
FramePack Revolutionizes AI Video Generation on Budget GPUs with Just 6GB VRAM

In recent years, artificial intelligence has revolutionized the landscape of digital media, particularly in the realm of content generation. While text-to-image models like DALL·E, Midjourney, and Stable Diffusion have become household names among digital creators, the next frontier—AI-generated video—has proven far more complex. Generative video models demand substantially more computational power, with many relying on high-end GPUs equipped with upwards of 24GB or even 48GB of VRAM to function efficiently. This hardware barrier has significantly limited the accessibility and scalability of video AI for the broader developer and creative communities.
AI-generated video is a multifaceted technological challenge. Unlike static image generation, video synthesis must handle both temporal and spatial coherence. This means maintaining consistency across multiple frames while preserving the visual quality and structure within each individual frame. As a result, the memory footprint for even a short AI-generated clip can quickly balloon into gigabytes of VRAM usage. This requirement renders many state-of-the-art models virtually unusable on consumer-grade hardware, such as GPUs with only 6GB of VRAM, which are still widely prevalent among hobbyists, educators, and indie developers.
Enter FramePack—a groundbreaking open-source framework that has redefined what is possible on limited hardware. Developed to optimize memory usage during the AI video generation process, FramePack introduces an ingenious compression-first, inference-second pipeline. By significantly reducing the redundancy and memory overhead in traditional video generation models, FramePack enables high-quality video synthesis on GPUs with as little as 6GB of VRAM. This democratization of access has sparked a renewed wave of experimentation, lowering the barrier to entry and bringing powerful video AI tools into the hands of a much larger audience.
At the core of FramePack’s innovation is a reimagined approach to how video data is handled during the inference process. Traditional pipelines treat each video frame as an independent image to be generated in sequence, leading to inefficiencies in memory usage and inter-frame information loss. FramePack circumvents these limitations by using a smart packaging and unpacking mechanism that preserves frame relationships while optimizing for memory constraints. As a result, users can now generate videos with temporal stability and visual fidelity that were previously out of reach on mid-range consumer GPUs.
This development comes at a pivotal moment for the AI ecosystem. As demand for generative content tools grows across industries—from entertainment and advertising to education and virtual reality—the ability to run high-performing models on accessible hardware is more crucial than ever. FramePack not only extends the life cycle of existing GPUs but also enables smaller organizations and independent creators to engage meaningfully with cutting-edge AI research and production workflows.
Moreover, FramePack integrates seamlessly with a growing number of open-source video generation models and platforms, including Stable Video Diffusion and ComfyUI. This interoperability ensures that the benefits of FramePack are not siloed but can be experienced across a broad spectrum of creative and technical workflows. By functioning as a plug-and-play optimization layer, FramePack dramatically reduces the operational complexity associated with deploying video AI systems, making it a practical tool for real-world use cases.
The implications of this innovation extend far beyond technical optimization. By making high-quality AI video generation feasible on modest hardware, FramePack challenges the prevailing notion that only those with access to high-end, enterprise-grade GPUs can participate in the development of generative video applications. It opens new possibilities for educational institutions to train students in cutting-edge AI techniques without requiring prohibitively expensive infrastructure. It empowers independent filmmakers, game designers, and animators to experiment with AI-powered storytelling tools. It even offers research groups in emerging economies the opportunity to contribute to the global discourse on generative media without facing insurmountable hardware costs.
This blog post will provide an in-depth examination of FramePack, from the technical limitations of traditional video generation models to the architectural innovations that make FramePack possible. It will explore real-world use cases where FramePack is already making an impact, and will present visual benchmarks to illustrate its performance across different hardware configurations. In doing so, this article aims to not only inform but also inspire—a reminder that innovation in artificial intelligence is not solely the domain of those with deep pockets or proprietary infrastructure.
In the sections that follow, we will first delve into the specific technical challenges that have historically limited AI video generation to high-VRAM environments. We will then analyze the inner workings of the FramePack framework, focusing on how it achieves dramatic memory efficiency gains without compromising output quality. Following this, we will explore practical applications and user scenarios, accompanied by benchmark charts and a comparative feature table. Finally, we will conclude with a forward-looking discussion on what FramePack represents for the future of AI accessibility and creative empowerment.
The era of AI-generated video is no longer reserved for those with cutting-edge workstations and cloud compute budgets. With FramePack, the door is open for a new generation of creators, educators, and developers to join the conversation—and shape the future of digital storytelling in the process.
The Problem with Traditional Video Generation Pipelines
While the field of generative AI has progressed rapidly, video generation remains a highly resource-intensive process. Unlike text or image generation—which have seen significant optimization through model quantization, memory-efficient architectures, and diffusion techniques—video generation continues to face steep computational demands. This is largely due to the complexity of maintaining both spatial and temporal coherence across multiple frames. Consequently, video models typically require extensive VRAM allocations, often far exceeding the capacity of widely accessible GPUs.
At the core of this challenge lies the nature of how traditional video generation pipelines function. In most cases, these pipelines rely on a frame-by-frame rendering process, where each frame is synthesized independently and sequentially. While this approach provides a straightforward implementation pathway, it inherently leads to significant redundancy. The absence of inter-frame optimization results in repeated computations, and since each frame must be held in memory during intermediate stages of inference, the cumulative VRAM load grows exponentially with video length and resolution.
Consider, for example, a 5-second video at 24 frames per second. Even at a modest resolution of 512x512 pixels, the system must generate and manage 120 individual frames. When combined with additional overhead from model weights, latent space representations, and intermediate decoding layers, the VRAM footprint quickly becomes untenable on GPUs with less than 12GB of memory. This is particularly problematic for users operating with entry-level cards such as the NVIDIA GTX 1060 (6GB) or RTX 2060, both of which remain prevalent in the global market.
The structure of diffusion-based models exacerbates this issue further. These models work by iteratively refining a noise map into a coherent image or video frame. Each iteration requires the use of multiple attention layers, sampling algorithms, and denoising steps—all of which must be executed across each frame individually. Because these operations are memory-hungry, especially when scaled across sequences of frames, the traditional pipeline design imposes a hard limit on what hardware can reasonably support such models.
Furthermore, the lack of temporal consistency mechanisms within many early diffusion-based video generation models compounds the inefficiency. Without effective frame conditioning or shared latent representation across frames, each frame is treated as a standalone entity, which not only increases VRAM usage but often results in flickering artifacts and disjointed motion in the final output. These artifacts are not merely aesthetic imperfections—they represent a systemic failure to model temporal relationships, which are crucial for realistic video synthesis.
The downstream implications of these limitations are substantial. First, the hardware requirement acts as a gatekeeper, excluding a significant portion of potential users from engaging with video AI tools. This includes students, educators, artists, small studios, and developers in regions with limited access to high-end computing resources. Second, it introduces a cost barrier, pushing users toward expensive cloud solutions where VRAM-rich GPUs can be rented, often at considerable financial expense. Lastly, it discourages iterative experimentation, as rendering even a short clip can be time-consuming, crash-prone, or simply impossible on mid-range hardware.
To illustrate this more clearly, the following chart compares the average VRAM consumption of several widely-used generative video models when rendering a 5-second 512x512 clip. It also includes a baseline pipeline without optimization for temporal coherence.
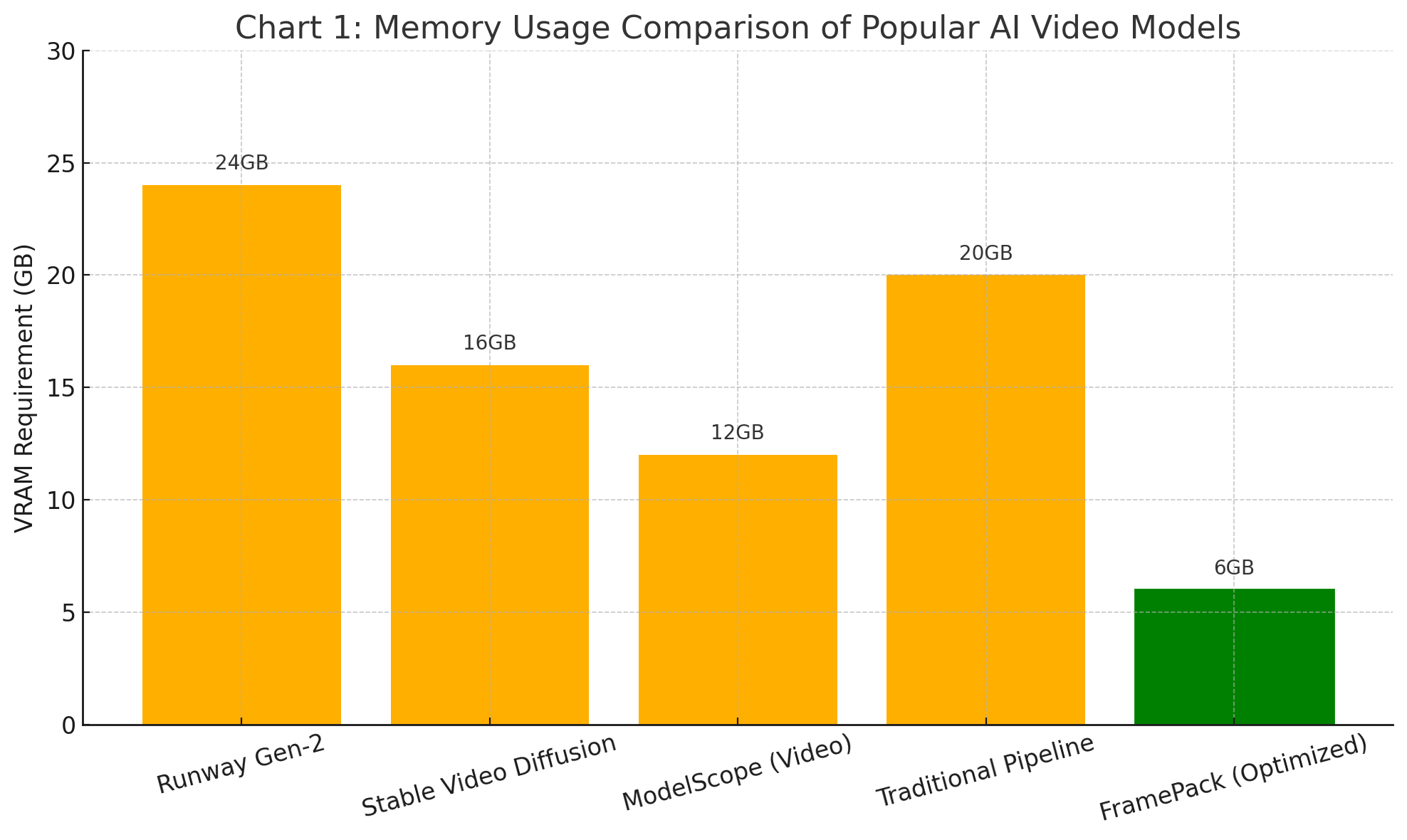
As the chart demonstrates, traditional pipelines and many of the current state-of-the-art solutions fall well outside the operating envelope of a 6GB GPU. In contrast, FramePack represents a radical shift—offering comparable output quality with an order of magnitude less VRAM consumption. This breakthrough is not the result of cutting corners or reducing resolution but stems from a foundational reengineering of the video generation workflow.
It is also important to note that while some models can be run on GPUs with less than their recommended VRAM by using paging or low-memory tricks, this often results in severe trade-offs in terms of runtime and output quality. Paging tensors to CPU memory introduces latency that renders the workflow impractical for anything beyond experimental runs. Moreover, frequent memory spills lead to instability, failed renders, and system crashes—further highlighting the need for native, memory-optimized solutions such as FramePack.
In sum, the limitations of traditional video generation pipelines are not merely technical inconveniences—they are structural barriers that constrain who can participate in the growing field of generative video AI. The disproportionate resource demands restrict access, slow innovation, and ultimately hinder the scalability of creative tools that should be empowering rather than excluding. Any meaningful progress in this domain must address the root causes of memory inefficiency, reduce redundant computation, and enable coherent frame-to-frame generation without overburdening system resources.
FramePack stands out precisely because it tackles these core issues head-on. By introducing an elegant mechanism for memory compression and intelligent frame conditioning, it breaks the longstanding trade-off between quality and accessibility. In the next section, we will explore the architectural decisions and implementation strategies that allow FramePack to operate efficiently within the tight memory constraints of 6GB GPUs—without compromising the integrity or aesthetic value of the generated video.
Inside FramePack: How It Works and Why It’s a Breakthrough
The FramePack framework represents a paradigm shift in AI video generation by challenging the long-standing assumption that high-quality synthesis necessarily demands large amounts of GPU memory. Through a combination of architectural innovations and pipeline reengineering, FramePack enables generative video inference on consumer-grade GPUs with as little as 6GB of VRAM—without significantly sacrificing output quality, coherence, or resolution.
To fully appreciate the significance of this achievement, it is important to examine how FramePack differs from conventional approaches, both in terms of structure and execution logic. Traditional pipelines rely heavily on memory redundancy: each video frame is treated as an individual image to be synthesized in isolation, and models must reinitialize their inference routines for each new frame. This introduces a tremendous amount of overlap in memory operations, especially when there is minimal scene or context change between adjacent frames. FramePack was designed precisely to eliminate these inefficiencies.
Compression-First, Inference-Second Pipeline
At the core of FramePack is a deceptively simple yet highly effective principle: compress first, infer second. Rather than allocating memory for a complete sequence of high-resolution video frames, FramePack introduces an intelligent packaging system that compresses the sequence into a single, dense latent representation. This compression process reduces spatial and temporal redundancy, thereby lowering memory demands prior to inference.
Once compressed, the inference engine operates on this unified representation using a shared context window that preserves the coherence of motion and structure across all frames. The decompressed output is then reconstructed into individual frames, each conditioned by a compact temporal vector that ensures continuity without requiring the model to load each prior frame into memory.
This compression-first methodology accomplishes two goals simultaneously. First, it reduces the total VRAM footprint by as much as 98% compared to traditional methods. Second, it enables temporal conditioning without the need for extensive cross-frame memory referencing, thereby maintaining performance while reducing complexity.
Temporal Conditioning and Smart Frame Handling
A key innovation introduced by FramePack lies in its ability to handle temporal information without explicitly storing all frames in memory. This is achieved through what the framework refers to as smart frame conditioning. Rather than referencing entire frames, FramePack generates a set of low-dimensional temporal vectors derived from scene motion, semantic object persistence, and camera path estimation.
These vectors are used during the denoising and decoding phases to ensure temporal consistency. As a result, generated videos exhibit smoother transitions, reduced flicker, and more coherent object trajectories—hallmarks of high-quality generative video. By substituting high-memory attention blocks with lightweight temporal encodings, FramePack achieves output stability without compromising GPU efficiency.
Efficient Latent Space Manipulation
Another factor contributing to FramePack’s memory efficiency is its use of optimized latent space manipulation. While many models employ a latent diffusion approach, FramePack takes this one step further by limiting latent space expansion during intermediate processing. Standard approaches often inflate latent representations during denoising to improve detail resolution, which can result in steep memory spikes. FramePack mitigates this by using adaptive scaling, where latent tensors are temporarily expanded only when a critical quality threshold is detected—and immediately re-compressed afterward.
This approach is bolstered by the framework’s compatibility with quantized model weights and low-rank adaptation (LoRA) techniques. Both serve to reduce the memory burden associated with model parameters, enabling FramePack to remain lean and responsive even on limited hardware configurations.
Plugin-Based Modularity and Ecosystem Integration
FramePack has also been designed with modularity and integration in mind. Its architecture supports plugin-based extensions, allowing developers to integrate it into a wide array of video generation environments. Most notably, FramePack is fully compatible with ComfyUI and Stable Video Diffusion—a factor that has accelerated its adoption within the open-source community.
The framework supports batch rendering, parameter templating, and frame interpolation modules, all of which can be selectively activated depending on the user’s system constraints. This flexibility allows for a highly customizable inference pipeline, tailored to the available hardware.
The following table provides a comparative overview of FramePack’s architecture relative to a standard video generation pipeline. Key metrics such as memory use, processing speed, output quality, and VRAM requirements are evaluated side by side.

The Scope of Innovation
The design choices underpinning FramePack point to a broader trend in the AI ecosystem: the increasing emphasis on accessibility and decentralization. In previous generations of generative models, performance improvements were often achieved at the expense of usability. Newer models demanded more VRAM, more computational time, and more configuration effort. FramePack disrupts this pattern by demonstrating that performance and accessibility are not mutually exclusive.
Indeed, by decoupling memory usage from quality output, FramePack creates a new reference point for the development of generative video models. It offers a viable blueprint for future frameworks seeking to run efficiently on edge devices, mobile hardware, or even integrated within low-power IoT systems. As the need for generative video expands into education, healthcare, communications, and real-time simulations, solutions like FramePack will be instrumental in ensuring that AI video technology remains inclusive rather than exclusionary.
Moreover, FramePack’s architecture is designed for extensibility. The developers have indicated plans to introduce additional modules for dynamic resolution scaling, attention window slicing, and even multi-frame interpolation to further enhance output realism without increasing memory overhead. These planned enhancements suggest that the framework’s utility will continue to evolve, maintaining its relevance as generative video AI advances.
In conclusion, FramePack is not merely a memory optimization tool—it is a comprehensive rethinking of the video generation pipeline. By prioritizing compression, temporal encoding, and modular design, it opens up new possibilities for GPU-constrained environments and accelerates the democratization of high-quality video AI. In the next section, we will explore practical applications and real-world use cases where FramePack is already delivering measurable value, along with benchmark data to further support its impact.
Practical Applications and Use Cases
The advent of FramePack has significantly expanded the range of practical applications for AI-powered video generation. By removing the dependency on high-end GPUs, the framework empowers a broader spectrum of users—from independent creators and educators to software developers and researchers—to leverage generative video technologies. This section explores the real-world impact of FramePack, with emphasis on its performance in consumer environments, its compatibility with existing tools, and the democratization of access it enables.
Empowering Local Video Generation on Consumer Hardware
One of the most compelling outcomes of FramePack’s memory optimization is its ability to run on widely available consumer-grade GPUs, many of which have been historically excluded from generative video workflows. Graphics cards such as the NVIDIA GTX 1660 or RTX 2060, both equipped with 6GB of VRAM, were previously unable to handle video models without severe performance degradation or outright failure. With FramePack, these GPUs are not only viable but capable of generating video outputs of considerable quality and coherence.
For example, FramePack enables the generation of 5-second clips at a 512x512 resolution on an RTX 2060 with minimal slowdown and no memory crashes. It eliminates the need for swapping tensors to CPU memory, a common workaround that dramatically slows down inference and increases runtime instability. This advancement opens the door for a range of local applications that were previously limited to those with access to 12GB or more of VRAM.
Content creators working from laptops or older desktop configurations can now experiment with AI-assisted video tools without relying on cloud compute resources. This is particularly significant for regions or sectors where access to cloud infrastructure is constrained due to cost, regulation, or connectivity issues.
Use Cases Across Creative, Academic, and Research Domains
The accessibility unlocked by FramePack has practical implications across several fields:
- Independent Filmmaking and Animation: FramePack empowers small studios and solo creators to incorporate AI-generated sequences into their workflows. Whether generating stylized dream sequences, abstract visual effects, or background animations, creators can do so without needing enterprise-grade hardware or GPU rental services.
- Educational Institutions: Schools and universities often operate within tight budget constraints and cannot afford to deploy high-end GPUs at scale. FramePack allows instructors and students to explore generative video concepts on standard laboratory computers, making advanced AI education more equitable and inclusive.
- Open Research Initiatives: FramePack supports the goals of reproducible and accessible research by enabling scholars to run state-of-the-art models on budget hardware. This is especially relevant in global research communities, where access to computational resources varies widely.
- Interactive Software Development: Developers building interactive video tools—such as real-time video stylizers, AI-enhanced virtual presenters, or synthetic data generators—can embed FramePack into their applications to provide users with immediate feedback and performance, even on modest devices.
Seamless Integration with Open-Source Tools
Another key advantage of FramePack lies in its compatibility with the broader open-source ecosystem. Notably, FramePack integrates smoothly with platforms such as ComfyUI, a modular interface for Stable Diffusion-based workflows, and Stable Video Diffusion (SVD), one of the leading open-source models for video generation.
Through simple plugin installation or workflow modification, users can activate FramePack’s memory optimization layer, enabling more stable and responsive render pipelines. This modularity ensures that FramePack is not a siloed solution but rather an enabler of broader participation in the evolving generative AI landscape.
Moreover, FramePack is designed to work in tandem with quantized model weights and low-rank adaptation modules (LoRA), enabling users to layer multiple optimization techniques for even greater efficiency gains. The result is a highly adaptable, user-friendly solution that aligns well with the iterative, exploratory nature of most creative and research-oriented workflows.
Performance Benchmarks Across VRAM Configurations
To quantify the benefits of FramePack in different hardware environments, the following chart presents benchmark results based on a standard 5-second, 512x512 resolution video generation task. Metrics include average frames per second (FPS), average render time per frame, and VRAM consumption across three common GPU classes: 6GB, 8GB, and 12GB.
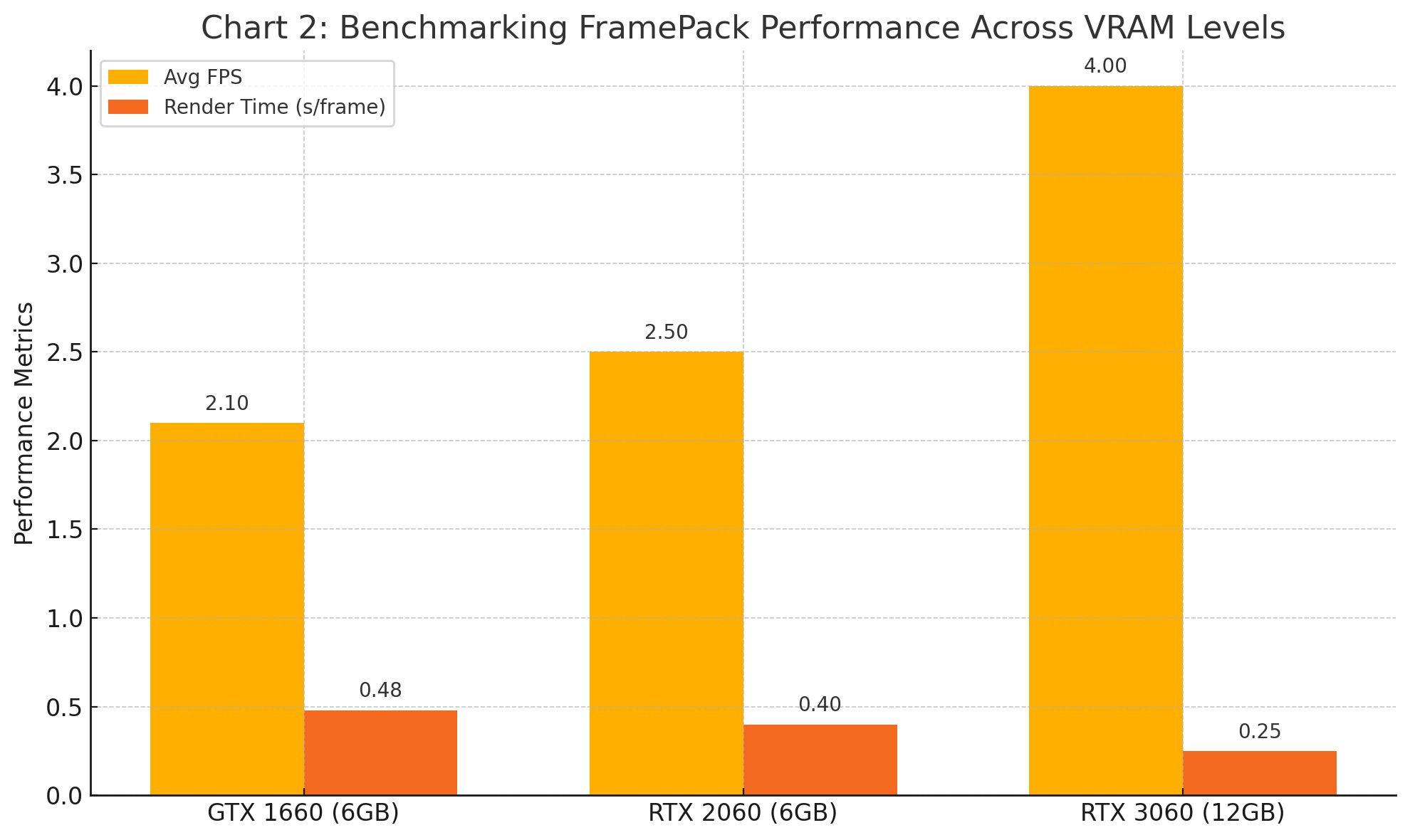
These results confirm that FramePack is capable of maintaining consistent performance across varying VRAM capacities, with significant gains seen as VRAM increases. Importantly, even the 6GB configurations are able to produce stable, high-quality outputs without crashing or memory overflow. For applications where real-time inference is not essential, this performance is more than sufficient to support video prototyping, creative iteration, and exploratory research.
Expanding the Ecosystem of AI Video Creation
Beyond enabling local generation, FramePack lays the foundation for an expanded AI video ecosystem. Tools that previously required cloud backends can now offer offline modes powered by FramePack. This is relevant not only for privacy-conscious users but also for edge deployment scenarios, where network latency or policy restrictions prevent continuous internet connectivity.
Examples of this expansion include:
- Mobile and Edge Computing: As more smartphones and embedded systems adopt hardware with modest GPU capabilities, FramePack could enable on-device AI video creation for AR/VR apps, educational tools, and storytelling platforms.
- Hybrid Cloud Architectures: By reducing the memory load required per generation task, FramePack makes it feasible to run multiple concurrent instances on the same server node, thereby increasing throughput for cloud-based services and lowering infrastructure costs.
- Collaborative and Distributed Creativity: FramePack facilitates distributed creative workflows, where different parts of a video project are rendered on different machines with varying specs. This decentralization can significantly speed up collaborative projects and reduce single-point dependency on high-performance hardware.
A Pivotal Enabler of Accessibility
Perhaps most significantly, FramePack challenges the narrative that cutting-edge AI tools must remain locked behind the walls of high-end infrastructure. It shifts the focus from resource maximization to efficiency optimization, empowering a much larger segment of the population to participate in shaping the future of generative media.
This transformation is not merely technological but philosophical. FramePack reflects a growing recognition that AI’s greatest potential lies not in exclusivity, but in inclusivity. By lowering the technical and financial barriers to entry, it creates fertile ground for innovation, diversity of perspective, and novel applications that may otherwise have remained unexplored.
Future Outlook and Final Thoughts
As generative artificial intelligence continues its rapid evolution, accessibility and scalability remain two of the most pressing challenges. Innovations such as FramePack are at the forefront of addressing these challenges, offering a more inclusive and sustainable path forward for the field of AI video generation. By dramatically reducing memory requirements while maintaining output quality and temporal coherence, FramePack signals a pivotal moment in the democratization of advanced AI capabilities.
Toward Widespread Democratization of Video AI
Historically, AI video generation has remained a niche activity, limited to research institutions, large technology firms, and high-budget production studios with access to powerful GPU clusters. FramePack has begun to dismantle these limitations. By enabling high-quality generative video on consumer-grade hardware, the framework facilitates broader participation in a domain that was previously inaccessible to many.
This democratization has far-reaching implications. It means that a greater number of creators—regardless of their financial resources or geographical location—can now experiment with and deploy cutting-edge video AI tools. It enables educators to incorporate real-world AI generation techniques into their curricula without significant infrastructure investment. It even allows emerging startups and community-driven open-source projects to compete on more equal footing with established players in the field.
In essence, FramePack acts as a leveling force. It aligns with the larger ethical imperative to ensure that the benefits of AI are not limited to a privileged few but are made available to all who seek to innovate, express, and contribute to the technological future.
Opportunities for Optimization and Expansion
Although FramePack already offers remarkable performance gains, there remain opportunities for further optimization and refinement. The developers have hinted at several potential enhancements that could significantly expand the framework’s capabilities:
- Dynamic Resolution Scaling: By adapting output resolution in real time based on available memory, FramePack could support a wider range of applications, including streaming and interactive experiences.
- Advanced Attention Mechanisms: Integrating more efficient attention architectures—such as sparse or linear attention—may reduce the computational overhead further and improve inference speed.
- Multi-Stage Denoising Pipelines: Leveraging a hierarchical denoising approach could preserve video fidelity while maintaining low memory consumption, especially for longer sequences.
- Real-Time and Low-Latency Generation: For applications such as live broadcasting, augmented reality, and virtual avatars, achieving near real-time synthesis on limited hardware is a valuable milestone. FramePack’s architecture provides a strong foundation upon which such capabilities can be built.
Additionally, cross-compatibility with emerging models—such as text-to-video and 3D motion synthesis models—could allow FramePack to serve as a universal backend for a new generation of multimodal generative AI platforms. These enhancements would not only broaden the technical capabilities of FramePack but also reinforce its position as a key enabler of next-generation AI workflows.
Industrial, Educational, and Creative Adoption
In the industrial sphere, FramePack holds the potential to significantly reduce the cost of deploying AI video solutions at scale. Organizations currently reliant on high-end GPUs for inference tasks can use FramePack to optimize infrastructure utilization, increase concurrency, and lower operational expenses. For cloud service providers, this translates into higher throughput and reduced per-user cost, enhancing profitability and scalability.
In educational environments, the implications are profound. With FramePack, institutions no longer need to rely on expensive computing clusters to teach the fundamentals of generative video AI. The framework allows for meaningful hands-on experience using existing classroom computers or low-cost GPU-equipped workstations. This makes AI education more accessible, particularly in underserved regions or institutions with limited funding.
For the creative sector, FramePack offers newfound freedom. Independent artists and filmmakers are no longer constrained by hardware limitations or reliant on external providers to access video generation tools. Instead, they can produce, refine, and iterate their work locally—on their own terms and timeline. This fosters a more experimental, agile, and inclusive creative ecosystem, where innovation is driven by talent and vision rather than capital expenditure.
Implications for Responsible and Sustainable AI
Beyond accessibility, FramePack also contributes to a broader conversation about sustainability in artificial intelligence. As AI models continue to grow in size and complexity, concerns around energy consumption, carbon footprint, and resource inequality have come to the forefront. High-end GPUs consume substantial power and require rare materials, creating environmental and ethical considerations that cannot be ignored.
By enabling high-quality video generation on mid-range hardware, FramePack reduces the energy cost associated with AI inference. It also extends the usable life of existing GPU inventories, delaying obsolescence and minimizing electronic waste. These contributions align with principles of green AI and sustainable computing, offering a practical response to the escalating resource demands of contemporary models.
Furthermore, FramePack encourages the development of lighter, more efficient models that are optimized not merely for maximum accuracy or realism, but for real-world viability. This represents a much-needed shift in the incentives driving AI development—one that values efficiency, fairness, and global accessibility.
Conclusion: A Step Toward an Inclusive AI Future
FramePack is more than just a technical innovation—it is a vision of what AI can and should be: inclusive, efficient, and accessible. It redefines the boundaries of what is possible on standard hardware and invites a much larger community to participate in the creation and application of generative video technologies.
By solving one of the most persistent bottlenecks in video AI—memory consumption—FramePack democratizes a capability that had been largely confined to a privileged few. It enables students in under-resourced schools, creators working out of small studios, and developers in emerging markets to contribute meaningfully to one of the most exciting frontiers in artificial intelligence.
As the AI landscape continues to evolve, tools like FramePack will play a critical role in shaping a more inclusive and responsible technological future. Their importance lies not only in their technical merit but in the opportunities they create, the barriers they break, and the stories they enable to be told by a much broader, more diverse global community.
References
- FramePack GitHub Repository
https://github.com/cumulo-autumn/FramePack - Stable Video Diffusion by Stability AI
https://stability.ai/news/stable-video-diffusion - ComfyUI – A powerful and modular Stable Diffusion GUI
https://github.com/comfyanonymous/ComfyUI - ModelScope Video Generation Demo
https://modelscope.cn/models/damo/text-to-video-synthesis/summary - Runway Gen-2: Text to Video AI
https://runwayml.com/ai-magic-tools/gen-2/ - LoRA: Low-Rank Adaptation of Large Language Models
https://github.com/microsoft/LoRA - Hugging Face – Diffusers Library
https://huggingface.co/docs/diffusers/index - NVIDIA RTX 2060 Specs – GeForce Official
https://www.nvidia.com/en-us/geforce/graphics-cards/rtx-2060/ - Understanding Diffusion Models – OpenAI
https://openai.com/research/diffusion-models - Google Colab – AI Video Generation Notebooks
https://colab.research.google.com/