios. By contrast, AI systems promise near-instantaneous evaluation across enormous data sets, enabling real-time interventions and predictive monitoring at levels no human team could sustain.
From a cost-benefit perspective, automation appears attractive. Human moderation and assessment teams are expensive to maintain—not just in salaries but also in terms of infrastructure, training, emotional toll, and litigation risk (as evidenced by past lawsuits from content moderators experiencing psychological trauma). By replacing these roles with machine learning systems, Meta can theoretically reduce operational overhead and streamline workflows across its Trust and Safety, Legal, and Product teams.
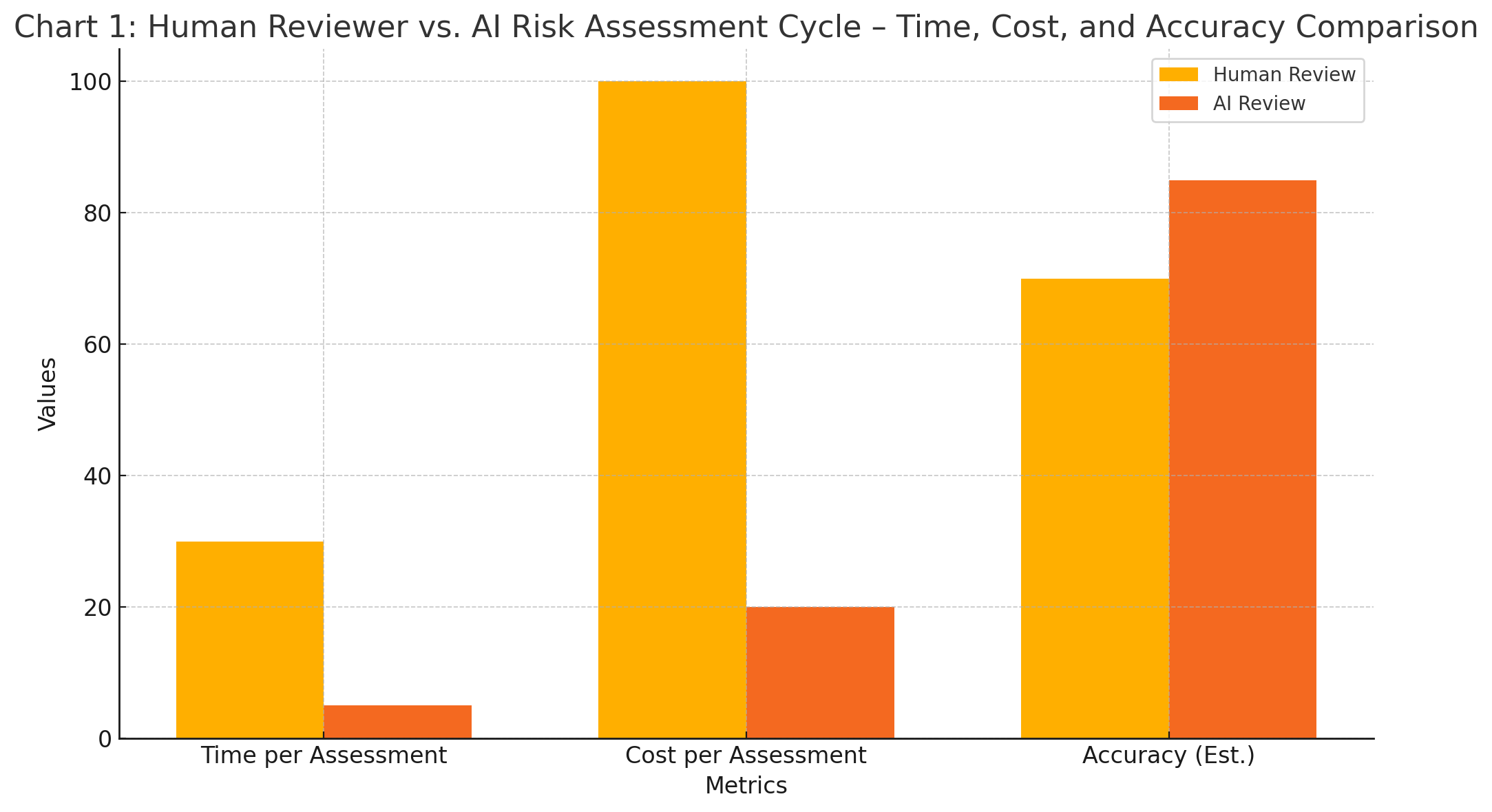
This chart illustrates Meta’s rationale for AI adoption by comparing human and AI performance in terms of processing time, operational cost, and projected accuracy.
Perceived Objectivity and Consistency
Another motivation Meta cites is the pursuit of consistency in risk evaluation. Human judgment, while contextually rich, is vulnerable to cognitive bias, fatigue, and cultural subjectivity. In global operations, what may be deemed acceptable or offensive in one region could be perceived entirely differently in another, creating inconsistency in policy enforcement and risk assessments. AI, Meta argues, can apply the same rules and pattern recognition logic across borders without deviation—producing outcomes that are more predictable and seemingly impartial.
This argument, however, rests on the controversial premise that algorithmic decisions are inherently neutral—a claim that has been challenged extensively by scholars and civil rights organizations. Nevertheless, the appearance of fairness and predictability remains a compelling rationale for corporate deployment, particularly when the goal is to defend practices in regulatory hearings or investor briefings.
Reputational Damage Control and Risk Mitigation
Meta has faced intense scrutiny for its handling of privacy violations, political misinformation, and algorithmic amplification of harmful content. The Cambridge Analytica scandal, the revelations from whistleblower Frances Haugen, and the repeated failures to curb election interference have significantly eroded public trust. In response, the company has faced mounting regulatory pressures from the European Union, the Federal Trade Commission (FTC), and data protection authorities worldwide.
By shifting to AI-led risk assessment, Meta hopes to demonstrate that it is adopting a proactive and technologically sophisticated approach to governance. Framing the move as part of a commitment to cutting-edge oversight allows the company to shape the narrative—presenting AI as a more dependable guardian of compliance and ethical standards. In turn, this can serve as a public relations buffer in future crises, with Meta able to point to its “intelligent systems” as evidence of due diligence.
Political and Regulatory Calculations
Automation of ethical and risk-related tasks also functions as a strategic defense mechanism against expanding regulatory frameworks. Governments around the world are contemplating or enacting AI regulations that demand explainability, human oversight, and accountability. By investing heavily in AI systems designed for interpretability and auditability, Meta positions itself as a cooperative stakeholder in regulatory dialogue—one that is not resisting regulation, but rather anticipating and integrating it into its infrastructure.
Furthermore, by internalizing the risk-assessment process through proprietary AI models, Meta minimizes the need for external consultants, public interest groups, or even regulatory auditors to play an active role. This centralized approach ensures that risk evaluations are done on Meta’s terms, under Meta’s methodologies, and with Meta’s internal benchmarks—thus preserving strategic autonomy while outwardly complying with emerging governance frameworks.
Internal Organizational Realignment
Internally, the AI-driven overhaul also aligns with broader cultural and organizational shifts within Meta. Under the leadership of CEO Mark Zuckerberg and Chief AI Scientist Yann LeCun, the company has increasingly championed AI-first development strategies. From generative models like LLaMA to sophisticated recommender systems and vision-language tools, Meta’s technological roadmap hinges on leveraging AI to drive growth, improve safety, and deliver personalized user experiences.
This cultural shift has reoriented hiring, budgeting, and infrastructure decisions toward centralized AI teams and away from traditional risk or ethics departments. In this context, replacing human reviewers with AI is not just a technological transition—it is an institutional repositioning. It consolidates decision-making under fewer technical leaders while aligning risk mitigation more closely with engineering, rather than legal or ethical, perspectives.
Technical Mechanisms of Implementation
Meta’s approach is not limited to a single model or tool but is instead a layered system of AI technologies working in concert. This includes:
- Natural Language Processing (NLP) systems for scanning textual content and identifying sensitive or polarizing language patterns.
- Computer Vision models that can detect visual privacy breaches, such as the unintentional inclusion of faces, location data, or biometric identifiers.
- Behavioral Prediction Engines trained on historical data to anticipate user reactions, flag potential backlash, and simulate societal impact scenarios.
- Reinforcement Learning from Human Feedback (RLHF) pipelines to fine-tune ethical behavior in large language models based on past reviewer decisions.
These systems are integrated through Meta’s internal AI platform, PyTorch, and are subject to real-time calibration through user feedback loops and incident response audits. In theory, this creates a semi-autonomous mechanism of risk assessment—one that Meta claims is continually evolving to adapt to platform changes and social dynamics.
Limitations and Strategic Blind Spots
Despite the company’s enthusiasm, several limitations undermine the wholesale transition to AI-led risk evaluation. AI models trained on historical data risk replicating the very biases they were meant to correct. Moreover, without transparency into how these models make decisions, external stakeholders cannot evaluate their fairness, relevance, or proportionality. The assumption that AI can fully understand nuanced, cultural, or ethical dimensions remains highly contestable—raising the possibility that AI-driven assessments may overlook emergent harms or misinterpret intent.
In conclusion, Meta’s motivations for replacing human reviewers are rooted in a complex interplay of efficiency, reputational management, regulatory navigation, and organizational ideology. While the company portrays AI as a superior tool for risk detection and mitigation, this framing may obscure the deeper risks inherent in removing human judgment from decisions that carry profound societal consequences.
Technical Deep Dive: How Meta’s AI Models Assess Risk
As Meta transitions from human-led evaluations to AI-driven governance, the underlying technology stack assumes critical importance. Understanding how Meta’s AI systems assess privacy and societal risks requires examining the architecture, model design, data sources, and functional integrations that support this automation. These systems are not simply reactive classifiers but complex, multi-layered platforms trained to detect patterns, predict potential harm, and simulate user impact across a massive global scale.
This section provides a comprehensive breakdown of the core components and operational workflows Meta relies on to automate risk assessment. It explores the specific models employed, the input data pipelines that feed them, and the validation techniques used to fine-tune their outputs. By doing so, we can assess both the promise and the limitations of using AI to govern ethical and societal dimensions in platform ecosystems.
The Architecture: Multi-Modal Risk Evaluation Systems
Meta’s AI infrastructure for risk assessment is built upon a modular and multi-modal architecture. This includes:
- Natural Language Processing (NLP) systems for textual data analysis,
- Computer Vision models for image and video interpretation,
- Graph-Based Network Models for tracking behavioral and social propagation, and
- Reinforcement Learning from Human Feedback (RLHF) to guide ethical calibration.
All of these components are deployed within Meta’s proprietary AI development environment, largely supported by PyTorch—a deep learning framework co-developed by Meta’s AI Research Lab (FAIR). These systems interact through orchestration layers that continuously aggregate user data, monitor engagement patterns, and feed results into internal dashboards used by policy, legal, and product teams.
The models are designed to function in real-time, operating on low-latency inference pipelines. In practice, this means privacy and societal risk evaluations are embedded directly into user-facing workflows, including content sharing, ad delivery, recommendation engines, and privacy controls.
Natural Language Processing and Textual Risk Detection
One of the most mature domains of Meta’s AI governance suite is natural language processing. These systems rely on large language models (LLMs) derived from internal families such as LLaMA (Large Language Model Meta AI), which are trained on vast multilingual corpora scraped from the public web, user interactions, and historical moderation decisions.
The models perform:
- Named Entity Recognition (NER) to identify sensitive personal information,
- Sentiment Analysis to gauge emotional tone and potential social volatility,
- Topic Modeling to detect controversial or policy-relevant subject matter, and
- Toxicity Classification to flag hate speech, harassment, or disinformation.
Meta’s NLP stack is further tuned with RLHF, wherein human reviewers previously flagged certain outputs as ethical violations. These judgments are used as feedback signals to align the model’s predictions with normative human values, such as fairness, dignity, and cultural respect. This tuning process is iterative and conducted on a rolling basis, particularly when geopolitical events or policy changes alter the risk landscape.
However, challenges persist. LLMs can exhibit hallucinations, misclassify idiomatic or culturally nuanced speech, and struggle with intent interpretation—particularly in satire, irony, or context-dependent humor. Therefore, Meta employs ensemble methods where model outputs are cross-referenced against rule-based heuristics and third-party evaluation frameworks to reduce false positives and negatives.
Computer Vision and Visual Privacy Protection
In addition to textual data, Meta’s platforms generate enormous quantities of visual content. To assess privacy and societal risks in photos, livestreams, and videos, the company deploys computer vision models that rely on convolutional neural networks (CNNs), vision transformers (ViTs), and multimodal fusion techniques.
These models conduct:
- Facial Recognition and Redaction to protect biometric identifiers,
- Geolocation Estimation based on visual cues in the background,
- Nudity and Graphic Content Filtering to enforce content standards, and
- Contextual Inference to determine whether visual media implies consent violations or cultural insensitivity.
For instance, a photo containing children in school uniforms might trigger higher scrutiny depending on the inferred location and audience exposure. Similarly, live video streams may be analyzed in real time for emergent violence or coordinated behavior.
Importantly, Meta claims to use differential privacy techniques and federated learning mechanisms to ensure that user content is not individually identifiable during the training phase. However, critics remain skeptical about the degree to which privacy-preserving claims can be independently verified.
Behavioral Prediction and Societal Impact Simulations
One of the more sophisticated and contentious components of Meta’s AI risk stack involves behavioral prediction engines. These systems are trained on user interaction data—likes, shares, watch time, comment threads—to build probabilistic models of how content is likely to influence public opinion or social dynamics.
The objective is to detect:
- Polarizing Content Amplification that might deepen ideological divides,
- Algorithmic Bias Effects where certain groups are marginalized or stereotyped,
- Misinformation Spread Trajectories, and
- Psychological Harm Metrics, especially for adolescents and vulnerable groups.
Meta integrates these forecasts into internal decision-making tools like “Integrity Risk Scorecards,” where content or feature rollouts are pre-emptively modeled for ethical implications. These simulation environments borrow techniques from causal inference, agent-based modeling, and reinforcement learning to test different engagement scenarios before features are globally deployed.
While technically impressive, these models also raise concerns of algorithmic paternalism—wherein Meta not only curates what users see but also pre-determines what users ought to feel or think. This creates a tension between predictive accuracy and user autonomy.
Training Data, Auditing, and Governance Layers
The quality of Meta’s risk assessment AI systems ultimately depends on the data they are trained on. Meta curates its training datasets from:
- Public datasets like Wikipedia, Common Crawl, and OpenSubtitles,
- Platform-specific logs from past moderation and user reports, and
- External incident data including public policy outcomes and press coverage.
To mitigate bias, the company conducts algorithmic audits, often involving third-party research labs and university partnerships. These audits review metrics such as false positive rates across demographics, fairness in content suppression, and cross-cultural interpretability.
Internally, a system known as “Fairness Flow” is used to test how AI decisions distribute across race, gender, language, and geography. Any discrepancies are flagged for intervention. However, the audit results are rarely made public in full, limiting transparency and external accountability.
Integration with Human Oversight
Despite the goal of replacing human reviewers, Meta continues to employ hybrid human-in-the-loop systems in high-risk cases. These include:
- Election-related content in politically volatile regions,
- Crisis response during natural disasters or acts of terrorism, and
- Escalations involving sensitive legal rights such as copyright or libel.
In these cases, AI acts as a first-line filter, while human experts provide contextual adjudication. This dual-layer system is positioned as a transitional model until Meta achieves sufficient confidence in full automation.
Technical Limitations and Future Roadmap
While Meta’s AI systems are arguably among the most advanced in the private sector, they remain imperfect. Limitations include:
- Inability to fully understand cultural nuance,
- Propagation of systemic bias from historical training data,
- Lack of explainability in complex model decisions, and
- Vulnerability to adversarial manipulation or gaming by malicious actors.
To address these challenges, Meta is investing in next-generation research areas like explainable AI (XAI), zero-shot ethical reasoning, and consensus-based evaluation frameworks—where model decisions are benchmarked against collective human judgment rather than singular metrics.
In summary, Meta’s AI-driven risk assessment is underpinned by a technically robust yet ethically complex system of interlinked models and predictive engines. While these technologies enable unprecedented scale and automation, they also introduce new layers of opacity, bias, and algorithmic authority—raising critical questions about the tradeoffs society must confront as human judgment is increasingly encoded into machines.
Implications for Society, Regulation, and Human Rights
Meta’s decision to transfer privacy and societal risk assessments from human analysts to artificial intelligence represents more than a technological transformation—it marks a profound realignment in the relationship between private enterprise, individual rights, and democratic oversight. As the company expands the scope of algorithmic governance, it raises urgent questions about transparency, accountability, and the preservation of fundamental human rights in a digital ecosystem increasingly shaped by opaque, data-driven systems.
This section explores the broader societal consequences of Meta’s AI-first approach, examines emerging regulatory challenges, and evaluates the potential erosion of key human rights principles. It also highlights growing global concern among civil society actors, academics, and policymakers over the ethical legitimacy and long-term viability of delegating moral and legal reasoning to machines.
Social Ramifications of Machine-Led Risk Assessment
Meta’s platforms reach over three billion users globally, influencing public opinion, civic engagement, consumer behavior, and mental health. Replacing human reviewers with artificial intelligence in assessing content-related risk and platform design decisions introduces systemic implications that ripple far beyond product performance.
At a societal level, AI-led systems could normalize a new standard of automated ethics—where values are inferred from data patterns and risk is measured via engagement-based proxies rather than lived human experience. This shift risks abstracting the deeply human dimensions of social interaction, culture, and identity into numerical models optimized for efficiency rather than empathy.
For example, AI may flag a post as safe based on lack of prior escalation, despite it promoting harmful stereotypes that would be contextually apparent to a human reviewer. Conversely, AI may wrongly suppress content critical of oppressive regimes due to keyword associations, disproportionately affecting marginalized voices in politically sensitive environments. Such dynamics raise the specter of algorithmic censorship and the suppression of legitimate speech under the guise of safety optimization.
Moreover, reliance on algorithmic systems creates an illusion of objectivity. Users may perceive machine decisions as neutral, when in fact they are driven by datasets infused with historical biases, annotation errors, and Western-centric norms. This challenges pluralism and inclusivity in online spaces—foundational values for any democratic digital society.
The Accountability Vacuum
Replacing human judgment with AI further complicates the chain of accountability in content governance and risk mitigation. In the past, errors in judgment could be traced to human reviewers, flagged for retraining, or escalated to legal departments. In an AI-led model, responsibility becomes diffused across layers of code, data selection, model parameters, and system design decisions—many of which remain inaccessible to external scrutiny.
This diffusion of responsibility is especially troubling in high-stakes decisions, such as those involving elections, civil unrest, or targeted harassment campaigns. When errors occur—whether wrongful censorship, overlooked threats, or discriminatory targeting—users are often left without a clear channel for redress. Meta can claim the decision was algorithmic, while simultaneously withholding the model’s reasoning as proprietary information.
In effect, the platform becomes both judge and black-box executioner. This undermines due process, a cornerstone of human rights law, and weakens institutional trust in both the platform and broader digital governance norms.
Regulatory Complexity and Global Legal Tensions
The deployment of AI for societal and privacy risk assessment intersects with an evolving landscape of regional and international regulation. In the European Union, the AI Act classifies systems that influence human behavior or affect fundamental rights as “high-risk.” Such systems must undergo extensive transparency audits, risk documentation, and human oversight. Meta’s AI risk assessment tools could fall squarely into this category, prompting stricter scrutiny and potential legal liabilities.
Similarly, the General Data Protection Regulation (GDPR) requires that data subjects have the right to obtain meaningful information about automated decisions that significantly affect them. This provision is directly challenged by Meta’s opaque and complex models, particularly when the reasoning behind decisions cannot be easily explained—even internally.
In the United States, legal frameworks like Section 230 of the Communications Decency Act shield platforms from liability for user-generated content. However, with the growing reliance on AI, courts may soon have to confront whether algorithmic recommendations or risk assessments constitute editorial functions, thereby altering legal exposure for platforms like Meta.
In jurisdictions with weaker legal protections, the risks are even more acute. Governments may pressure Meta to tweak its AI systems for political compliance, censorship, or surveillance, knowing that such decisions can be concealed within algorithmic operations. In the absence of external audits or independent watchdog access, Meta’s AI-driven systems risk becoming tools of political influence rather than neutral guardians of societal welfare.
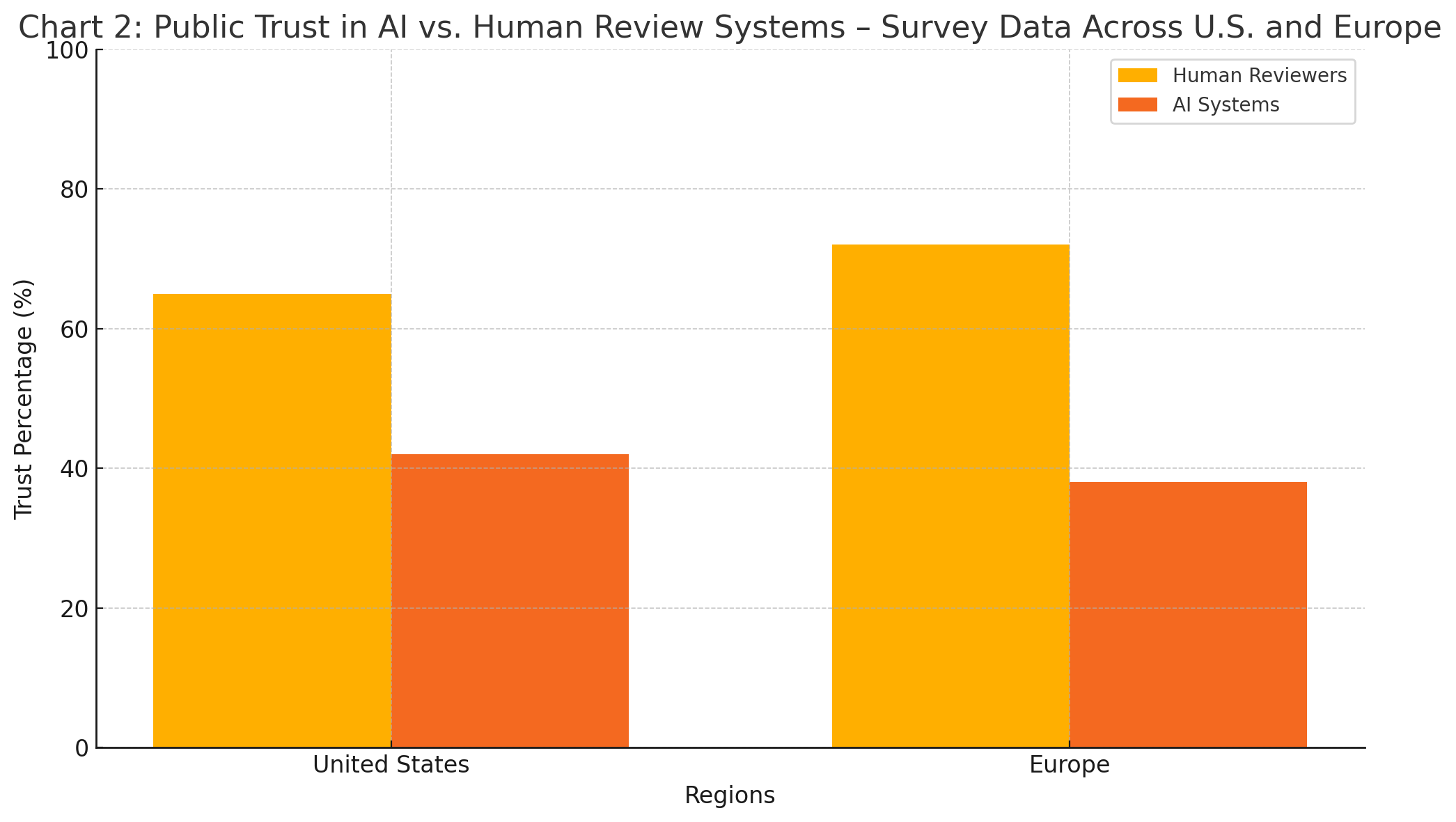
This chart illustrates regional differences in public confidence, revealing significantly higher trust in human reviewers compared to AI systems for risk and content oversight.
Civil Society and Public Response
Civil society organizations, academics, and digital rights advocates have expressed mounting concern over the ethical implications of Meta’s AI transition. Groups such as Access Now, the Electronic Frontier Foundation, and AlgorithmWatch argue that machine-led risk assessments:
- Lack adequate transparency and appeal mechanisms,
- Perpetuate systemic inequality through training data biases,
- Inhibit democratic participation and dissent, and
- Encourage a technocratic form of governance divorced from social realities.
Whistleblowers from within Meta have echoed these concerns. Former employees involved in policy and integrity teams have noted that ethical considerations are often overridden by business imperatives—especially when AI models suppress user engagement or raise friction in advertising delivery.
This tension highlights a critical paradox: while AI risk models are ostensibly designed to improve platform safety, they may be quietly optimizing for corporate liability reduction rather than societal benefit. The opacity surrounding performance benchmarks, false positive rates, and cross-cultural fairness only deepens public skepticism.
Human Rights at Risk: Autonomy, Privacy, and Expression
At the core of the issue lies a set of human rights that may be imperiled by overreliance on AI governance systems:
- Autonomy: Users have a right to make informed decisions about their interactions and the content they encounter. When AI filters content or alters engagement pathways invisibly, this autonomy is subtly undermined.
- Privacy: Meta’s models require vast datasets to operate effectively, often relying on inferred behavior and sensitive metadata. Even if anonymized, the aggregation of such data may create predictive profiles that intrude upon users’ privacy rights under both ethical and legal standards.
- Freedom of Expression: AI moderation models may err on the side of caution, leading to over-blocking or shadow banning of dissent, satire, or minority perspectives. Without clear appeals processes or explanations, users are left in a state of digital disenfranchisement.
The universal declaration of human rights—and numerous international treaties—place a high premium on protecting individual freedoms. Delegating ethical oversight to algorithms without human context or cultural fluency risks eroding these protections at scale.
Toward a Framework of Algorithmic Accountability
Given the scale and influence of Meta’s platforms, calls are growing for the establishment of robust accountability frameworks that can guide the use of AI in societal governance. Key proposals from regulators and academic institutions include:
- Mandatory Algorithmic Impact Assessments before deployment of high-risk systems,
- Independent third-party audits of AI fairness, privacy safeguards, and effectiveness,
- Right to explanation provisions for users impacted by AI-driven decisions,
- Public registries of automated decision systems, and
- Multi-stakeholder governance bodies with representation from civil society, academia, and underrepresented communities.
Such frameworks are not merely regulatory hurdles; they represent essential safeguards for preserving public trust, democratic norms, and ethical consistency in the face of algorithmic dominance.
In summary, the societal, regulatory, and human rights implications of Meta’s AI-led risk assessment strategy are vast and complex. While automation offers scalability and consistency, it introduces new risks of accountability voids, censorship, and structural discrimination. As AI assumes a central role in platform governance, the need for transparency, oversight, and human-centered design becomes not just a recommendation—but a moral imperative.
Can AI Be the Guardian of Human Values
Meta’s bold initiative to entrust artificial intelligence with the critical function of assessing privacy and societal risks marks a significant evolution in the governance of digital platforms. As this blog has explored, the motivations behind this transition are rooted in operational scalability, cost-efficiency, and a corporate vision that elevates AI as the next frontier of platform management. Yet, beyond the immediate gains in speed and consistency lies a complex, and in many respects unsettling, set of questions regarding the future of ethical oversight, public accountability, and the preservation of human values in algorithmically mediated environments.
The central question that emerges—can AI be the guardian of human values?—deserves careful examination. On one hand, the sheer volume of data and interactions on Meta’s platforms necessitates systems that can operate at machine speed. AI systems offer the potential to detect and preempt harm more quickly than human reviewers, and they can analyze vast behavioral patterns across languages, regions, and formats in ways that human teams cannot feasibly match. From a technical standpoint, the move appears rational and forward-thinking.
However, risk assessment is not merely a technical task. It is a fundamentally normative endeavor, involving the interpretation of meaning, the weighing of competing values, and the exercise of judgment in ambiguous, context-sensitive situations. Privacy, fairness, discrimination, and societal impact cannot be reduced to quantifiable data points alone—they are deeply human concerns, grounded in culture, history, and ethical reasoning. When AI systems are trained on historical data and feedback loops optimized for platform interests, they risk encoding a narrow, corporate-centric interpretation of what constitutes “acceptable” or “safe” behavior online.
Furthermore, AI systems, as powerful as they are, remain constrained by their design, their data, and the objectives they are programmed to serve. They do not possess consciousness, empathy, or moral intuition. They can simulate ethical behavior, but they cannot understand ethics. This distinction becomes critically important when algorithms are making decisions that affect freedom of expression, political discourse, or the psychological well-being of vulnerable populations.
The risk is that we begin to treat AI decisions as inherently objective, when in reality they are the product of subjective judgments—made by engineers, product managers, and executives—about how the system should behave. The delegation of ethical responsibility to machines, no matter how sophisticated, risks creating an accountability vacuum that can be exploited, whether intentionally or inadvertently, to serve institutional interests over societal good.
Moreover, Meta’s AI-led model, while technologically advanced, remains largely insular and opaque. Its design, deployment, and ongoing evaluation occur within the confines of a private company with significant commercial incentives to avoid regulatory entanglements and reputational risk. Without robust mechanisms for external oversight, algorithmic audits, and public transparency, the use of AI for societal governance remains susceptible to both technical failure and ethical drift.
Importantly, the global nature of Meta’s platforms introduces additional complexity. What constitutes harm or risk in one region may not align with norms or expectations in another. The cultural blind spots of AI systems—particularly those trained predominantly on Western-centric datasets—can result in misjudgments that disproportionately affect users in the Global South, minority communities, and politically sensitive contexts. This raises urgent concerns about digital colonialism, where the ethical standards of a few are encoded and exported to billions without consent or recourse.
Yet, despite these significant limitations, AI does not have to be categorically excluded from risk assessment functions. The key lies in redefining the role of AI—not as a replacement for human judgment, but as a complement to it. AI can enhance human oversight by surfacing patterns, detecting anomalies, and streamlining routine assessments. It can function as a decision-support tool, providing valuable insights that help human experts make more informed, consistent, and equitable determinations.
For this to be viable, however, several foundational principles must be embraced:
- Human-in-the-Loop Governance: AI risk assessments must be reviewed and verified by trained human experts, particularly in high-stakes scenarios.
- Transparency and Explainability: Meta must open its models, data sources, and decision logs to independent review so that stakeholders can understand how assessments are made and challenge them when necessary.
- Inclusive Design and Local Context: AI systems must be co-developed with input from diverse cultural, linguistic, and geopolitical perspectives to ensure contextual sensitivity.
- Accountability Mechanisms: When harm occurs as a result of an AI decision, there must be clear lines of accountability and accessible avenues for user recourse.
- Regulatory Alignment: Meta must proactively work with regulators to ensure that its AI systems comply not only with technical standards, but with human rights frameworks and democratic principles.
If these conditions are met, it may be possible to develop AI systems that genuinely reflect and uphold human values—though never perfectly, and never without the need for continual human oversight. The promise of AI lies not in its autonomy, but in its capacity to augment human ethics with scale, precision, and consistency—under the careful guidance of those who remain ultimately responsible.
The conversation must now shift from whether AI should be used in this domain, to how it can be used responsibly, inclusively, and transparently. Governments, civil society, technologists, and users must collaborate to shape a new model of AI governance that places human dignity at the center. Only then can we begin to answer the question of whether AI can truly serve as a steward of human values.
In the case of Meta, the path forward is clear but challenging. It must balance innovation with restraint, automation with deliberation, and efficiency with ethics. As AI continues to evolve, so too must our frameworks for its integration into the public sphere. The future of digital society depends not only on what AI can do, but on what we allow it to decide—and what we, as humans, are willing to retain responsibility for.
References
- Meta – About Artificial Intelligence
https://about.fb.com/news/tag/artificial-intelligence/ - Stanford HAI – Governance of AI
https://hai.stanford.edu/policy-briefs/governing-responsible-ai - Electronic Frontier Foundation – Algorithmic Accountability
https://www.eff.org/issues/algorithmic-accountability - EU AI Act Overview
https://artificialintelligenceact.eu/ - AlgorithmWatch – Automated Decision-Making
https://algorithmwatch.org/en/project/automated-decision-making/ - Access Now – Human Rights and AI
https://www.accessnow.org/issue/artificial-intelligence/ - OECD – AI Principles and Policy
https://oecd.ai/en/ai-principles - Partnership on AI – Risk Mitigation Frameworks
https://partnershiponai.org/ - World Economic Forum – The Ethics of AI
https://www.weforum.org/agenda/archive/ethics-of-ai/ - Future of Privacy Forum – AI and Privacy
https://fpf.org/areas-of-focus/artificial-intelligence/