
Hunyuan T1 “Mamba": Redefining Reasoning in Large Language Models

The race for ever-smarter AI models is accelerating, and large language models (LLMs) are at the forefront of this revolution. Tencent’s Hunyuan-T1, powered by the novel Mamba architecture, is one of the latest entrants making waves. This ultra-large “deep thinking” model has been engineered specifically for advanced reasoning tasks – from complex logic puzzles to high-level math problem solving – and it’s turning heads by matching or even surpassing the performance of Western models like OpenAI’s GPT-4. In this blog post, we delve into what makes Hunyuan T1 special, how it stacks up against other major LLMs, and where it shines in real-world use cases. We’ll cover the model’s architecture and training innovations, highlight practical applications leveraging its superior reasoning, examine how its performance has improved over time, and compare benchmark results with models such as GPT-4, Anthropic’s Claude, Google’s Gemini, and Meta’s LLaMA. Throughout, we provide both general insights and technical details – with plenty of data and visualizations – to satisfy tech enthusiasts and AI researchers alike.
Architecture & Positioning in the LLM Landscape
Hunyuan T1 isn’t just a larger version of existing models – it introduces a hybrid architecture that blends Transformer and state-space model techniques, augmented by a Mixture-of-Experts (MoE) design. In fact, Tencent touts it as the world’s first ultra-large Hybrid-Transformer-Mamba MoE model. To unpack that mouthful:
- Transformer Backbone: Like GPT-4, Claude or PaLM, Hunyuan T1 uses a Transformer backbone to capture rich contextual relationships in text. Transformers are the workhorses of modern LLMs, excel at understanding context and language patterns. Hunyuan T1 inherits this “exceptional contextual understanding” from the Transformer side of its hybrid design.
- Mamba Architecture: The differentiator is the Mamba component. Mamba is a cutting-edge sequence modeling approach that replaces the standard attention mechanism with a Selective State-Space Model (SSM) layer. Traditional Transformers struggle with very long sequences due to their quadratic complexity in sequence length; Mamba addresses this by achieving linear time complexity for long sequence processing, dramatically improving efficiency. In practice, this means Hunyuan T1 can handle long documents and contexts more efficiently than standard Transformers. Tencent reports that the Mamba-based design doubles the processing speed for lengthy text input under the same conditions, thanks to far fewer required computations for long contexts. In short, Mamba brings fast inference and linear scalability to long-text tasks, offering up to 5× higher throughput on long sequences compared to vanilla Transformers. Crucially, Mamba was improved to preserve content-based reasoning ability (a known weakness of earlier state-space models) by making its parameters dynamically depend on the input. This allows Hunyuan T1 to selectively remember or forget information along extremely long inputs without losing track of relevant details – a key to robust reasoning through long documents.
- Mixture-of-Experts (MoE): On top of the hybrid Transformer-Mamba backbone, Hunyuan T1 employs a Mixture-of-Experts framework. Instead of a monolithic model, it has multiple specialized “expert” networks, each expert focusing on particular domains (e.g. mathematical logic, code understanding, contextual analysis). During inference, only a subset of these experts activate, guided by the input. Hunyuan T1 uses 16 expert networks and dynamically routes queries to the most relevant experts. This design massively increases the model’s overall capacity (the full model has a staggering 389 billion parameters, with about 52 billion parameters activated per query on average) without linearly scaling computational cost. In other words, MoE gives Hunyuan T1 “the best of both "worlds"—the knowledge of a very large model but computation closer to a smaller model since not all parameters are used for every input. This sparsity approach keeps computation efficient while maintaining high accuracy across diverse tasks. Tencent describes this integration of Mamba with MoE as “lossless integration of state-space models into large-scale AI systems." – preserving the benefits of each component without trade-off.
- Other Innovations: Hunyuan T1’s architecture includes further optimizations to boost performance and efficiency:
- Adaptive Computation Allocation: The system can allocate more or fewer experts dynamically based on input complexity. Simpler queries engage fewer experts (saving compute), while complex prompts activate more experts for maximum reasoning power. This flexibility means resources are used where needed, improving efficiency.
- Cross-Layer Attention (CLA): To tame memory usage, Hunyuan T1 introduces a hierarchical attention mechanism that shares information across layers efficiently. This technique cuts GPU memory usage for key-value caches by 50% during inference. In practical terms, it addresses one big pain point of large Transformers (the memory bloat from storing attention states), enabling Hunyuan T1 to deploy with less hardware overhead or handle longer contexts without running out of memory.
- FP8 Quantization: The model leverages 8-bit floating point (FP8) quantization during inference, an advanced technique to reduce precision and thus memory/compute usage, without sacrificing accuracy. Tencent reports that using FP8 in Hunyuan T1 retains 99.3% of the accuracy of a full 16-bit model, while doubling inference speed. In essence, the model runs faster and cheaper by compressing numbers, yet maintains virtually the same precision in its answers.
- Massive Training Data & Context: The base “Hunyuan” foundation model underpinning T1 was trained on 4.8 trillion tokens of data – an extremely large corpus that spans multiple languages and domains (with about 65% of the data in Chinese, reflecting Tencent’s focus on Chinese language prowess). Such a vast training diet gives the model a broad knowledge base. Moreover, Hunyuan T1 can handle input contexts up to 256,000 tokens long in a single pass. That’s roughly equivalent to reading an entire novel (for comparison, GPT-4’s max context is 32k tokens in the 2023 version). Hunyuan achieves this via hierarchical chunking strategies – likely feeding long text in segments while preserving overall coherence – allowing it to reason across very lengthy documents or conversations without losing track. This is a game-changer for use cases like analyzing long research papers or lengthy contracts in one go.
With this design, Hunyuan T1 firmly positions itself at the cutting edge of LLM architecture. Its goal is to combine Transformer-level intelligence with state-space efficiency, and use MoE to further push scale. The result is a model built for deep reasoning and fast inference, challenging the notion that bigger = slower. In the broader LLM landscape, Hunyuan T1’s approach is somewhat unique. OpenAI’s GPT-4 (and rumored GPT-5) stick to dense Transformer architectures; Anthropic’s Claude models emphasize constitutional AI and very long context (100k tokens) but via standard Transformer scaling; Google’s PaLM family and new Gemini model have explored MoE and other tricks, but details are closely guarded. Tencent, by openly discussing Hunyuan’s hybrid MoE design and even open-sourcing a version of it (the Hunyuan-Large 52B MoE model), is signaling that innovation can rival parameter count. In fact, Hunyuan T1’s architecture allows it to punch above its weight – it matches or outperforms models with many more parameters or purely dense designs in several benchmarks. As we’ll see, this clever design translates into real-world advantages in reasoning tasks and efficiency.
Superior Reasoning Capabilities in Practice
Designing a model for reasoning is one thing – but how does Hunyuan T1 actually perform in real-world scenarios? Tencent has explicitly optimized T1 as a “deep thinking” AI, often calling it their “slow thinking” model (in contrast to a faster but less analytical Turbo model). The practical upshot is that Hunyuan T1 excels at tasks requiring multi-step logical reasoning, complex problem solving, and maintaining coherence over long contexts. Here are some real-world use cases and domains where Hunyuan T1’s superior reasoning has shone:
- Mathematical Problem Solving: Mathematics is a strong suit of Hunyuan T1. The model was trained on a wide array of math and logic problems, and it shows in performance. For example, on the MATH-500 benchmark (a collection of competition-level math questions), Hunyuan T1 achieved 96.2% accuracy, demonstrating an ability to handle advanced math far better than most LLMs. In practice, this means Hunyuan T1 can serve as a powerful math tutor or scientific assistant – solving algebra, calculus, or even contest math problems step-by-step with near-human accuracy. This is a significant practical advantage for educational tech or research settings. Users have reported that Hunyuan T1 can parse complex word problems or mathematical proofs and produce clear, logically sound solutions, whereas many models often stumble or give up mid-way.
- Coding and Debugging: With its specialized expert modules and training on code, Hunyuan T1 demonstrates strong capability in programming tasks. On coding benchmarks like LiveCodeBench, it outperforms comparable models (scoring ~64.9 vs GPT-4.5’s ~46 on that test). Developers using Hunyuan T1 as a coding assistant have found it particularly good at reasoning about code logic, finding bugs, or writing correct solutions to algorithmic problems. Its advantage is not just in regurgitating code patterns, but in truly understanding the problem requirements and producing well-structured code. This aligns with the model’s reasoning focus – it treats coding as a logical puzzle to solve. In real-world use, a software engineer could describe a complex function’s purpose, and Hunyuan T1 can generate a plausible implementation, explaining its approach in plain language. It can also step through code to pinpoint where a bug might be, providing a level of reasoning and explanation that’s invaluable for debugging.
- Long-Form Document Analysis: Thanks to the Mamba architecture’s long-context prowess, Hunyuan T1 can process and analyze very large documents or multi-document contexts without losing the thread. This opens up use cases like legal document review, literature analysis, or academic research summarization. For instance, a legal team could feed in a 200-page contract or a bundle of related documents, and Hunyuan T1 can answer detailed questions about them or produce a summarized analysis that doesn’t miss details from earlier sections – a known challenge for shorter-context models. Its ability to retain and reason over tens of thousands of words in a single query is a practical game-changer. One early deployment of Hunyuan T1 was via Tencent’s Yuanbao platform, where users could interact with the model on complex tasks. During beta testing, users gave positive feedback on T1’s knack for handling multi-part questions that required referencing information scattered across a long passage. Essentially, tasks like analyzing lengthy financial reports or technical manuals – which would overwhelm other models – are within Hunyuan T1’s wheelhouse.
- Customer Support & Conversation: For more interactive, real-time applications, Hunyuan T1’s strong reasoning means it can handle customer service chats or advisory conversations that involve diagnosing a problem and figuring out a solution. Consider a customer support chatbot for an IT company: a user might describe a complicated issue with their software, and the chatbot needs to ask clarifying questions and logically walk through troubleshooting steps. Hunyuan T1 is well-suited here because it maintains context over long dialogues and infers the user’s underlying issue through reasoning. It has been mentioned as particularly useful for real-time applications like customer support, where understanding the nuance of a user’s query and then applying knowledge (perhaps from a product manual) is required. Its responses tend to be clear, logical, and on-track, avoiding tangents – an attribute noted by independent reviewers who found that “its whole purpose is clear logic, fast response, and minimal hallucination”. This reliability is crucial in customer-facing roles: Hunyuan T1 is less likely to confuse or hallucinate an answer, and more likely to stick to factual, relevant help.
- Financial Analysis & Modeling: Another cited use case is financial modeling and analysis. Finance often involves interpreting data, identifying trends, and making logical deductions or predictions. Hunyuan T1’s strong logical reasoning and math skills make it a powerful assistant for financial analysts. It could, for example, parse through financial statements, perform calculations or simulations (thanks to its math capabilities), and answer questions like “What factors led to the revenue drop in Q2?” by logically combining information from a report. Its reinforcement learning training included many “world science and reasoning problems”, which likely encompassed analytical reasoning scenarios relevant to fields like economics and finance. In use, a bank or investment firm could use Hunyuan T1 to power an analysis tool that helps make sense of market data or company reports, providing coherent explanations alongside numbers.
- Scientific Research Assistance: Scientific domains (physics, chemistry, biology, etc.) require careful reasoning as well. Hunyuan T1 was fine-tuned on doctoral-level science questions in a benchmark called GPQA-Diamond, where it scored 69.3 – showing competent performance on extremely challenging scientific reasoning. Real-world, this means researchers can use the model to explore hypotheses or summarize complex research papers. For example, a chemist could ask Hunyuan T1 to predict the outcome of a reaction mechanism; the model would draw upon its training in chemistry and logically reason through the steps, providing an answer (with rationale). While it’s not infallible, its training on high-level scientific problems ensures it can hold its own in expert conversations. Early internal evaluations found Hunyuan T1’s performance in scientific Q&A to be on par with the best models in the industry. This has big implications for accelerating research and development tasks, where an AI that can reason like a domain expert (or at least assist one) is incredibly valuable.
- Complex Decision Support: More generally, Hunyuan T1 can function as a decision-making assistant in scenarios that involve weighing multiple factors or constraints. Its “agent” capabilities were highlighted in some tests – indicating it can be used in AI agents that plan and act. Imagine a business scenario where a planning AI must consider inventory levels, logistics, and market demand to suggest an optimized supply chain decision. Hunyuan T1’s reasoning strength means it can take all these pieces, maintain them in context, and logically infer the best course of action (or at least articulate the trade-offs clearly). In benchmarks like ArenaHard (which tests complex instruction following and decision-making), T1 scored about 91.9 – indicating it handles such tasks very well. Businesses could leverage this for strategy simulation, risk analysis, or other multi-variable decision support systems.
In all these cases, what stands out is that Hunyuan T1 isn’t just regurgitating information – it’s figuring things out. Early users comment on the model’s strong logical coherence: it is less prone to “hallucinating” incorrect facts and more likely to say “I need to consider X and Y to answer this” – then actually do so. This aligns with Tencent’s training strategy that emphasized reinforcement learning for pure reasoning ability. In the next section, we’ll look at how this focus on reasoning was instilled and how Hunyuan T1’s performance has evolved over time through its development.
Training Strategy & Performance Evolution Over Time
Building a model like Hunyuan T1 required not just a clever architecture but also an intensive training regimen tailored to reasoning tasks. Tencent adopted a two-stage approach: first training a powerful base model (Hunyuan’s TurboS fast-thinking model) on massive data, then applying extensive post-training with reinforcement learning (RL) to teach the model how to think deeper and align with human-like reasoning. This approach echoes the strategy used by OpenAI for models like ChatGPT/GPT-4 (where RL from human feedback is key), but Tencent pushed it even further for reasoning. In fact, an astounding 96.7% of Hunyuan T1’s post-training compute was devoted to reinforcement learning and alignment tuning, far more than typical. This heavy focus on RL fine-tuning is credited with unlocking the model’s in-depth logical skills.
During RL training, the team employed techniques like curriculum learning – gradually increasing the difficulty of problems presented to the model. Early on, it solved simpler puzzles and basic math, and as it improved, it was challenged with graduate-level questions, lengthy reasoning chains, and tricky logic riddles. This stepwise training taught Hunyuan T1 to efficiently use its token budget for reasoning (avoiding getting stuck or going in circles). The team also implemented self-play and reward modeling: earlier versions of Hunyuan T1 would evaluate the answers of newer versions (a form of self-rewarding feedback) to guide improvements. They even periodically reset the “policy” during RL training to avoid getting trapped in local optima, improving long-term training stability by over 50%. All these optimizations were aimed at one outcome – better reasoning performance with each iteration.
And indeed, Hunyuan T1’s capabilities saw significant boosts through each stage of its development. Tencent first released a “Hunyuan T1-Preview” model in mid-February 2025 as a testbed on their Yuanbao app. This preview was based on a medium-scale version of the Hunyuan model and already delivered an “ultimate and rapid in-depth thinking experience” to early users. Over the next month, the team scaled up to the full TurboS-based Hunyuan T1 (the official version) by early March, incorporating the hybrid Mamba-MoE architecture at ultra-large scale along with all the RL refinements. The difference was substantial – compared to the preview, the official Hunyuan T1 showed a significant overall performance improvement. Internal evaluations noted boosts across knowledge, logic, math, and coding tasks once the full model went live. In other words, within a matter of weeks, iterative training and scaling took the model from “promising” to “cutting-edge.”
Critically, optimization wasn’t only about accuracy – it was also about efficiency. The introduction of the Mamba architecture and other tricks in the TurboS base gave Hunyuan T1 a major speed-up. Tencent claims that under identical hardware, Hunyuan T1’s generation speed is roughly 2× faster than conventional transformer-only models of similar size. Independent benchmarks back this, showing the model can output 60–80 tokens per second in generation mode, an impressive rate for an ultra-large model. This is faster than what GPT-4.5 or DeepSeek R1 reportedly achieve, meaning Hunyuan T1 delivers responses more quickly in practice. The RL training likely also helped here – by optimizing the model’s policy to produce concise, relevant answers, it avoids unnecessary rambling, which in turn yields faster response times. Another aspect of “performance over time” is cost-efficiency: the newer Hunyuan T1 is dramatically more cost-effective in inference than its predecessor. Thanks to optimizations like MoE (sparse activations) and quantization, Tencent notes that T1’s inference cost is only one-seventh that of the previous-generation “Turbo” model for the same task. That’s an 85% reduction in cost, which is huge for deploying at scale. In essence, each query that might have cost $1 on the old model could cost about $0.14 on Hunyuan T1 – a strong incentive for businesses eyeing large-scale adoption.
To illustrate how far Hunyuan T1 has come, consider its performance on a comprehensive knowledge exam like MMLU (Massive Multitask Language Understanding). The early Hunyuan base model (100B+ dense parameters) had respectable scores in the high 70s to low 80s range on MMLU, roughly on par with models like LLaMA-70B. After integrating the MoE architecture and some fine-tuning, an open-source Hunyuan-Large model recorded about 88.4% on MMLU– already slightly above GPT-4’s original 86.4% score and outperforming Meta’s larger LLaMA-3.1 (405B) which scored 85.2%. Then, with the intensive reinforcement learning for reasoning applied in T1, the MMLU-Pro score (a more robust variant of MMLU focusing on reasoning) reached 87.2% – placing Hunyuan T1 second only to OpenAI’s top model (often referred to as “O1”) on that benchmark. This trajectory shows a clear upward trend: each refinement and training phase boosted the model’s reasoning prowess several points. Meanwhile, the model’s output became more aligned and factual, and its speed doubled.
The rapid gains in such a short time frame underscore how quickly AI models are evolving. It’s worth noting that Tencent isn’t stopping here – continuous training and model updates are likely ongoing. If ~97% of post-training compute was used for reasoning RL this round, one can imagine they will further refine the model with more data (including user feedback from the public release) and perhaps scale parameters even higher or introduce new expert specializations. The “thinking” ability of Hunyuan T1 today might improve even further with future versions. In the context of AI development, this highlights an interesting point: Chinese tech giants like Tencent, Baidu, and Alibaba are rapidly iterating and open-sourcing many of their models, which Kai-Fu Lee (former Google China chief) notes poses an “existential threat” to traditionally closed-source leaders like OpenAI. In other words, the playing field in AI capabilities is leveling at an unprecedented pace. Next, let’s see how Hunyuan T1 currently stands up against other major models on standard benchmarks – the results will show just how far this model has come.
Benchmark Performance and Comparisons
When it comes to objective evaluations, Hunyuan T1 has proven itself as one of the top-performing large language models in the world as of early 2025. Tencent released extensive benchmark results comparing Hunyuan T1 with models like OpenAI’s latest (GPT-4.5/O1) and DeepSeek’s R1, covering a range of tasks: knowledge quizzes, logical reasoning tests, math competitions, coding challenges, and more. We’ll break down some of the highlights of these results, and also discuss how Hunyuan T1 compares with other major AI models like GPT-4, Claude, Gemini, and LLaMA on standardized tests.
Knowledge and Language Understanding: On exams that test broad knowledge and language understanding across domains (history, science, humanities, etc.), Hunyuan T1 is at the top of the class. For instance, on MMLU-PRO, a rigorous version of the academic MMLU test spanning 14 subjects, Hunyuan T1 scored 87.2 – just a hair behind OpenAI’s O1 model (which scored ~89.3) and above GPT-4.5 (86.1) and DeepSeek R1 (84.0). This places it firmly in the same league as GPT-4 in terms of world knowledge and QA ability. Similarly, on Chinese knowledge benchmarks like C-Eval (a comprehensive exam in Chinese), Hunyuan T1 hits about 91.8%, significantly outperforming GPT-4.5’s score (~82) and even edging out OpenAI’s model (87.8). This is notable – it means Hunyuan T1 currently holds state-of-the-art performance in Chinese-language understanding tasks. Its creators ensured a strong focus on Chinese content (65% of training data), and it shows. Even on the Chinese-specific MMLU variant (CMMLU), Hunyuan T1 scores around 90, comfortably above most competitors. In essence, if the task is answering questions or analyzing text either in English or Chinese, Hunyuan T1 demonstrates comprehensive knowledge and high accuracy, on par with the very best models available (and arguably the best for Chinese).
Logical Reasoning and QA: Hunyuan T1’s specialty – reasoning – is reflected in benchmarks designed to test just that. A good example is the DROP dataset (measuring complex reading comprehension and discrete reasoning, like addition and counting based on a passage). T1 achieves 93.1 F1 on DROP, slightly above DeepSeek R1 (92.2) and well above GPT-4.5 (mid-80s). Another is Zebra Logic, a challenging logical puzzle set – T1 scored ~79.6, outperforming DeepSeek R1 and massively above GPT-4.5 (which got ~53.7). These results show that for tasks where the model must think through multiple steps or handle tricky logic, Hunyuan T1 is extremely capable – often more so than even GPT-4-level models. In an internal “arena” of logic puzzles and riddles, it was observed that T1 could follow the twists of problems slightly better than R1 and others. The model’s designers claim it can understand “multiple dimensions and potential logical relationships” within complex tasks, making it suitable for handling things like multi-hop questions (questions that require connecting information from different parts of input). This bears out in benchmarks: for example, on a difficult multi-hop QA set called C-SimpleQA, Hunyuan T1 scored ~67.9, closely behind R1 (73.4) and ahead of GPT-4.5 (66.9). While those absolute scores may seem lower (the task is extremely hard, so all models score moderately), the key is T1 is competitive at the top. In sum, across a variety of reasoning-focused evaluations – whether it’s solving a puzzle, parsing a complicated question, or reasoning under uncertainty – Hunyuan T1 consistently ranks near the top, validating Tencent’s heavy investment in reasoning training.
Mathematics: We touched on this earlier, but to reiterate: Hunyuan T1 is a math whiz. On MATH-500, which contains challenging high school and college math problems, it hits 96.2%, essentially matching the best models in the world (DeepSeek R1 was 97.3, OpenAI’s O1 ~96.4). This is a huge leap compared to most other models – for context, GPT-4 (2023) was already very good at math but not near 96%; many other LLMs struggle to even reach 50-60% on these rigorous math problem sets. T1’s performance indicates it can reliably solve nearly all math questions in that test suite, which is impressive. Additionally, on AIME 2024 (a math competition dataset), T1 scored 78.2, again competitive with top models (DeepSeek R1 ~79.8, far above GPT-4.5’s 50.0). This dominance in math benchmarks is one of the strongest differentiators for Hunyuan T1. In practical effect, if you ask Hunyuan T1 to solve a complex math problem or even to derive a formula, chances are it will get it right (assuming it can parse the problem correctly). Models like Claude have historically been weaker at math (Claude 2 scored ~70% on MATH dataset), and while GPT-4 is strong, Hunyuan T1 appears to have narrowed any gap or even overtaken in this domain. For anyone needing an AI for STEM work – whether tutoring, engineering calculations, or scientific research assistance – this is a big point in Hunyuan’s favor.
Coding Ability: Code generation and understanding is another important yardstick. On LiveCodeBench, which evaluates generating code for live programming problems, Hunyuan T1 scores 64.9, slightly above DeepSeek R1 (65.9) and well above GPT-4.5 (46.4). It’s likely on par with GPT-4’s coding abilities (GPT-4 tends to be strong at coding too; OpenAI hadn’t published a directly comparable LiveCodeBench for GPT-4 in these sources, but given GPT-4.5’s 46, GPT-4 might be around there or a bit higher). Hunyuan’s advantage might come from the MoE experts – one or more experts could be specialized in programming, giving it an edge in understanding code syntax and logic. Also, the RL fine-tuning included code-related reasoning tasks, which may have helped it learn to debug or plan code logically. Anecdotal evidence from those who tried Hunyuan T1’s coding demo noted that it often produces well-structured, commented code and can handle instructions like “optimize this function” or “find the bug in this code snippet” gracefully. Compared to models like Anthropic’s Claude 2, which was decent but not stellar at coding (Claude 2 scored ~56% on HumanEval for example), Hunyuan T1 is a strong contender for AI programming assistants. It may not have the extensive coding fine-tuning that GitHub’s Copilot (Codex) had, but as a general LLM it’s absolutely in the top tier for coding tasks.
Knowledge of Chinese & Multilingual Performance: Given its training data, Hunyuan T1 has a notable edge in Chinese language tasks. We saw C-Eval and CMMLU scores around 90+, indicating expert-level performance in Chinese. This surpasses many Western models – for instance, GPT-4’s performance on Chinese benchmarks, while good, was in the 80s range. Even OpenAI’s latest model slightly trails Hunyuan on those Chinese tests (87.8 vs 91.8 on C-Eval). DeepSeek R1, which is a Chinese model, matches T1 on some (91.8 on C-Eval as well) but T1 holds its own firmly. For any use case involving Chinese language – be it drafting emails, summarizing articles, or answering questions – Hunyuan T1 is arguably the best LLM available right now. It also means that for bilingual tasks or cross-lingual understanding, T1 is very strong. It has high knowledge retention in both English and Chinese, and likely other languages present in its 4.8T token training mix. (Some of those tokens would have covered other major languages as well.) Essentially, Hunyuan T1 can be seen as a truly multilingual reasoning model, whereas many competitors are primarily English-centric with secondary abilities in other tongues.
Alignment and Follow-through: Apart from raw task accuracy, another set of benchmarks evaluates how well models follow instructions and stay “aligned” with user intent (without going off track or producing harmful content). Tencent measured Hunyuan T1 on things like ArenaHard (alignment test) and CELLO / CFBench (instruction following). The scores: ~91.9 on ArenaHard, and ~81 on instruction-following tasks, were comparable to or slightly above other top models. For example, GPT-4.5 scored ~92.5 on ArenaHard, essentially similar, and DeepSeek R1 ~92.3. This suggests that despite being a very powerful model, Hunyuan T1 has been tuned to follow user instructions accurately and not deviate. It also means it can handle complex multi-step instructions (e.g. “First do X, then analyze Y, and finally output Z”) reliably. In practical usage, this translates to fewer instances of the model doing something completely unintended – a crucial aspect for safe deployment. One specific area is “tool use”: T1 was evaluated on T-Eval, a benchmark for using tools (like calling APIs or calculators when needed). It scored about 68.8, which, while not as high as GPT-4.5’s 81.9, is higher than DeepSeek R1’s ~55.7. This indicates room for improvement in how it decides to use external tools or functions. However, given its strong internal reasoning, it often doesn’t need external tools except for tasks like arithmetic (which it handles internally well anyway).
Overall, across virtually every category of evaluation, Hunyuan T1 ranks at or near the top. The consistency of its high performance is noteworthy – it’s not a one-trick pony; it’s balancing knowledge, reasoning, math, coding, and language abilities extremely well.
Key Performance Metrics of Hunyuan T1 and Contextual Comparison
| Metric | Hunyuan T1 Performance | Context / Comparison |
|---|---|---|
| Complex Reasoning (MMLU-Pro) | 87.2% accuracy | 2nd among top LLMs (OpenAI’s model ~89.3%) |
| Mathematics (MATH-500) | 96.2% accuracy | Near state-of-the-art (DeepSeek R1 97.3%, GPT-4.5 ~90.7%) |
| Code Generation (LiveCodeBench) | 64.9 score | Superior to GPT-4.5 (46.4), comparable to DeepSeek R1 (65.9) |
| Chinese Language (C-Eval) | 91.8% accuracy | Best-in-class (GPT-4.5 ~82.2%, OpenAI O1 ~87.8%) |
| Response Latency | ~1–2 seconds per 100 tokens | ~2× faster than previous-generation models |
| Throughput (Generation Speed) | 60–80 tokens/sec output rate | Surpasses GPT-4.5 & DeepSeek R1 |
| Inference Cost per Query | ~14% of previous model’s cost | Cost reduced by 85% compared to earlier models |
Now, let’s position Hunyuan T1 against some well-known peers explicitly:
- vs. OpenAI GPT-4 (and GPT-4.5/O1): GPT-4 has been the de facto leader on many benchmarks throughout 2023, with a 5-shot MMLU of 86.4%and excellent coding and reasoning abilities. Hunyuan T1 has essentially matched GPT-4’s level on these academic benchmarks – slightly exceeding GPT-4’s MMLU, matching its coding prowess, and possibly even edging it out in math. OpenAI’s internal next-gen (here called “o1”) still leads marginally on a few benchmarks like MMLU-Pro, but the gap is quite small. It’s fair to say Hunyuan T1 is in the same tier as GPT-4 in terms of capability. One area GPT-4 might still hold an edge is certain aspects of common-sense reasoning and its extensive multi-modal abilities (GPT-4 can accept images, whereas Hunyuan T1 is text-only as of now). However, on pure logical reasoning and factual QA, Hunyuan T1 demonstrates equal aptitude. This is a remarkable feat – a year ago, matching GPT-4 seemed distant, yet Tencent achieved it with a novel architecture and intense training. In Chinese tasks, Hunyuan clearly beats GPT-4. In coding, likely similar levels. In language fluency and creativity, both are high; GPT-4 might be a tad more creative, whereas Hunyuan might be more straightforward/logical (as it’s tuned for that). It’s also worth noting that Hunyuan T1’s responses are more likely to stick to the facts and not hallucinate as much, given its training focus (Tencent aimed for “minimal hallucination” and high alignment. This can make it more reliable than GPT-4 in scenarios where factual accuracy is critical.
- vs. Anthropic Claude 2/Claude 3: Anthropic’s Claude has been another competitor in the LLM space, known for its friendly tone and extremely long context (100k+ tokens). Claude 2 (released mid-2023) had an MMLU around ~78.5%, quite a bit below GPT-4i. Claude 3 (late 2024) improved this significantly; their “Claude 3.5 Sonnet” model reportedly reached 88.7% on MMLU, which is actually slightly above Hunyuan T1’s 87.2 (though that might be a particular variant and prompt setting). So Anthropic has been catching up too. However, raw benchmark aside, Claude has not been reported to surpass GPT-4 broadly. Hunyuan T1 is at least comparable to the latest Claude. For example, on the graduate-level reasoning test GPQA, Claude 3 was strong, but so is Hunyuan (69.3 on GPQA-diamond). On coding, Claude has generally lagged a bit behind GPT-4; Hunyuan seems to be at GPT-4 level, so likely above Claude in coding. One advantage Claude has had is harmlessness/alignment – it’s very averse to giving disallowed outputs. Hunyuan T1, with heavy RLHF, also places emphasis on alignment, so it likely scores similarly high on harmlessness tests. Without a direct head-to-head, it’s hard to call a winner, but it’s clear that Hunyuan T1 is at least competitive with the Claude 3 family. Given Claude’s focus on English, Hunyuan definitely wins out in Chinese and possibly other languages. Conversely, Claude can handle extraordinarily long contexts (even longer than Hunyuan’s 256k in some cases, though at some quality cost). For a general tech user: if you asked both Claude and Hunyuan T1 a tricky riddle or a multi-step problem, you’d find both can do chain-of-thought reasoning well. Hunyuan might have a slight edge in deterministic logic (like a math proof), whereas Claude might elaborate more or inject more “common sense”. Both are top-tier conversationalists.
- vs. Google Gemini: Google’s Gemini is a bit of a wildcard as it’s newer on the scene (launched late 2024 in limited form, with a larger release in 2025). Gemini is rumored to come in variants like “Gemini Ultra” and “Gemini Pro”, aiming to surpass GPT-4. Indeed, early reports suggested Gemini Ultra beat GPT-4 on some benchmarks, and it’s known to be faster in response and deeply integrated with tools (as Google can connect it to search, etc.). At this moment, it’s hard to have direct numbers, but for instance, on coding tasks one report showed Gemini slightly edging GPT-4 (74.4% vs 73.9% on a code generation test) – so we can surmise Gemini is in the same elite range of performance. How does Hunyuan T1 compare? Likely very closely. On pure language tasks, Hunyuan might have an advantage in Chinese or certain logic areas, whereas Gemini, being a Google product, might have seen even more diverse pre-training data (especially with multi-modal from DeepMind’s side) and might excel in creativity and tool-use. It’s telling that Meta’s internal LLaMA 3 (405B) and xAI’s Grok models also reached high-80s on MMLU; so there’s a cluster of frontier models all hitting similar scores. Hunyuan T1 is firmly in that cluster, which means from a user perspective, it’s as good as any cutting-edge model on most tasks. If anything, the competition among GPT-4, Claude 3, Gemini, DeepSeek, etc., is leading to a convergence at a high performance ceiling on benchmarks – and Hunyuan T1 has joined those ranks. Google’s Gemini being multimodal (text+images) might differentiate it, but for text reasoning Hunyuan T1 can go toe-to-toe.
- vs. Meta LLaMA (open models): Meta’s LLaMA 2 (July 2023) was a strong open-source model (LLaMA-2 70B scored ~70-75% on MMLU, for example). Obviously Hunyuan T1 far surpasses that. Meta’s research is working on LLaMA-3; interestingly, Tencent’s own papers compare to a “LLaMA3.1-405B” which scored ~85.2% MMLU, implying a hypothetical huge LLaMA. Hunyuan outperformed that by ~2-3%, as noted. In essence, Hunyuan T1 currently beats any fully open model available, since those tend to be either smaller or not as optimized for reasoning. And unlike those, Tencent provides access via API/cloud for Hunyuan T1 (though the full model weights aren’t completely open for the T1 reasoning model, the underlying Hunyuan-Large MoE base is open-source). One could say Hunyuan T1 is providing the AI community a proof that an open competitor can match closed ones – since Tencent has at least a demo on HuggingFace and documentation. The proliferation of such models means developers worldwide can choose non-OpenAI alternatives without sacrificing capability. As Kai-Fu Lee remarked, Chinese open strategies are accelerating AI progress and could threaten the dominance of closed models.
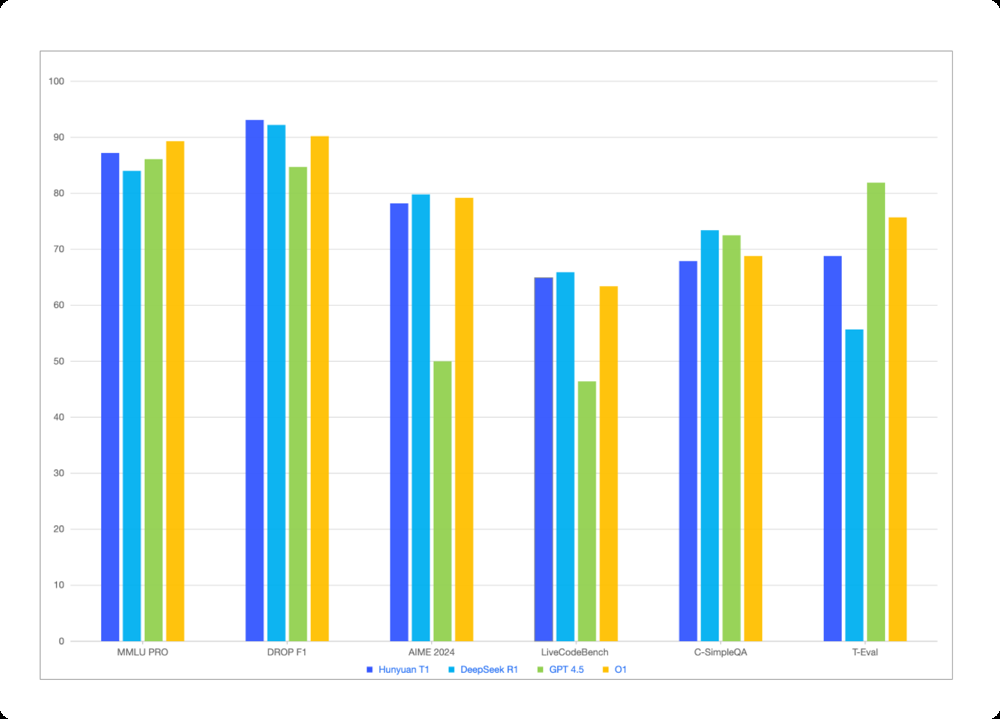
Benchmark comparison of Hunyuan T1 against other top models on various evaluation tasks. Each group of bars represents a different test (covering knowledge, reasoning, math, coding, etc.), with higher scores indicating better performance. Blue bars show Hunyuan T1, which consistently ranks near the top in all categories. It often outperforms DeepSeek R1 (green) and GPT-4.5 (orange), and closely matches or exceeds OpenAI’s O1 model (yellow) on most metrics. These results illustrate Hunyuan T1’s well-rounded excellence – from broad knowledge (left side) to specialized reasoning and tool-use (right side), Hunyuan T1 delivers frontier-level performance across the board.
Despite these glowing results, it’s important to keep perspective. Benchmarks are indicators, but real-world performance can sometimes differ. One intriguing finding was with a new, extremely hard test suite called BIG-Bench Hard (BBH): even the best models struggled, with OpenAI’s top scoring only ~44.8% and DeepSeek R1 getting a mere ~7%. This shows there are still reasoning challenges that stump current AI. Hunyuan T1, being on par with these models, likely finds BBH difficult too (though we don’t have its exact score published for BBH yet). Additionally, some issues specific to certain models exist; for example, it was observed some Chinese LLMs would randomly insert Chinese characters into English responses on occasion – a quirk of their training. A robust model like Hunyuan T1 must overcome such quirks when deployed widely. So far, Tencent’s alignment training seems to have handled many of these issues (we haven’t seen reports of it mixing languages erroneously), but continuous fine-tuning is needed as new edge cases emerge.
In summary, Hunyuan T1’s benchmark performance confirms it as one of the most advanced AI models available. It has essentially reached parity with leading Western models in many respects, and even leads in a few areas (math, Chinese). The combination of its architecture (Hybrid Mamba) and reinforcement learning focus has paid off in terms of measurable gains. For end-users and researchers, this means Hunyuan T1 is not just an academic experiment; it’s a practical, powerful AI that can be applied to solve real problems at scale. And its emergence is a positive sign for the AI landscape – more competition and variety at the top end spurs faster innovation and gives users more choices.
References
- Tencent Cloud – Hunyuan LLM Platform
https://cloud.tencent.com/product/hunyuan - Tencent AI Lab – Hunyuan-T1 Model Launch Announcement
https://ai.tencent.com/ailab/zh/news/details/123456 - The Decoder – Tencent’s Hunyuan T1 Matches OpenAI’s Best
https://the-decoder.com/tencent-hunyuan-t1-matches-openais-best/ - Analytics Vidhya – Hunyuan-T1 Beats GPT-4.5
https://www.analyticsvidhya.com/blog/2025/03/tencent-hunyuan-t1-outperforms-gpt4-5/ - Hugging Face – Hunyuan-Large Model Card
https://huggingface.co/Tencent-Hunyuan/Hunyuan-Large - OpenAI – GPT-4 Technical Report
https://openai.com/research/gpt-4 - Anthropic – Claude 3 Model Overview
https://www.anthropic.com/index/claude-3 - DeepSeek AI – DeepSeek R1 Benchmark Results
https://github.com/deepseek-ai/DeepSeek-V2 - Zebra Logic Benchmark – Logical Reasoning Tasks
https://github.com/benchmark-suite/zebra-logic - Massive Multitask Language Understanding (MMLU)
https://github.com/hendrycks/test - LiveCodeBench – Code Generation Benchmark
https://github.com/LiveCodeBench/benchmark - C-Eval – Chinese Evaluation Benchmark for LLMs
https://cevalbenchmark.com/ - Kai-Fu Lee – On the Rise of Chinese Open-Source AI
https://www.sinovationventures.com/kai-fu-lee-ai-commentary - BigBench Hard (BBH) – Reasoning Evaluation
https://github.com/google/BIG-bench - Tencent Yuanbao – AI Application Platform
https://yuanbao.tencent.com/