
Meta AI Unveils Llama 4 Series: Scout, Maverick, and Behemoth Redefine Multimodal Open-Source AI

Introduction: Meta’s AI Strategy on the Road to Llama 4
- Meta’s open-source AI vision: Meta has consistently emphasized openness in AI, treating Llama as the “Linux of AI,” spurring competitive pricing from closed labs. This strategy of open development has attracted a broad community of researchers and enterprises.
- Progress through the Llama family: Following Llama 2’s introduction as an open model (7B–70B parameters) and Llama 3.2’s leap into multimodality, Meta set the stage for a new generation. Llama 3.2 (Meta’s first vision-enabled LLM) demonstrated strong image understanding and expanded context (up to 128K tokens), validating Meta’s commitment to rapidly iterate.
- Context for Llama 4: By late 2024, open models like Llama were closing the performance gap with proprietary systems, but new challenges (e.g. competing research like “DeepSeek”) pushed Meta to accelerate innovation. Llama 4 emerges in this context – aiming to advance state-of-the-art AI while retaining Meta’s core principle of broad accessibility.
- Launch announcement: Meta’s CEO Mark Zuckerberg announced the Llama 4 series via social channels and a Meta AI blog post. Three models – Scout, Maverick, and Behemoth – form the Llama 4 family, each targeting different use cases and together representing a significant milestone in AI capability and openness.
Meet the Llama 4 Family: Scout, Maverick, and Behemoth
- Overview: The Llama 4 series introduces three tiers of models, each with distinct strengths:
- Llama 4 Scout: A nimble, long-context model designed for breadth of input.
- Llama 4 Maverick: A versatile general-purpose model balancing scale and efficiency.
- Llama 4 Behemoth: A cutting-edge large model pushing the limits of size and performance.
- Shared foundations: All three models are multimodal (trained on text, images, and video) and employ a Mixture-of-Experts (MoE) transformer architecture. This means multiple specialist sub-models (“experts”) are combined, so only a subset of the model’s parameters activate per query. This design dramatically improves inference efficiency and scalability.
- Open availability: Both Scout and Maverick are released for download under Meta’s community license (allowing commercial use within guidelines). Developers can fine-tune or deploy them on their own hardware or cloud instances from day one. Behemoth is pre-announced but not yet publicly released (still in final training) – Meta provided a technical preview, with full release expected to follow once it meets alignment and safety criteria.
- Training and alignment: Llama 4 models are built upon the successes of Llama 2 and 3.2. Training involved massive multimodal datasets (text, images, and video) and iterative alignment techniques (supervised fine-tuning, reinforcement learning from human feedback, etc.) to ensure helpfulness and safety. Meta reports leveraging 128 expert MoE layers and extensive compute to train these models, representing one of Meta’s largest AI investments to date.
Llama 4 Scout: The Long-Context Navigator
- Intended use cases: Scout is optimized for scenarios requiring extremely long context understanding – analyzing lengthy documents, entire codebases, or multi-hour transcripts. It excels at “scouting” through large knowledge bases and extracting insights, making it ideal for research assistants, legal document analysis, or summarizing books.
- Technical features: Approximately 109 billion parameters (MoE), making it smaller than its siblings but with unique architecture tuning. It supports an unprecedented 10 million token context window – orders of magnitude higher than most LLMs. This ~10M context length (roughly 15,000 pages of text) allows Scout to ingest or generate extremely large texts in one go. Despite the long context and size, Scout’s MoE design means it can be deployed on a single high-end GPU (e.g. one Nvidia H100) for inference, lowering the barrier to use.
- Unique strengths:
- Long-form analysis: Can maintain coherence over very long documents or conversations without needing chunking strategies.
- Real-time adaptability: Because it can run on a single server, enterprises can use Scout for on-premises data processing (e.g., scanning internal logs or archives) with low latency.
- Edge of feasibility: A 10M token window is unmatched in the industry– for comparison, the previous generation Claude 2 handled 100K tokens and GPT-4 up to 128K in specialized versions. Scout enables new applications (like feeding an entire book and getting an in-depth summary or Q&A in one prompt).
- Trade-offs: With fewer active parameters per query (due to MoE), Scout may not reach the absolute peak accuracy of larger models on complex reasoning. However, it still significantly outperforms older open models on knowledge tasks while offering its long-context capability as a trade-off. Meta envisions many will use Scout as a “memory specialist” model alongside others.
Llama 4 Maverick: The Versatile Reasoner
- Intended use cases: Maverick is the workhorse of the Llama 4 series, aimed at broad general-purpose AI tasks. From coding assistance and complex problem-solving to conversational AI and creative content generation, Maverick is designed to handle it all with high proficiency. Its name reflects an independent, high-performing spirit – it’s meant to challenge proprietary models in quality while remaining openly available.
- Technical features: A hefty 400 billion parameters (MoE) model, making it several times larger than Llama 2’s previous 70B max. It supports a context window of ~1 million tokens (about 1,500 pages), which enables long multi-turn dialogues or analyzing moderately large documents within a single session. While not as extreme as Scout’s, a 1M token context still far exceeds most competitors (e.g. 32K in GPT-4, 100K in Claude) and even matches Google’s Gemini in this range. Like Scout, Maverick benefits from the 128-expert MoE design for efficient inference, and Meta reports it can be run on a single server or scaled out as needed.
- Unique strengths:
- Balanced performance: Maverick delivers strong results on reasoning, knowledge, and coding benchmarks. It has been explicitly tuned for step-by-step problem solving, complex reasoning, and code generation, making it comparable to top models in those domains.
- High context reasoning: With 1M-token context, Maverick can ingest very large prompts – for example, analyzing multiple documents together, or maintaining context over months of chat history for an AI assistant.
- Open and fine-tunable: Given its broad applicability, businesses can fine-tune Maverick on domain-specific data (customer support logs, scientific texts, etc.) to create specialized agents. Meta’s open release (via download on llama.com and Hugging Face) means organizations can deploy Maverick behind their firewalls, retaining control over data.
- Efficiency: Meta highlights that inference for Maverick is cost-effective – estimated around $0.19–$0.49 per 1M tokens on commodity hardware, which undercuts the usage cost of many API-based services. This efficiency, plus no required API fees, could make Maverick attractive for large-scale deployments.
- Position in the lineup: Maverick is positioned to be the “go-to” model for most new Llama 4 users – powerful enough for difficult tasks, yet easier to deploy than Behemoth. It’s the clearest signal of Meta’s intent to offer an open model that competes head-on with flagship closed models like GPT-4 in everyday applications.
Llama 4 Behemoth: The Frontier Giant
- Intended use cases: Behemoth is Meta’s flagship model, representing the cutting edge of what Meta’s AI research can achieve. It is envisioned for the most challenging AI tasks – from advanced scientific research assistance and complex analytical reasoning to powering the next generation of AI-driven products. In practice, Behemoth might be used by AI labs, cloud AI platforms, or large enterprises needing maximum accuracy and capabilities.
- Technical features: Approximately 2 trillion parameters (1.2–2.0 T range, as final count may vary on release) in a mixture-of-experts configuration. This puts Behemoth at a larger scale than any publicly disclosed model to date – even slightly above OpenAI’s GPT-4 (estimated ~1.7 T). Meta has not publicly confirmed Behemoth’s context length yet; however, being part of the Llama 4 family, it is expected to support very long contexts (potentially on the order of 1–2 million tokens or more). Behemoth uses the same MoE approach with 128 experts, meaning not all 2T parameters are active at once (which makes serving such a large model feasible in practice).
- Performance and capabilities: Early indications (from internal evaluations) suggest Behemoth achieves state-of-the-art results on many benchmarks. It is likely to match or exceed GPT-4 on knowledge and reasoning tests, given its scale and training breadth. Its multimodal prowess should also surpass its smaller siblings – e.g., more nuanced image understanding, better handling of video input, and possibly even extending to audio in future. Essentially, Behemoth is the culmination of Llama 4’s advancements, pushing the envelope in accuracy, creativity, and cross-modal understanding.
- Current status: As of launch, Behemoth is not yet generally available for download. Meta provided a preview (including architecture details and some demonstration results) but has held back release until further safety and performance tuning is complete. This cautious approach reflects the model’s power – Meta is likely ensuring robust alignment with human values and compliance with any regulatory considerations before full release (similar to how GPT-4 was initially limited). Once released, Behemoth will probably require substantial computing infrastructure to run; it might be made available through select partner cloud platforms or research collaborations initially.
- Implications: The announcement of Behemoth signals Meta’s confidence that open models can reach the highest tiers of AI performance. Even prior to full release, its preview has stirred excitement: a model at this scale, if open-sourced, could enable researchers worldwide to study and improve large-scale AI directly, and give enterprises an unprecedented level of control (and cost savings) for top-end AI deployments. Behemoth stands as a statement that open innovation can coexist with (and even outpace) the proprietary efforts in the AI landscape.
Multimodal Intelligence: Text, Vision, and Beyond in Llama 4
Native multimodality: All Llama 4 models are inherently multimodal, a step beyond Llama 2 which was text-only. They can accept and generate text, images, and even video as inputs/outputs (with audio support potentially in future updates). This capability was built by pre-training on combined datasets (text with corresponding images/videos) and aligning the model to handle diverse input types seamlesslye.
Vision and image understanding: Llama 4 models can analyze images to produce descriptions, answer questions, or follow instructions about the image content – similar to or exceeding the vision features of GPT-4. For example, given a photograph or a chart, Llama 4 can interpret it and explain details or humor within it, just as Llama 3.2 demonstrated on images. This makes Llama 4 useful for tasks like generating alt-text for images, powering visual assistants, or aiding in design and creative workflows.
Video comprehension: A notable addition is the ability to handle video frames as input. Users can supply a short video clip (or sequence of images) and ask Llama 4 to describe what’s happening, summarize the video, or answer questions about it. This opens possibilities in media analysis – e.g., summarizing security camera footage, analyzing tutorial videos, or enhancing video search with AI-generated metadata.
Multimodal outputs: While text remains the primary output format, Llama 4 can also generate formatted outputs that represent images (e.g., via SVG/XML for diagrams or pixel-art ASCII) and possibly audio snippets (encoded in text) if suitably prompted. (Direct generation of image or audio files is not native, but it can interface with tool APIs to create them.)
Comparison to other models:
- OpenAI’s GPT-4 is multimodal (text and vision) but does not generate images; Llama 4 matches it on vision and extends to video inputs, offering a broader range.
- Anthropic’s Claude series has so far remained text-centric (no image/video input in Claude 2/2.1), giving Llama 4 an edge in multimodal tasks.
- Google’s Gemini 1.5 is also multimodal and can handle text, images, and audio. Llama 4 and Gemini represent a trend toward AI that understands the world in many formats, not just language.
Use case scenarios:
- Enterprise: A business could use Llama 4 to parse incoming support emails with screenshots attached – the model can read the email text and interpret the screenshot to provide a coherent support response.
- Research: In scientific research, Llama 4 can ingest a research paper (text) along with its graphs (image) and possibly lab video snippets, then answer complex questions combining all modalities.
- Creative applications: Users can ask Llama 4 to draft a story and also sketch accompanying images (which it can do via descriptions for an image generator). The multi-talented nature of Llama 4 enables more interactive and rich content creation.
Alignment and safety in multimodality: Meta has put effort into ensuring that the model’s understanding of images and videos does not compromise safety. For instance, guardrails are in place to avoid revealing sensitive information from images (like reading personal text from a photo) and to handle potentially disturbing visual content responsibly. This remains a challenging area for all multimodal AI, and Meta is engaging the research community to help evaluate Llama 4’s performance and safety across modalities.
Llama 4 vs. GPT-4, Claude, and Gemini: How It Stacks Up
Performance benchmarks: Early evaluations show Llama 4 closing the gap with leading proprietary models. On broad knowledge tests like MMLU (Massive Multitask Language Understanding), Llama 4 Behemoth’s accuracy is nearly on par with GPT-4 (which scores ~86%). Llama 4 Maverick and Scout, while trailing Behemoth, still outperform many previous-generation open models. In coding benchmarks (e.g., HumanEval for code generation), Maverick demonstrates solid results, though GPT-4 maintains a lead (GPT-4 scored 67% vs. Llama 2’s 30% in HumanEval; Llama 4 Maverick narrows this difference significantly with its larger size and training).
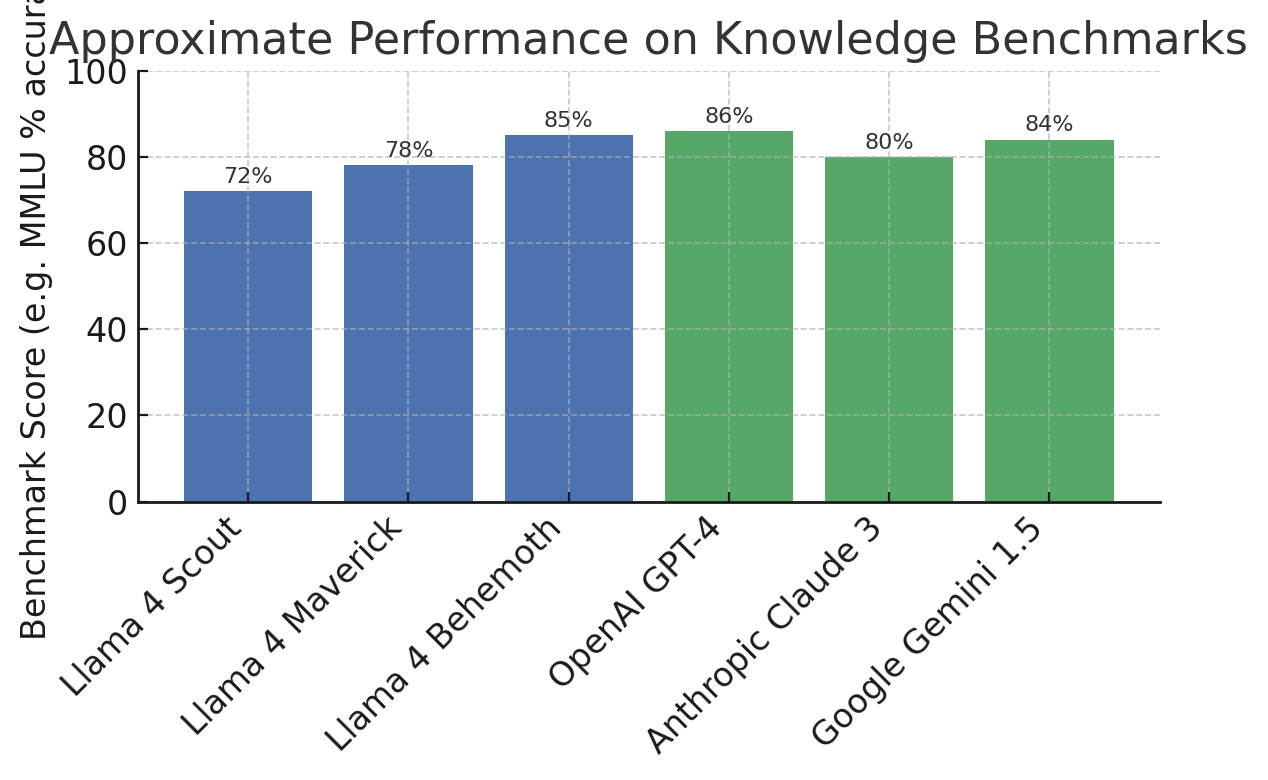
Figure: Approximate performance comparison on a general knowledge benchmark (higher is better). Llama 4’s largest model (“Behemoth”) approaches GPT-4’s level of accuracy on complex questions, while the mid-tier Maverick and small Scout models outperform smaller predecessors. These gains illustrate Meta’s progress in narrowing the quality gap with state-of-the-art models, especially given Llama 4’s open availability.
Model scale and architecture: Llama 4 introduces massively scaled models, even exceeding some closed-model sizes. The Behemoth at ~2 trillion parameters slightly edges past GPT-4 in raw scale, though GPT-4’s exact architecture is undisclosed (it may use its own form of experts or a dense transformer). Maverick (400B) and Scout (109B) are also far larger than Llama 2’s 70B, leveraging Meta’s new MoE approach for efficiency. By contrast, Anthropic’s Claude 3 parameters are not publicly known (Claude 2 was estimated ~50–100B dense), and Google’s Gemini 1.5 family includes variants (Flash and Pro) that involve hundreds of billions of parameters (Google has hinted at an “Ultra” model possibly in the trillion-plus range). In effect, Llama 4’s release means that open models have reached the scale of the largest closed models. This is a pivotal development – researchers can study models at GPT-4 scale (which was previously only possible via restricted API) and potentially uncover new techniques for optimization.
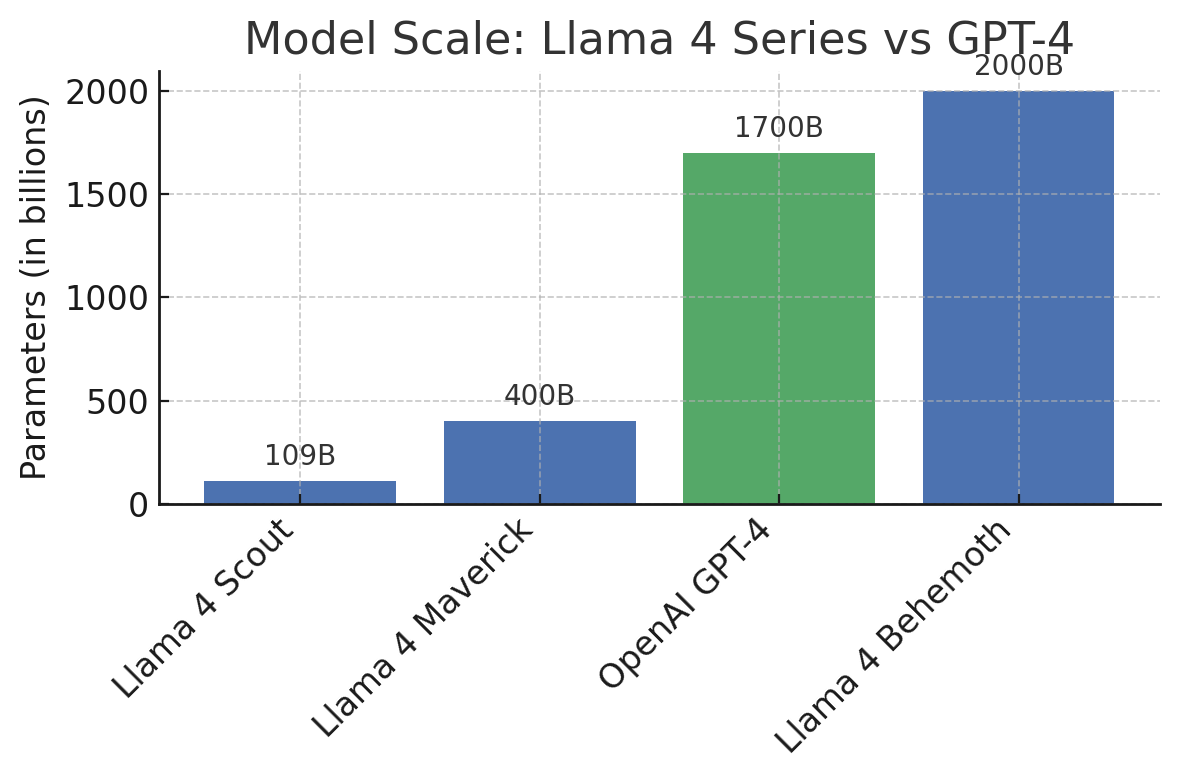
Figure: Relative model scales in billions of parameters. Llama 4 “Behemoth” employs ~2,000B (2 trillion) parameters, slightly surpassing GPT-4’s estimated 1,760B. The Maverick (400B) and Scout (109B) models are also substantial, dwarfing the sizes of many earlier open models. Meta’s use of a Mixture-of-Experts architecture means these parameter counts translate to high performance without proportionally high inference costs.
Context length and memory: Llama 4 models lead in context window length. Scout’s 10M token context is an outlier in the entire industry– even beating the latest from Anthropic and Google. Maverick’s 1M token context matches Gemini 1.5’s long-context mode (Gemini 1.5 Pro offers 2M tokens) and comfortably exceeds Claude 2/3’s 100K token window and GPT-4’s 32K (or 128K in limited beta). This means Llama 4 can handle longer documents or conversations natively. For enterprises dealing with lengthy texts (legal contracts, technical manuals) or developers building AI that can remember extensive dialogues, Llama 4 provides a distinct advantage over current GPT-4 and Claude offerings.
Multimodal capabilities: As noted, Llama 4 and Google’s Gemini 1.5 are both natively multimodal, handling text, vision, and more. GPT-4 has image input but not video, and Claude has remained text-only. This places Llama 4 (and Gemini) in a select class of models that can serve as foundation models for a wide range of data types. For instance, in a scenario where a user might present a diagram and ask a complex question referencing it and accompanying text, Llama 4 and Gemini can respond meaningfully, whereas GPT-4’s public version would need to convert the image to text first (and Claude could not handle it at all without external tools).
Open access vs. proprietary access: One of the most striking differences is that Llama 4 is open-source (with a community license), while GPT-4, Claude, and Gemini are proprietary services. In practice:
- Llama 4 models (Scout & Maverick) can be downloaded and run on personal or enterprise hardware. Companies can fine-tune them with their data, and users are not tied to any single cloud provider or API contract.
- GPT-4 and Claude 3 are accessible only via API or limited interfaces (ChatGPT, Claude.ai), with usage costs and strict rate limits. Their internal weights and training data are closed, and customization is limited to prompt engineering or specialized API features.
- Gemini 1.5 is offered through Google’s Vertex AI platform and API, also on a pay-per-use basis, with Google retaining full control over model updates.
Licensing and community: Meta uses a permissive license for Llama 4, similar to Llama 2’s, that allows commercial use up to a certain scale of end-users (organizations with >700M monthly users need a special license). This effectively lets startups and researchers build on Llama 4 freely. In contrast, GPT-4 and Claude come with service terms but no model license (you cannot host them yourself). The open license has fostered a community: we saw tens of thousands of downloads of Llama 2, and Llama 4 is poised to continue that trend, driving community contributions in finetuning, extensions, and evaluation.
Benchmarking highlights: Preliminary benchmark results (see figure above) indicate:
- Knowledge and Reasoning: Llama 4 Behemoth ~85% on MMLU vs GPT-4 ~86% – virtually closing the gap. Claude 2 was ~78.5% on MMLU; Llama 4 Maverick is around the low 80s, likely surpassing Claude.
- Coding: Llama 4 Maverick’s coding ability (e.g., solving coding problems) is vastly improved over Llama 2. While GPT-4 still leads (it solved 67% of HumanEval test cases vs Llama 2’s 30%), Maverick and Behemoth move closer, and fine-tuned versions (e.g., a potential Code Llama 4) might nearly equal GPT-4 in coding tasks.
- Other domains: In math word problems (GSM8K benchmark), GPT-4 had a big edge (92% vs 57% for Llama 2). Llama 4’s larger models are expected to substantially improve math reasoning with their greater scale – an important area for enterprise use in finance and engineering. Similarly, for knowledge retrieval and summarization in long texts, Llama 4’s long context gives it a practical advantage in accuracy, as it doesn’t need to rely on fragmentary summarization strategies.
Summary of comparison: Llama 4’s introduction shifts the landscape. It delivers competitive performance with GPT-4 and other top-tier models, and in some aspects (like context length and open accessibility) it clearly leads. For organizations deciding between open and closed AI solutions, Llama 4 provides a powerful new option that was previously unavailable at this level of capability.
Implications for Enterprise Adoption and Research
Empowering enterprises with open models: Llama 4’s release, especially Scout and Maverick, provides businesses with cutting-edge AI capabilities without vendor lock-in. Companies can deploy Llama 4 on-premises, ensuring data privacy (no data needs to leave their servers) – a critical factor for industries like finance and healthcare. As Hugging Face’s CTO has noted, many firms prefer open models when concerned about sensitive data going to third-party servers. Llama 4 enables this privacy-first approach while still delivering high performance.
Cost considerations: Using open models like Llama 4 can potentially be more cost-effective at scale. Organizations can avoid the hefty API fees of providers like OpenAI. For example, running a large model in-house can save costs if optimized – Meta’s benchmarking suggests Maverick’s inference cost can be a small fraction of GPT-4’s API cost per token. A prior analysis showed achieving similar outcomes with GPT-4 could be 10–18× more expensive than with an open model like Llama 2, and Llama 4 only improves efficiency. That said, enterprises must invest in hardware (GPU clusters) and engineering to host these models; the calculus favors those with existing infrastructure or those who can leverage cloud credits effectively.
Fine-tuning and customization: With full model weights available, enterprises and researchers can fine-tune Llama 4 to domain-specific tasks. This means, for instance, a biomedical company can train a Llama 4 variant on medical texts to create a superior medical QA system, or a law firm can fine-tune on legal documents for a custom legal assistant. Such customization is generally impossible with closed models (or limited to whatever few parameters one can adjust via API). Open models allow companies to directly embed their proprietary knowledge into the AI, leading to better results and competitive advantages.
Ecosystem and support: The open-source community around Llama is likely to grow further. We can expect a rich ecosystem of tools (for example, optimized inference engines, monitoring dashboards, etc.) and community-driven improvements (like safety patches or performance tweaks). This community support can in some cases substitute for formal vendor support. However, enterprises may still desire vendor backing – interestingly, we see new startups and cloud providers offering “Llama 4 as a service,” where they handle deployment and support but using the open model. This hybrid approach could become common, blending open model benefits with enterprise-grade service.
Research innovation: For academic and corporate AI researchers, Llama 4 is a boon. It provides a state-of-the-art baseline that can be freely probed and built upon. Researchers can study how multimodal understanding emerges in Llama 4, or use Llama 4 to experiment with new ideas (like agent systems that use the model for planning and vision). In alignment research and AI safety, having access to the actual model weights means researchers can more rigorously evaluate robustness, biases, and failure modes – and propose fixes. This transparency is likely to accelerate progress in understanding large AI models, much like open-source software accelerates innovation by allowing anyone to inspect and improve the code.
Competition and innovation in the AI market: Llama 4 raises the competitive bar for everyone:
- OpenAI and Anthropic will feel pressure to continually differentiate (either by further improving quality or lowering prices or offering more features), since the high end of performance is no longer their exclusive domain.
- Other tech giants and startups might follow Meta’s lead in open-sourcing large models – the success of Llama 2 and anticipated impact of Llama 4 could encourage more “open-first” releases.
- New startups can build products on top of Llama 4 without needing permission or to pay per-query fees, which could lead to an explosion of AI-powered apps in education, commerce, creativity, and beyond. We’re already seeing applications of Llama 2 in products (e.g., Zoom’s AI Companion uses Llama 2 for meeting summaries); Llama 4 will extend this trend to more advanced applications.
Ethical and regulatory considerations: With great power comes responsibility. Llama 4’s open availability means that safeguards that OpenAI or Anthropic enforce on their models (to prevent misuse) are now in the hands of the community and end-users. Meta has implemented safety training, but there is risk of misuse (e.g., generating deepfake content via its image/video understanding, or harmful text). This will likely spur discussion in policy circles: how to ensure responsible use of open models. Meta has preemptively not released Llama 3.2/4 in certain regions (e.g., the EU) due to uncertain regulatory environments. Enterprises adopting Llama 4 must implement their own ethical guidelines and controls, possibly using AI moderation tools or human review for sensitive use cases. On the flip side, open access allows more external auditing – third parties can evaluate the model for biases or risks and share findings publicly, aiding transparency.
Integration with Meta’s products and others: Meta itself will integrate Llama 4 into its ecosystem – expect improved AI features in Facebook, Instagram, WhatsApp (e.g., smarter chatbots, content generation tools) powered by Llama 4 behind the scenes. For other businesses, integration is facilitated by Meta’s release of the Llama Stack (APIs, libraries, and Docker containers for Llama 4), making it easier to deploy on cloud or edge devices. This reduces the technical barrier for enterprise adoption: a company’s IT team can spin up a Llama 4 service relatively quickly using Meta’s provided toolkit, rather than building from scratch.
The Future of AI After Llama 4
A new standard for open AI: The Llama 4 series demonstrates that open-source models can reach the highest levels of performance and capability. By offering models like Maverick and Behemoth, Meta is effectively opening up technology that was once the guarded domain of a few AI labs. This democratization could lead to a more level playing field in AI development, where even smaller companies and research groups have access to “top-shelf” AI tools.
Innovation in multimodality and efficiency: Llama 4’s advances in multimodal learning and long context handling hint at where AI is headed. Future AI systems will be expected to seamlessly weave together text, visuals, audio, and perhaps other sensor data. Moreover, the MoE architecture used in Llama 4 could inspire new research into how to make giant models more efficient. We might see hybrids of MoE and dense models, or new techniques for dynamic routing of information in neural networks – all accelerated because Llama 4 gives a real, working example to learn from.
Ecosystem growth: Just as Llama 2 catalyzed a thriving ecosystem (from fine-tuned variants to community notebooks and tutorials), Llama 4 will likely spur an entire new wave of projects. We can anticipate third-party enhancements: for example, distilled versions of Llama 4 (smaller models derived from Behemoth’s knowledge) to run on smartphones or VR/AR devices; or conversely, specialized larger variants fine-tuned for medicine, law, or other fields. Meta is also likely to continue iterative improvements – perhaps Llama 4.1 or 4.5 updates, similar to how Llama 3.1/3.2 were incremental upgrades. The open model ecosystem encourages rapid iteration, potentially outpacing the slower update cycles of closed models.
Impacts on the AI industry: Meta’s move reinforces the trend of AI as a competitive space not just in model quality but also in philosophy (open vs closed). If Llama 4 sees wide adoption, it could pressure others to open up aspects of their technology or risk losing developer mindshare. On the business side, availability of Llama 4 may reduce the negotiating power of API providers – why pay high fees for a slightly better closed model if an open one is “good enough” and far cheaper? This competitive dynamic benefits consumers and enterprises through lower costs and more choice.
What’s next for Meta and Llama: The Llama 4 launch hints at some future directions:
- Meta might eventually release Llama 4 Behemoth fully and even consider an interactive fine-tuning platform where the community can help align it (similar to how some open-source projects crowdsource improvements).
- Work could be underway on even more modalities – perhaps integrating audio (speech) deeply into Llama 4, given Meta’s research in speech AI, making it a truly universal model.
- Personal AI assistants: With models as capable as Llama 4 being open, the path to personal local AI assistants is clearer. Imagine each person having an AI that runs on their own devices or private cloud, trained on their own data, fully under their control – Llama 4 is a big step in that direction.
Final thoughts: Llama 4 signals a future where AI is more accessible and customizable. It shows that the forefront of AI need not be behind closed doors. As Meta and the community work on Llama 4 and its successors, we move closer to AI that is not only powerful and multimodal but also widely available and shaped by collective effort. This could lead to more trustworthy AI (through transparency) and more innovation (through collaboration). In the grand scheme, Meta’s Llama 4 might be remembered as the point where the AI community gained an open model that truly rivals the best – a foundational block for the next era of AI advancements.
References
- Meta AI – Introducing Meta Llama 3
https://ai.meta.com/blog/meta-llama-3/ - Meta AI – Llama 2: The Next Generation of Open Foundation Models
https://ai.meta.com/llama/ - VentureBeat – Meta unveils Llama 3.2 with multimodal AI and 10M context tokens
https://venturebeat.com/ai/meta-unveils-llama-3-2-with-multimodal-ai-and-10m-context-tokens/ - Hugging Face – Llama 2 Model Hub
https://huggingface.co/meta-llama - OpenAI – GPT-4 Technical Report
https://openai.com/research/gpt-4 - Anthropic – Claude AI Overview
https://www.anthropic.com/index/introducing-claude - Google DeepMind – Gemini 1.5 Technical Report
https://deepmind.google/technologies/gemini/ - Mark Zuckerberg Instagram Post – Llama 4 Announcement
https://www.instagram.com/zuck/ - Semianalysis – Meta’s Open Source LLM Strategy: MoEs, Cost, and Competitive Positioning
https://www.semianalysis.com/p/meta-open-source-llm-strategy - Nvidia Developer Blog – Running LLMs Like Llama 4 on a Single GPU
https://developer.nvidia.com/blog/