
How AI Is Transforming Large Codebase Management Across Enterprises

The exponential growth of software in modern enterprises has led to the proliferation of large, intricate codebases that serve as the backbone of critical digital infrastructure. From global banks managing millions of lines of transaction logic to tech giants maintaining the code behind cloud platforms, the scale and complexity of codebases have reached unprecedented levels. Managing such code is no longer merely a question of development efficiency—it has become a business-critical concern. Organizations must balance innovation with stability, ensure compliance, maintain performance, and reduce the mounting technical debt that accumulates over years of iterative software development.
Historically, software engineers have relied on a combination of manual reviews, static analysis tools, version control systems, and agile methodologies to manage codebases. While these approaches have evolved significantly over time, they often fall short in the face of today’s challenges. Traditional tools struggle to parse interdependent modules written across multiple programming languages, adapt to fast-changing architectures, or help engineers understand legacy systems built by long-departed developers. As organizations accelerate their digital transformations, these inefficiencies compound, leading to slower release cycles, increased bug incidence, and costly compliance failures.
The root of this problem lies in the disconnect between human cognition and code complexity. Developers must not only understand tens of thousands of lines of code but also grasp their interrelations, underlying business logic, and long-term maintenance implications. This task becomes increasingly daunting when navigating codebases that span microservices, APIs, databases, and user interfaces, often built over decades. Documentation is frequently outdated or missing altogether, and tribal knowledge within teams fades with employee turnover.
Against this backdrop, artificial intelligence (AI) has emerged as a disruptive force capable of transforming how we manage large codebases. No longer limited to rudimentary code autocompletion or keyword-based search, modern AI tools now possess the ability to semantically analyze code, predict developer intent, and even generate entire modules autonomously. These capabilities are driven by large language models (LLMs), deep learning architectures, and embedding-based search engines that have been trained on billions of lines of open-source and enterprise code.
The appeal of AI-powered code management tools lies in their ability to augment the developer experience across a broad range of tasks. From identifying bugs and suggesting patches to generating documentation and optimizing code performance, these systems introduce a new paradigm of intelligent automation. For example, GitHub Copilot can suggest function implementations in real time based on natural language prompts. Tools like Amazon CodeWhisperer and OpenAI Codex extend this further by offering multilingual support and deep contextual awareness. Meanwhile, static analysis platforms now integrate AI models to detect security vulnerabilities that human reviewers might miss.
These innovations are not confined to individual developer tools. At the enterprise level, organizations are deploying AI to manage entire software pipelines. AI-driven dependency mapping, regression analysis, and predictive modeling are enabling teams to anticipate the impact of changes before they are deployed. DevOps processes benefit from intelligent CI/CD pipelines that dynamically adapt test suites and resource allocations. Even in compliance-heavy sectors such as healthcare and finance, AI models are being leveraged to enforce coding standards, detect license violations, and generate audit-ready logs.
Yet, the integration of AI into codebase management is not without challenges. Concerns around trust, explainability, hallucination, and regulatory compliance persist. Moreover, the effectiveness of AI tools varies depending on the nature of the codebase, the programming languages used, and the quality of historical data. As such, these tools are best seen not as replacements for developers but as intelligent assistants—augmenting human judgment with computational power.
This blog will explore how AI tools are revolutionizing large codebase management in five core areas. First, we will examine the foundational AI capabilities driving these advancements, such as natural language understanding, semantic search, and reinforcement learning. Second, we will explore real-world industry applications and case studies that demonstrate tangible benefits in productivity and code quality. Third, we will delve into the risks, limitations, and ethical considerations that must be addressed to ensure responsible AI adoption. Finally, we will present a forward-looking analysis of how these technologies might evolve, with a particular focus on fully autonomous code maintenance and cross-system integration.
To frame the discussion, the chart below visualizes the dramatic increase in both codebase size and structural complexity over the past decade. This trend underscores the urgency for AI-enhanced tools in navigating today’s software development landscape.

Through this analysis, we aim to provide a comprehensive view of how AI is not merely assisting software engineers, but redefining the very foundations of large-scale software development and maintenance.
Core AI Capabilities Driving Codebase Management
As enterprises grapple with growing code complexity and increasing demands for development agility, artificial intelligence has emerged as a critical enabler of scalable, intelligent software management. At the heart of this transformation are advanced AI capabilities that go far beyond simple code autocompletion or pattern matching. These capabilities harness cutting-edge machine learning models, particularly large language models (LLMs), to facilitate deeper code understanding, intelligent automation, and proactive optimization of massive codebases. This section dissects the primary AI technologies underpinning modern codebase management tools and outlines how they are reshaping software development across industries.
Natural Language Processing for Code Understanding
One of the most significant breakthroughs in AI-driven development has been the application of Natural Language Processing (NLP) to source code. Unlike traditional tools that treat code as syntax trees or byte streams, NLP-based systems treat code as a language with structure, semantics, and intent. Leveraging pre-trained LLMs such as OpenAI Codex, Meta’s Code Llama, or Google's AlphaCode, developers can now interact with codebases using natural language prompts. These models can interpret queries such as “find where the payment gateway timeout is set” or “rewrite this function to use asynchronous calls,” significantly reducing the time required for code navigation and comprehension.
By training on millions of public code repositories and documentation corpora, these models have developed an ability to infer intent and context, enabling applications in code summarization, automated documentation, and cross-language translation. The result is a more intuitive development experience, particularly for junior developers or teams unfamiliar with legacy systems.
Semantic Code Search and Embedding Models
Traditional code search tools rely on keyword matching, which is limited when developers are unsure of the exact terms used in the codebase. Semantic search, powered by embedding models, addresses this shortcoming by representing code snippets, functions, and documentation in a high-dimensional vector space. Tools such as Sourcegraph Cody and GitHub Copilot Enterprise use vector embeddings to match developer queries with semantically relevant results, even if there are no keyword overlaps.
These models are trained using contrastive learning and transformer-based architectures, allowing them to capture syntactic and functional similarities between different parts of a codebase. For example, a query about “user authentication logic” may surface code snippets implementing JWT, OAuth, or session-based auth, regardless of terminology used. In large enterprise systems, this capability is invaluable for understanding how similar functionalities are implemented across different services or modules.
AI-Powered Static Analysis and Vulnerability Detection
Static code analysis has long been a cornerstone of software quality assurance. However, conventional static analyzers are often rule-based and produce a high number of false positives. AI-powered static analysis tools now apply pattern recognition, probabilistic reasoning, and learned heuristics to identify security vulnerabilities, performance bottlenecks, and logic flaws more accurately.
Startups such as DeepCode (acquired by Snyk), Codiga, and ShiftLeft have integrated AI into their static analysis pipelines. These tools continuously learn from historical bugs, community best practices, and evolving coding patterns to refine their detection algorithms. For enterprises managing sprawling codebases across multiple teams and regions, this ensures consistent enforcement of security and compliance standards, reducing the risk of critical production incidents or regulatory breaches.
Automated Refactoring and Optimization
Refactoring is essential to maintain code health over time, but it can be labor-intensive and error-prone, especially in large systems with complex interdependencies. AI tools such as Facebook Aroma, JetBrains' AI Assistant, and Amazon CodeGuru employ deep learning to recommend and apply code transformations that improve maintainability, reduce redundancy, or enhance runtime performance.
These systems leverage program analysis techniques alongside machine learning models to detect "code smells," antipatterns, or inefficient constructs. By automating parts of the refactoring process—such as renaming variables, consolidating duplicate logic, or reordering execution flows—AI tools enable developers to focus on higher-level architectural concerns. Some advanced systems can also simulate the impact of proposed changes, providing confidence in automated edits before they are committed.
Reinforcement Learning in Testing and Build Optimization
Reinforcement learning (RL), a technique traditionally used in robotics and gaming AI, is now being applied to codebase optimization challenges. In large CI/CD pipelines, RL agents can be trained to prioritize test cases, manage build resources, or allocate compute based on past outcomes. For example, Facebook’s Sapienz system uses RL to dynamically select and sequence tests to uncover the maximum number of bugs with minimal resource usage.
Similarly, AI models can learn to optimize build times by analyzing historical data on dependency changes and build outcomes. This is particularly beneficial for monorepos or microservice architectures where full builds are costly. By selectively rebuilding only the affected modules, organizations can accelerate delivery timelines and reduce infrastructure costs.
Code Summarization and Documentation Generation
Documentation is often considered a necessary but neglected aspect of software development. Many large codebases suffer from outdated, inconsistent, or missing documentation. AI models trained for code summarization—such as CodeBERT and InCoder—address this gap by generating natural language explanations of functions, classes, and APIs. These tools can also update README files, generate changelogs, or create onboarding guides for new developers.
By automating documentation, AI ensures that knowledge is retained and accessible, mitigating the effects of employee turnover or institutional knowledge loss. In regulated industries, this can also support audit trails and compliance reporting.
Multilingual and Cross-Platform Support
Another key capability of modern AI tools is their ability to operate across multiple programming languages and platforms. Most enterprise codebases are polyglot, consisting of backend services in Java, Python, or Go; frontend interfaces in JavaScript or TypeScript; and infrastructure as code in YAML or Terraform. AI systems trained on multilingual corpora can understand, translate, and generate code across these languages, enabling holistic analysis and transformation of the entire software stack.
For example, OpenAI Codex can interpret and generate code in more than a dozen languages, making it suitable for full-stack development tasks. Multilingual models are also crucial for migrating legacy systems from outdated languages (e.g., COBOL or Perl) to modern frameworks, facilitating digital modernization efforts.
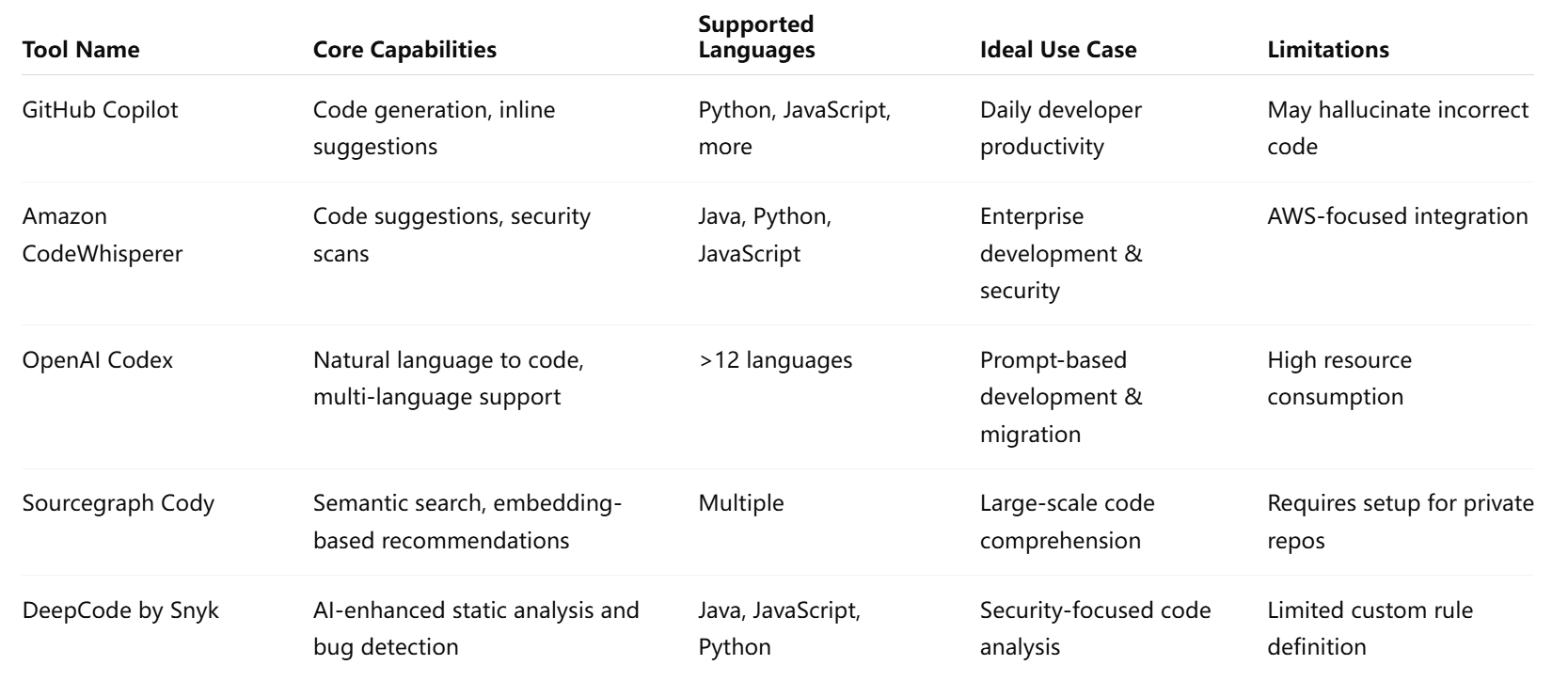
As illustrated above, each AI tool brings distinct strengths to the table. Enterprises must evaluate these offerings based on codebase characteristics, team workflows, and security requirements. In the next section, we will explore how these capabilities translate into real-world benefits through case studies and deployment scenarios across various industries.
Use Cases and Industry Applications
The transformative potential of artificial intelligence in large codebase management extends far beyond theoretical capabilities. In practice, AI-powered tools are actively reshaping the way organizations across sectors develop, maintain, and modernize software at scale. From legacy code refactoring in financial institutions to streamlining DevOps operations in tech enterprises, AI is becoming an indispensable ally. This section explores key industry-specific applications and use cases where AI tools deliver measurable efficiency, quality, and innovation gains.
Modernizing Legacy Systems in Regulated Industries
Industries such as banking, insurance, and healthcare rely heavily on legacy systems written in decades-old programming languages such as COBOL, PL/I, or Fortran. These systems, though mission-critical, pose significant risks due to outdated documentation, limited developer availability, and brittle architecture. AI tools are now central to legacy modernization strategies.
For example, companies are using natural language-to-code translation models, such as OpenAI Codex or IBM’s Project CodeNet, to automatically convert legacy functions into modern languages like Java or Python. Embedding models further assist by mapping similar function signatures across large, fragmented codebases, identifying duplication, and recommending consolidation.
In one instance, a large North American insurer used AI-driven code understanding to reduce the cost of COBOL-to-Java migration by over 40%, while also accelerating time-to-completion by 18 months. The AI tools enabled the team to semantically match legacy modules with newer system components, preserving business logic without manual intervention.
Enhancing Developer Productivity in Enterprise Software
Tech companies managing vast software ecosystems often struggle with onboarding new developers, maintaining consistent code quality, and reducing context-switching overhead. AI coding assistants—such as GitHub Copilot, Amazon CodeWhisperer, and Tabnine—are streamlining these workflows by embedding intelligence directly into integrated development environments (IDEs).
For instance, a global SaaS provider deployed Copilot across its engineering teams to support Python and TypeScript development. Initial findings showed that developers completed tasks 30% faster on average, particularly when writing boilerplate code or navigating complex APIs. AI assistants reduced cognitive load by generating inline suggestions based on natural-language comments and contextual code understanding.
Moreover, enterprise-grade semantic code search engines such as Sourcegraph Cody have enabled large teams to query codebases using plain English—e.g., “Where do we initialize the Stripe API?”—instead of relying on tribal knowledge or digging through documentation. This capability has shortened code exploration cycles and improved knowledge sharing across teams and regions.
Managing Open-Source Projects and Distributed Contributions
Open-source maintainers face unique challenges due to the collaborative and decentralized nature of their projects. Codebases often involve hundreds of contributors, many of whom are unfamiliar with internal design decisions or standards. AI tools assist maintainers in triaging issues, reviewing pull requests, and enforcing contribution guidelines.
Projects such as PyTorch, TensorFlow, and Kubernetes have integrated AI-based linters, automatic documentation generators, and security scanners to improve submission quality and speed up review cycles. GitHub’s AI features allow maintainers to summarize large pull requests or detect inconsistent function usage across files.
For maintainers of projects with high visibility and security sensitivity, AI-powered static analysis is especially valuable. Snyk’s DeepCode, for instance, scans for known vulnerabilities and misconfigurations in real time, ensuring continuous compliance with secure coding practices.
Optimizing DevOps and CI/CD Pipelines
In DevOps environments, managing large codebases is not only about development—it’s also about build, test, integration, and deployment. AI-driven automation is making continuous integration and continuous deployment (CI/CD) pipelines more intelligent, adaptive, and cost-efficient.
Machine learning models now analyze historical build and test data to dynamically prioritize test cases, avoiding unnecessary full-suite executions. For example, Facebook’s Sapienz uses reinforcement learning to optimize test case selection based on bug-finding effectiveness, thereby accelerating feedback cycles and reducing resource waste.
Similarly, AI models can optimize build times by predicting which modules require recompilation. Tools like Google’s Bazel integrate predictive analytics to minimize build redundancies, especially in monolithic or multi-repo configurations.
In addition, anomaly detection algorithms can identify patterns in build failures or performance regressions, offering proactive alerts before incidents escalate into production outages. These capabilities are crucial for organizations deploying multiple times per day and operating on global infrastructure.
Accelerating Onboarding and Knowledge Transfer
Large codebases pose a steep learning curve for new developers, especially in domains with minimal documentation or complex logic chains. AI-powered onboarding assistants mitigate this challenge by summarizing relevant functions, generating walkthroughs, and providing contextual explanations.
Enterprise deployments of tools like Codeium and JetBrains AI Assistant have enabled developers to quickly grasp code intent through inline comments generated automatically. This not only speeds up onboarding but also promotes a culture of knowledge sharing without relying heavily on senior engineers.
Furthermore, some AI tools are integrated with corporate wikis, issue trackers, and internal documentation systems. This holistic integration provides a 360-degree view of how a specific function, module, or library fits into the broader ecosystem—bridging the gap between code and organizational context.
Improving Compliance, Auditing, and Governance
Regulated sectors face significant compliance obligations related to data privacy, software safety, and license management. AI models can be trained to detect non-compliant code patterns, such as the improper handling of personally identifiable information (PII), the inclusion of unlicensed libraries, or the lack of logging for critical operations.
For example, an e-commerce platform operating in the EU leveraged an AI-enhanced static analyzer to identify violations of GDPR rules embedded deep within its codebase. The model flagged instances of user data logging that had escaped manual review and provided suggested remediations.
Similarly, AI tools help automate the generation of audit logs by documenting changes, tracing function calls, and mapping data flow. These features are particularly important for sectors such as defense, aviation, and healthcare, where auditability and traceability are legally mandated.
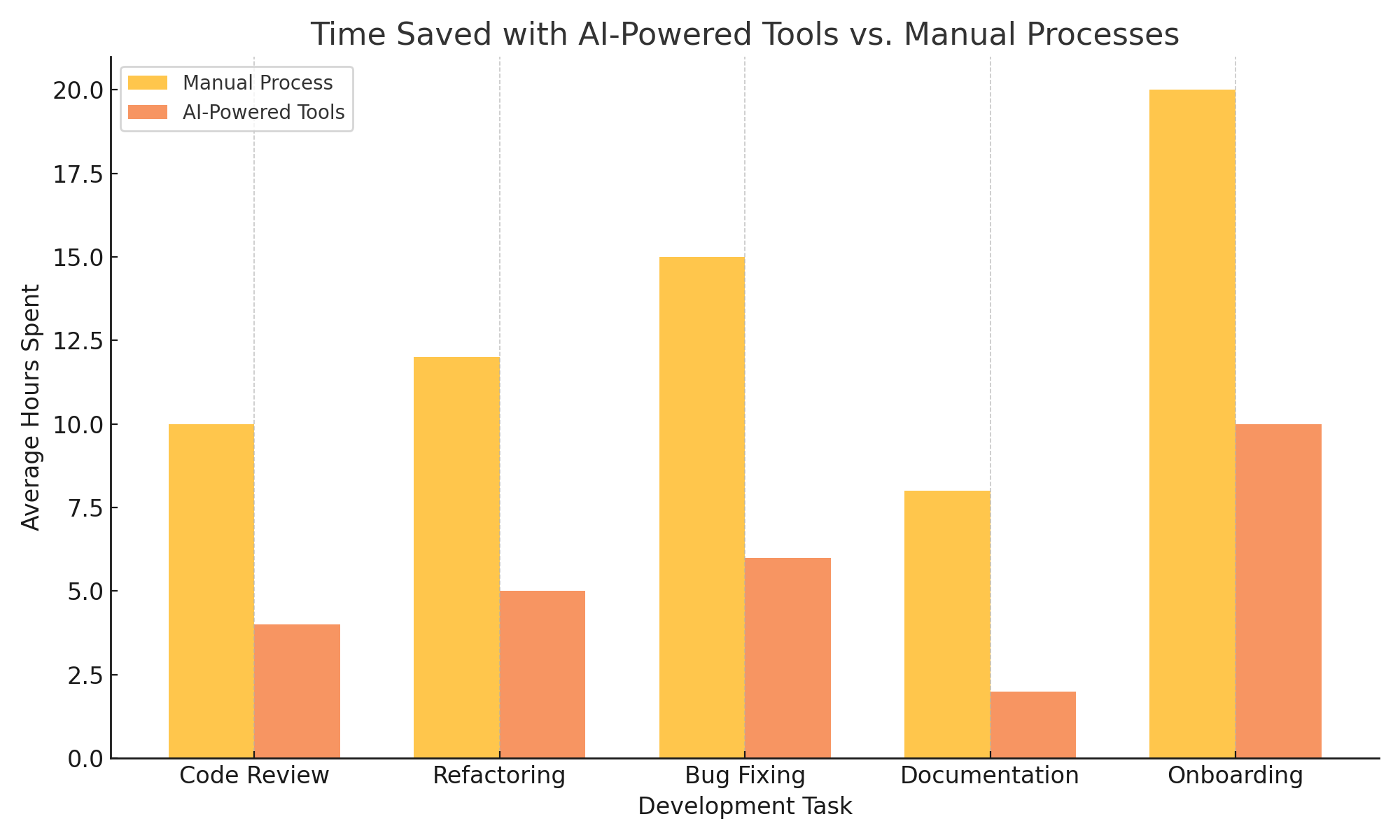
Through these use cases, it is evident that AI is not just augmenting specific development tasks but transforming the entire software engineering lifecycle. The benefits span efficiency, scalability, maintainability, and compliance—making AI tools a critical investment for forward-looking organizations. In the next section, we will examine the challenges, risks, and ethical considerations involved in deploying these tools across large code environments.
Challenges, Limitations, and Ethical Considerations
Despite their transformative promise, AI tools for large codebase management are not without significant challenges. As enterprises accelerate the adoption of these intelligent systems, it is critical to assess their limitations, potential risks, and ethical ramifications. A nuanced understanding of these concerns is necessary not only for effective implementation but also for ensuring responsible and sustainable integration into the software development lifecycle.
Model Hallucinations and Code Reliability
One of the most prominent limitations of large language models (LLMs) used in AI coding assistants is their tendency to hallucinate—generating code that is syntactically correct but functionally incorrect or misleading. These hallucinations stem from the probabilistic nature of generative AI, which predicts code based on statistical patterns rather than deterministic logic.
In high-stakes environments, such as healthcare, finance, or autonomous systems, hallucinated code can lead to catastrophic failures. For example, an AI tool might suggest a method that appears to interact securely with a database, yet inadvertently introduces a SQL injection vulnerability due to subtle misimplementation. Even in less critical scenarios, such inaccuracies can create downstream bugs, regressions, or performance issues.
To mitigate this, best practices advocate for keeping a human-in-the-loop (HITL) review process, wherein AI-generated code is thoroughly vetted by experienced developers. Organizations must also adopt automated testing pipelines to validate code behavior before deployment. Nevertheless, the unpredictable nature of AI output remains a core concern, especially in large, dynamic codebases where even minor changes can have cascading effects.
Data Privacy and Proprietary Code Exposure
Another concern is the potential leakage of sensitive or proprietary code through the use of cloud-based AI services. Many AI coding tools operate as hosted services, which may transmit snippets of enterprise code to external servers for inference. Even with encryption and secure APIs, this creates a risk vector for intellectual property (IP) theft, compliance violations, or inadvertent data disclosure.
For example, when a developer uses an AI tool to generate a function, the model may inadvertently reproduce code patterns it has seen during training—even if those patterns originate from public repositories with restrictive licenses. This raises the possibility of license contamination and IP ambiguity, which can expose organizations to legal liabilities.
To address this, some vendors now offer on-premise or self-hosted AI models, allowing enterprises to retain control over data flow and training inputs. Regulatory frameworks such as GDPR, HIPAA, and the Digital Markets Act also necessitate transparent data practices, auditability, and model explainability—features not always available in commercial AI solutions.
Trust, Explainability, and Developer Skepticism
While AI tools offer increased productivity, they also introduce a cognitive barrier: trust. Developers may be hesitant to adopt tools whose inner workings are opaque or whose suggestions are not easily explainable. This lack of transparency undermines confidence, particularly in safety-critical or regulated domains.
Explainability in AI-generated code is still an emerging field. Although some tools attempt to annotate or justify their suggestions, most operate as black boxes. This is in stark contrast to traditional rule-based linters or static analyzers, which provide deterministic and traceable reasoning. Developers are thus left with a dilemma—accept potentially helpful suggestions without full understanding, or revert to manual processes.
Bridging this trust gap requires transparency mechanisms such as confidence scores, counterfactual examples, or model rationales. Education and upskilling are equally vital; organizations must train teams not just in AI usage but in AI literacy—empowering them to evaluate, debug, and contextualize machine-generated code.
Model Bias and Fairness in Code Recommendations
AI models are only as good as the data on which they are trained. Unfortunately, training datasets often reflect systemic biases—such as underrepresentation of certain programming languages, overuse of inefficient idioms, or propagation of insecure design patterns. These biases can lead to skewed recommendations, perpetuating poor coding practices or ignoring edge cases.
For instance, if a model is predominantly trained on JavaScript web applications, it may perform poorly when applied to embedded C++ systems. Worse, biased training data can lead to insecure defaults or platform-specific assumptions that fail silently in production environments.
To counteract this, developers and vendors must enforce data diversity, include underrepresented use cases, and curate training corpora with robust code quality filters. Audits and bias evaluation tools are beginning to emerge, but standardization in this area remains immature. Transparent model documentation—detailing training data scope, known limitations, and intended use cases—is crucial for responsible deployment.
Scalability and Infrastructure Demands
Running AI models at enterprise scale is not trivial. Transformer-based models, especially those with billions of parameters, require substantial computational resources. Serving these models in real-time to hundreds of developers necessitates high-performance GPUs, memory-efficient inference pipelines, and reliable caching mechanisms.
Moreover, codebases are inherently contextual—spanning multiple repositories, build systems, dependencies, and programming languages. AI systems must operate within this fragmented landscape, integrating with version control systems, CI/CD pipelines, and security tooling. Achieving this level of interoperability is challenging and may require custom engineering.
To address scalability, some organizations are adopting hybrid approaches—using smaller models for common tasks (e.g., autocompletion) and invoking larger models only for complex refactoring or semantic search. Model distillation and quantization techniques also help reduce latency and hardware costs, though at the expense of accuracy.
Legal and Regulatory Implications
As AI becomes an integral part of the software supply chain, its legal and regulatory footprint expands. Governments and industry bodies are increasingly scrutinizing how AI-generated code is used, especially when it intersects with cybersecurity, algorithmic accountability, and user rights.
For example, AI tools that automate compliance-related logic must adhere to evolving standards such as SOC 2, ISO/IEC 27001, or NIST 800-53. Any failure to comply—whether through incorrect logic or outdated mappings—can result in severe penalties. Furthermore, the European Union’s AI Act and similar legislation globally are introducing provisions for model classification, risk assessment, and usage disclosures.
Legal clarity is also needed around liability: If AI-generated code introduces a critical bug, who is responsible—the developer, the organization, or the AI vendor? Currently, there is no standardized legal framework to address such questions, placing enterprises in a grey area of risk and responsibility.
As organizations integrate AI into their development workflows, these challenges and considerations must be treated as first-order design constraints. Ignoring them risks not only operational inefficiencies but also reputational, legal, and security repercussions. In the concluding section, we will explore how these issues may be addressed in the future, and how AI's role in software engineering is expected to evolve in the coming decade.
Towards Autonomous Code Maintenance and Beyond
The current trajectory of artificial intelligence in software engineering suggests that we are only at the beginning of a transformative era. While today's AI tools assist developers with code suggestions, documentation, and analysis, the next generation of intelligent systems aims to fully automate large portions of the software lifecycle—potentially leading to an era of autonomous code maintenance. This final section explores the emerging trends, future capabilities, and strategic implications that will define the evolution of AI-driven codebase management.
From Augmentation to Autonomy
To date, AI tools have functioned primarily as augmentative companions—offering assistance without replacing the human developer’s core responsibilities. However, with advances in foundation models and agent-based architectures, the possibility of autonomous code agents is becoming increasingly plausible. These agents will not only suggest code but also monitor systems, detect anomalies, refactor modules, and even deploy updates without explicit developer intervention.
Initiatives such as AutoGPT, AgentCoder, and SWE-agent are early demonstrations of multi-step reasoning in AI agents capable of understanding objectives, performing complex coding tasks, and adapting based on feedback loops. In the context of large codebases, this could translate to agents that handle routine maintenance, respond to bug reports, or align implementations with evolving architectural guidelines.
Over the next five years, we can expect the emergence of hybrid workflows where human developers collaborate with autonomous agents that proactively manage technical debt, enforce coding standards, and optimize performance without being explicitly prompted.
Integration with AI-Native Development Platforms
Another major evolution will be the rise of AI-native development environments—platforms built from the ground up to support continuous collaboration between human engineers and AI agents. Unlike traditional IDEs, these platforms will combine real-time semantic analysis, intelligent versioning, auto-testing, and code comprehension layers under a unified interface.
These environments will act as intelligent co-pilots, maintaining a continuous awareness of business logic, system dependencies, and runtime behavior. For example, if a developer implements a new feature, the platform could automatically assess its impact on other modules, recommend architectural changes, update documentation, and validate compliance with organizational policies.
Companies such as Replit, JetBrains, and GitHub are already moving in this direction with AI-augmented IDEs. However, the true potential lies in building platforms that treat the entire codebase—and its historical evolution—as a living artifact, subject to continuous improvement and adaptation through AI orchestration.
Expanding the Scope of Foundation Models
Current code-focused language models like Codex, Code Llama, and DeepSeek-Coder are being rapidly enhanced with greater context windows, multimodal capabilities, and reasoning skills. The next wave of foundation models will likely integrate code, documentation, test cases, logs, and even user feedback into a single understanding framework.
This evolution will allow models to perform cross-system optimization—identifying bottlenecks between backend APIs and frontend rendering, aligning cloud configurations with performance goals, or correlating crash reports with source code changes. Large context models such as Claude and Gemini are already capable of ingesting hundreds of thousands of tokens, enabling them to reason across entire repositories in a single inference cycle.
In enterprise environments, these capabilities could support portfolio-wide optimizations, such as harmonizing authentication logic across microservices, upgrading dependency trees, or aligning code structures with organizational KPIs.
Federated Learning and Secure Collaboration
The future will also see a growing emphasis on federated learning and privacy-preserving collaboration across organizations. As companies become more protective of their code and intellectual property, they may be reluctant to train AI models on centralized datasets. Federated learning enables collaborative model training across decentralized systems—ensuring that sensitive code never leaves the local environment.
This approach will be particularly valuable in sectors such as defense, aerospace, and finance, where strict regulatory controls prohibit data sharing. Through secure multiparty computation and differential privacy techniques, federated AI tools will support intelligent code management without compromising confidentiality or compliance.
Moreover, shared model checkpoints and fine-tuned agents may become part of enterprise-to-enterprise collaborations, allowing different organizations to benefit from AI advancements while retaining control over proprietary data.
Human-AI Governance and Development Ethics
As the sophistication of AI in code management increases, so too will the importance of governance frameworks. Organizations must define clear roles, accountability structures, and ethical boundaries for how AI tools are used in software engineering. Questions around authorship, code ownership, liability, and decision-making authority will become central.
For instance, if an autonomous agent introduces a security flaw or changes business-critical logic, who is accountable—the AI vendor, the developer team, or the platform provider? Additionally, how should organizations audit AI-generated changes to ensure alignment with long-term strategic goals and ethical standards?
Industry leaders and regulators will need to co-develop AI auditing protocols, certification systems, and operational safeguards to ensure that intelligent systems enhance, rather than compromise, software quality and public trust.
AI as a Force Multiplier for Innovation
Despite these challenges, the long-term outlook for AI in codebase management remains overwhelmingly positive. By automating routine and repetitive tasks, AI enables developers to focus on strategic design, creative problem-solving, and product innovation. For startups, AI tools offer leverage to build scalable systems with small teams. For large enterprises, they provide a mechanism to sustain digital agility while managing legacy complexity.
Moreover, AI will facilitate the emergence of new engineering roles—such as prompt engineers, AI interaction designers, and model validators—who will bridge the gap between algorithmic intelligence and software craftsmanship.
In conclusion, AI tools for large codebase management are no longer speculative—they are real, rapidly evolving, and fundamentally reshaping the practice of software development. As we look ahead, the focus must shift from adoption to orchestration: how to responsibly harness these tools, integrate them across ecosystems, and align them with organizational goals. Those who succeed in navigating this evolution will not only manage complexity more effectively but will also set the pace for the next era of intelligent software engineering.
References
- GitHub Copilot – https://github.com/features/copilot
- Amazon CodeWhisperer – https://aws.amazon.com/codewhisperer/
- OpenAI Codex – https://openai.com/blog/openai-codex
- Sourcegraph Cody – https://sourcegraph.com/cody
- DeepCode by Snyk – https://snyk.io/product/developer-security/static-application-security-testing/
- JetBrains AI Assistant – https://www.jetbrains.com/ai/
- IBM Project CodeNet – https://developer.ibm.com/projects/codenet/
- Facebook Sapienz – https://engineering.fb.com/2020/07/20/developer-tools/sapienz/
- AutoGPT – https://github.com/Torantulino/Auto-GPT
- Code Llama by Meta – https://ai.meta.com/blog/code-llama-large-language-models-coding/