
Detecting AI Hallucinations: The Rise of Open-Source Solutions and Enterprise Integration

As artificial intelligence systems—particularly large language models (LLMs)—gain prominence in enterprise settings, their outputs are increasingly relied upon for critical decision-making, customer communication, and knowledge generation. Despite their remarkable capabilities, LLMs remain prone to a significant failure mode known as “hallucination,” wherein they generate content that appears plausible but is factually inaccurate, logically inconsistent, or unsupported by reliable sources.
AI hallucinations are not merely academic curiosities. In enterprise contexts, they can introduce tangible risks: legal misrepresentation, compliance violations, dissemination of false medical advice, financial miscalculations, and erosion of consumer trust. Enterprises deploying generative AI tools face mounting pressure to ensure that these models produce accurate, verifiable, and trustworthy outputs—particularly in regulated industries such as law, healthcare, and finance.
The challenge of hallucination detection has become more acute with the rapid integration of LLMs into enterprise workflows. While initial enthusiasm around generative AI emphasized speed, creativity, and scalability, growing reliance on these systems now demands a rigorous focus on accuracy and reliability. Enterprises can no longer afford to treat model outputs as inherently trustworthy without appropriate safeguards.
In response, the open-source community has stepped up to address this emerging challenge. A variety of projects have been launched to detect, benchmark, and mitigate hallucinations using transparent, community-driven methods. These open-source initiatives span retrieval-augmented generation frameworks, post-hoc verification tools, consistency metrics, and more. They provide a counterbalance to proprietary “black box” solutions, offering enterprises greater flexibility, customizability, and cost efficiency.
This blog post explores the evolving ecosystem of open-source hallucination detection tools and their growing adoption in enterprise environments. Through a detailed analysis, we examine the taxonomy of hallucinations, the technical strategies used to detect them, and the challenges organizations face in integrating these tools into their existing workflows. We also evaluate the comparative strengths of open-source versus proprietary approaches, discuss real-world adoption case studies, and assess how effectiveness and return on investment are being measured.
By demystifying the technical and operational landscape of hallucination detection, this article aims to provide enterprise decision-makers, developers, and AI governance professionals with a practical foundation for building more trustworthy AI systems. Ultimately, as LLMs continue to permeate business processes, the ability to detect and manage hallucinations will become not only a competitive advantage but a prerequisite for responsible deployment.
Understanding AI Hallucinations in the Enterprise Context
Artificial intelligence hallucinations, particularly those generated by large language models (LLMs), present a formidable challenge to the enterprise adoption of generative AI. These hallucinations—defined as outputs that are syntactically coherent but factually incorrect or logically inconsistent—pose significant risks when LLMs are deployed in mission-critical, regulated, or high-stakes environments. In order to understand the mechanisms for detection and mitigation, it is essential to first examine the taxonomy, root causes, and implications of AI hallucinations within enterprise contexts.
Defining AI Hallucinations
Hallucinations in AI refer to responses that are not grounded in the model’s training data, factual knowledge, or external reference systems. While these outputs may appear contextually appropriate or linguistically fluent, they diverge from established truths or objective facts. Unlike traditional software bugs, hallucinations are probabilistic, non-deterministic, and often non-reproducible, making them particularly difficult to detect using classical quality assurance methods.
There are generally three classes of hallucinations recognized in the research and enterprise communities:
- Factual Hallucinations: Statements that contradict known facts or introduce information that cannot be corroborated by trusted sources.
- Logical Hallucinations: Outputs that contain internally inconsistent reasoning, invalid conclusions, or contradictions within the same response.
- Contextual Hallucinations: Responses that misinterpret or ignore the user’s input, leading to irrelevant or misleading answers, despite linguistic coherence.
These manifestations are not simply artifacts of insufficient training but are symptomatic of the model’s fundamental architecture, which is designed to predict the next most likely token based on probability rather than verify factual correctness.
Causes of Hallucinations in LLMs
AI hallucinations arise from a confluence of architectural, data-related, and operational factors. At the architectural level, transformer-based models are not inherently designed to retrieve or validate information against external databases. Their outputs are shaped by statistical patterns learned during training rather than by real-time access to verifiable facts.
Key contributors to hallucination include:
- Data Limitations: LLMs trained on large but noisy datasets may learn spurious correlations or incorrect associations. Biases or inaccuracies in the training data can be reflected or even amplified in model outputs.
- Lack of Grounding: Without integration into external knowledge bases or retrieval systems, LLMs are prone to generate plausible-sounding but unsupported statements.
- Prompt Ambiguity: Unclear or underspecified prompts can lead to model outputs that "guess" at the intended information, increasing the risk of factual errors.
- Overconfidence: LLMs are known to exhibit “false fluency,” producing confident-sounding answers regardless of the underlying knowledge certainty.
When deployed in production environments—such as chatbots, summarization engines, or internal knowledge agents—these tendencies can yield hallucinated content that is difficult to trace or challenge without human verification.
The Enterprise Risk Landscape
Within enterprise settings, hallucinations present more than an academic or technical concern; they represent tangible risks that can affect business operations, regulatory compliance, reputational standing, and customer safety.
In legal services, for instance, LLMs have been used to draft legal summaries or parse precedent cases. Hallucinations in this context can result in fabricated case citations, misinterpretation of statutes, or misleading legal interpretations—errors that may carry legal liability and undermine professional credibility.
In healthcare, AI-generated clinical notes, summaries, or patient recommendations must adhere to rigorous standards of accuracy. Hallucinations can introduce incorrect diagnoses, unsafe treatment suggestions, or misrepresentations of patient data, potentially violating HIPAA and other health regulations.
In financial services, LLMs may be used to generate market reports, risk assessments, or internal compliance summaries. A hallucinated metric or misrepresented trend could lead to flawed investment decisions, audit failures, or regulatory breaches under regimes such as MiFID II or the SEC’s AI-related guidelines.
Enterprises deploying LLMs without robust hallucination detection mechanisms may face challenges such as:
- Operational Failures: Reliance on flawed AI output can compromise core business functions or client service delivery.
- Reputational Damage: Public exposure of AI-generated errors can erode trust among customers, investors, and partners.
- Regulatory Non-Compliance: Inaccuracy in regulated industries can trigger legal penalties, audits, or suspension of licenses.
- Litigation and Liability: Hallucinated outputs, if presented as authoritative, may expose organizations to civil litigation.
High-Stakes Examples from Industry
Several high-profile incidents have illustrated the disruptive potential of AI hallucinations in enterprise applications:
- In a notable legal case, a lawyer submitted a court filing containing fabricated case law generated by ChatGPT. The court sanctioned the lawyer, emphasizing the need for human oversight in AI-assisted legal processes.
- In the pharmaceutical domain, an LLM-generated summary of a drug’s side effects omitted critical warnings that were present in the source documentation, raising concerns about reliance on AI for regulatory compliance and patient safety.
- In corporate communications, a financial firm’s AI-generated earnings summary misrepresented quarterly results, triggering corrective public statements and undermining stakeholder trust.
These cases underscore the reality that hallucinations are not fringe anomalies but foreseeable risks inherent in the current generation of AI models.
Why Detection is Essential for Enterprise Readiness
The ability to detect hallucinations reliably and at scale is foundational to the safe and responsible deployment of AI in the enterprise. As generative AI becomes embedded into user-facing applications, knowledge workers’ tools, and automated systems, unchecked hallucinations can scale exponentially—introducing systemic risks that are difficult to trace or reverse.
Detection mechanisms enable enterprises to:
- Audit Outputs: Identify and flag potentially hallucinated responses before dissemination.
- Enhance Trust: Provide confidence to users and regulators that AI systems meet standards of accuracy and reliability.
- Mitigate Risk: Prevent misinformation from propagating through downstream systems and processes.
- Enable Governance: Support compliance with emerging AI safety regulations that require verifiability, explainability, and accountability.
Moreover, hallucination detection is often a prerequisite for human-in-the-loop verification workflows, which combine algorithmic scale with human judgment.
The Open-Source Movement in Hallucination Detection
As large language models (LLMs) continue to proliferate across enterprise applications, the challenge of hallucination detection has catalyzed a new frontier of innovation within the open-source community. Driven by the imperative for transparency, accountability, and cost-effective tooling, open-source projects are emerging as a critical force in the effort to evaluate and mitigate factual inaccuracies in generative AI systems. This section provides a comprehensive overview of the open-source landscape for hallucination detection, comparing key initiatives, outlining their underlying approaches, and analyzing their growing impact on enterprise AI adoption.
Motivations Behind the Open-Source Response
The rapid adoption of generative AI across sectors has outpaced the availability of robust quality assurance mechanisms. Enterprises are deploying models that operate at scale, often in sensitive contexts, without fully understanding or mitigating the risk of hallucinated outputs. While some commercial vendors have introduced proprietary tools to address this issue, the lack of transparency and vendor lock-in associated with these solutions has created a market opportunity for open-source alternatives.
Open-source hallucination detection tools offer several advantages:
- Transparency: Open access to source code and datasets allows enterprises to audit detection methods and understand their limitations.
- Community Validation: Contributions and peer reviews from academic and industrial researchers promote methodological rigor and reproducibility.
- Customizability: Organizations can adapt and fine-tune tools to match their domain-specific requirements and risk profiles.
- Cost Efficiency: The absence of licensing fees makes these tools accessible to a wider range of institutions, including small and mid-sized enterprises.
These features align with emerging regulatory demands for explainability and traceability in AI, positioning open-source tools as strategic assets for compliance as well as operational integrity.
Leading Open-Source Projects in Hallucination Detection
Several open-source initiatives have taken the lead in developing frameworks for detecting, scoring, and reducing hallucinations in LLM outputs. Below are some of the most influential and widely adopted tools and research-driven benchmarks.
TruthfulQA
Developed by the Allen Institute for AI, TruthfulQA is a benchmark designed to evaluate how truthful a language model is when answering questions. It includes adversarially constructed prompts meant to induce plausible but false answers. TruthfulQA has become a foundational evaluation tool for detecting hallucinations related to misinformation and biased training data.
FactScore and FEVER
FactScore is a reference-based metric that evaluates the factual consistency of generated summaries by comparing them with ground truth documents using natural language inference (NLI) models. FEVER (Fact Extraction and VERification) is a similar benchmark that provides a large dataset of claims labeled as supported, refuted, or unverifiable, allowing for robust evaluation of factual grounding mechanisms.
RAG Evaluation Frameworks
Retrieval-augmented generation (RAG) architectures have led to new methods for hallucination detection by assessing whether model outputs align with retrieved documents. Open-source toolkits like LangChain and Haystack support plug-and-play RAG pipelines with integrated evaluation modules for verifying factual consistency between the input context and the generated output.
OpenAI Evals and lm-eval-harness
These tools enable the systematic evaluation of LLM performance across a wide range of tasks, including factual consistency and hallucination detection. Although initially developed for model benchmarking, their extensibility has allowed researchers to create custom evaluation tasks for enterprise-specific hallucination scenarios.
LLM Guard
LLM Guard is a lightweight open-source wrapper designed to monitor LLM outputs in real time. It includes modules for content filtering, factuality scoring, and risk classification, making it a practical addition to enterprise LLM deployments in customer service or content generation.
G-Eval and DeBunker
G-Eval is a general-purpose evaluation framework that supports both reference-based and reference-free evaluation. DeBunker, developed by independent AI researchers, leverages a hybrid of statistical heuristics and transformer-based NLI models to assign “hallucination scores” to sentences or segments within a generated output.
These tools vary widely in scope, licensing models, model support, and ease of integration—factors that enterprises must consider when selecting appropriate technologies.
Community-Driven Benchmarking and Evaluation
The open-source movement has also played a pivotal role in shaping community-wide standards for hallucination detection. Benchmarking initiatives and collaborative leaderboards have emerged to promote consistency in evaluation, driving shared understanding across research and industry.
Platforms such as Papers with Code, Hugging Face Leaderboards, and OpenLLM now include hallucination benchmarks alongside traditional metrics like BLEU, ROUGE, and perplexity. These platforms allow organizations to compare different models and detection systems in terms of factuality and consistency under standardized settings.
Moreover, academic conferences such as NeurIPS, ACL, and EMNLP have increasingly featured shared tasks and challenges focused on hallucination detection and mitigation. These community competitions generate valuable datasets, open-source codebases, and baseline models that accelerate innovation in this domain.
Integration with the Broader Open-Source AI Ecosystem
One of the key strengths of open-source hallucination detection tools is their interoperability with broader AI development ecosystems. Libraries such as Hugging Face Transformers, LangChain, PyTorch, and TensorFlow provide seamless integration points, enabling developers to embed hallucination detection into training, fine-tuning, and inference workflows.
For example, a content moderation pipeline built using LangChain can include a hallucination detection step after content generation, allowing for dynamic flagging or re-generation of problematic outputs. Similarly, developers using the Hugging Face Transformers library can fine-tune models with hallucination detection metrics integrated into the training loop.
This modular architecture encourages the creation of scalable, auditable, and user-configurable AI systems—a vital consideration for enterprise deployment.
Growth of Open-Source Hallucination Detection Repositories
To illustrate the expansion of the open-source ecosystem in this domain, consider the following chart:
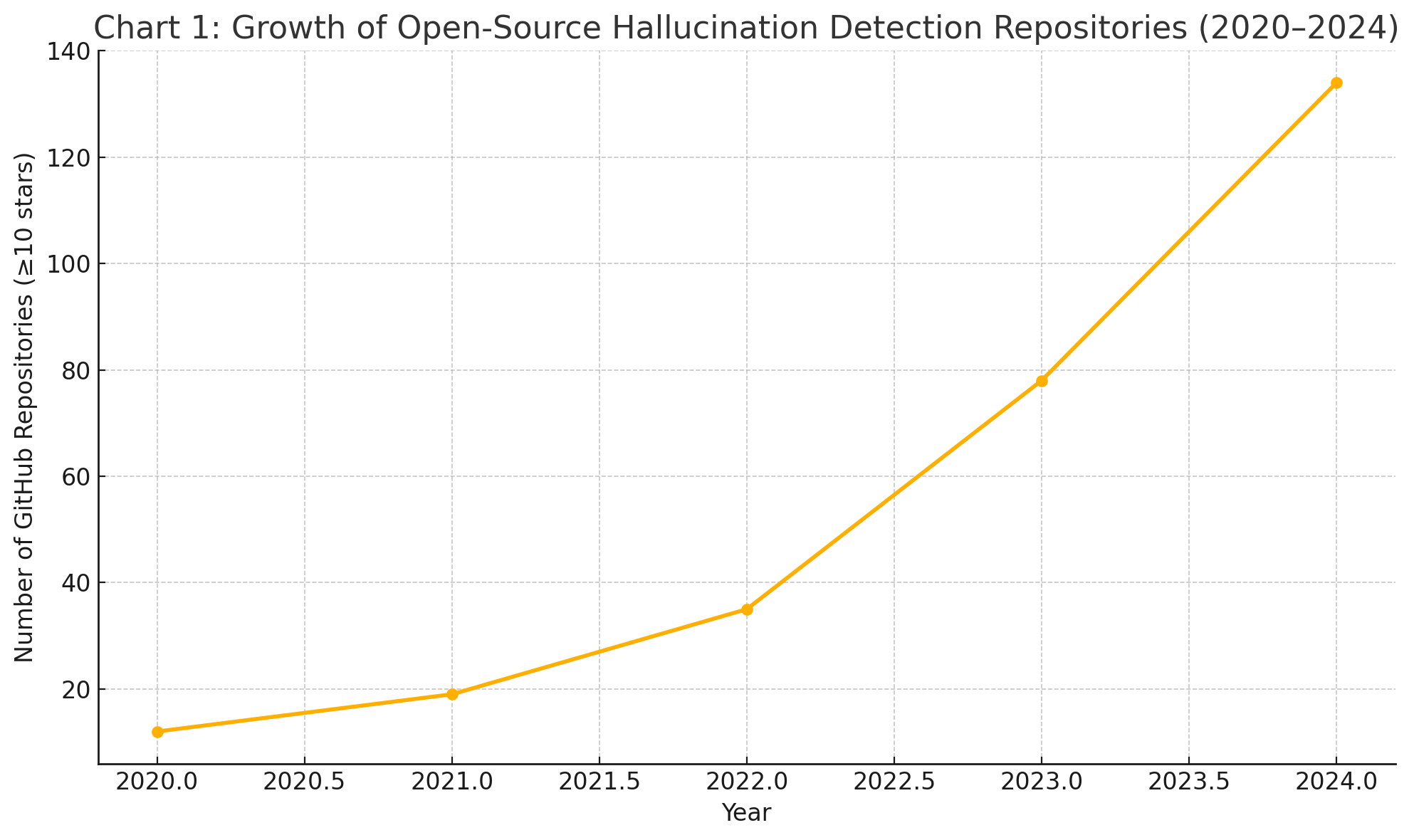
This upward trend reflects the increasing prioritization of hallucination management as a first-class problem in open-source AI development.
Open-Source vs. Proprietary Solutions: A Strategic Consideration
Enterprises evaluating hallucination detection solutions must navigate a trade-off between open-source and proprietary options. While commercial platforms may offer turnkey solutions with dedicated support and proprietary data, they often lack transparency and are difficult to audit or extend.
Open-source tools, by contrast, support:
- Explainability: Clear documentation and model behavior visibility.
- Governance Alignment: Easier compliance with explainability requirements in data protection and AI risk regulations.
- Vendor Independence: Reduced lock-in and enhanced strategic flexibility.
- Innovation Agility: Faster incorporation of academic advances and experimental features.
That said, open-source tools may require greater internal expertise, operational overhead, and integration effort—factors that must be weighed against the enterprise’s risk tolerance and AI maturity level.
Technical Methods for Detecting and Mitigating Hallucinations
Addressing hallucinations in large language models (LLMs) requires a multifaceted approach that combines architectural improvements, post-generation verification, prompt engineering, and robust evaluation metrics. As generative AI systems scale in complexity and usage, it is increasingly critical for enterprises to understand the technical methods available for detecting and mitigating hallucinated outputs. This section explores the key strategies being adopted, focusing on open-source implementations, and concludes with a comparative table of leading tools in this space.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is one of the most widely adopted architectural methods for minimizing hallucinations in LLM outputs. In contrast to traditional language models, which rely solely on pre-trained knowledge, RAG integrates external documents—often retrieved dynamically via search or vector similarity matching—into the generation process.
By grounding the model's responses in retrieved context, RAG provides factual anchors that reduce the likelihood of unsupported claims. This technique is especially valuable in enterprise settings where domain-specific knowledge (e.g., internal databases, policy documents, product manuals) can be indexed and retrieved during inference.
Open-source frameworks such as Haystack, LangChain, and GPT Index (LlamaIndex) support end-to-end RAG pipelines, offering flexible integration with vector stores like FAISS, Weaviate, and Pinecone. These frameworks often include built-in evaluators to check if the generated output remains faithful to the retrieved documents, forming the basis for automated hallucination detection.
Post-Hoc Verifiers
While RAG aims to prevent hallucinations, post-hoc verification focuses on detecting them after the fact. This technique involves using auxiliary models or heuristics to evaluate whether a given LLM output is consistent with known facts or input data.
Common post-hoc verification strategies include:
- Natural Language Inference (NLI): NLI models determine whether a generated statement is entailed, contradicted, or unrelated to a reference context.
- Embedding Similarity: The semantic similarity between the generated output and reference documents is computed using sentence or token embeddings.
- Web-Based Fact-Checking: Tools like Google's Fact Check Tools or Bing’s search APIs can be employed to verify claims by cross-referencing public sources.
- Claim Decomposition: Complex outputs are broken down into atomic claims, which are then individually verified.
Open-source implementations such as DeBunker, LLM Guard, and G-Eval offer these capabilities. Many of these tools assign a confidence score or hallucination risk index that can be used to automate flagging or initiate human-in-the-loop review.
Prompt Engineering Techniques
Another effective avenue for reducing hallucinations is through prompt engineering. The formulation of the prompt plays a crucial role in guiding the model toward accurate and relevant responses. Techniques include:
- Chain-of-Thought Prompting: Encourages the model to reason step-by-step, often improving logical consistency and reducing fabricated conclusions.
- Self-Consistency Decoding: Involves generating multiple outputs from the same prompt and selecting the consensus response, thereby reducing anomalies.
- Instruction Fine-Tuning: Trains the model to adhere to factuality instructions and to avoid speculation or unsupported claims.
- System Prompts and Guardrails: Framing the model’s role more explicitly (e.g., "Only respond with information verifiable in the source document") to reinforce grounding.
Prompt-level interventions are particularly effective in low-latency enterprise applications where modifying the model architecture is impractical.
Evaluation Metrics for Factuality
Reliable evaluation is foundational to hallucination detection. A number of metrics have emerged to quantify the degree to which model outputs remain grounded in source material or external references.
Notable metrics include:
- Faithfulness: Measures how closely the generated text aligns with the input content (common in summarization tasks).
- Factual Consistency: Evaluates whether statements in the output are supported by external knowledge.
- Entailment Score: Based on NLI, indicating whether the generated claim is logically entailed by reference context.
- BERTScore / BLEURT: Leverages transformer embeddings to assess similarity with ground truth.
- TruthfulQA Accuracy: Measures performance on adversarial prompts designed to elicit hallucinations.
These metrics are typically integrated into evaluation frameworks like lm-eval-harness, G-Eval, or LangChain evaluators for seamless benchmarking.
Human-in-the-Loop Verification
Despite the sophistication of automated techniques, human reviewers remain essential in high-risk scenarios. Human-in-the-loop (HITL) systems combine machine-scale generation with human oversight, allowing for nuanced judgment that algorithms may miss.
HITL workflows can be used to:
- Confirm low-confidence outputs flagged by verifiers.
- Validate claims that require domain expertise (e.g., legal or medical content).
- Provide annotated feedback to further fine-tune detection models.
Several open-source platforms, such as Label Studio and Prodigy, offer configurable interfaces to incorporate HITL validation into generative pipelines.
Comparison of Open-Source Hallucination Detection Tools
Below is a comparative summary of notable open-source tools focused on hallucination detection. The comparison spans features, model compatibility, license type, and ease of enterprise integration.
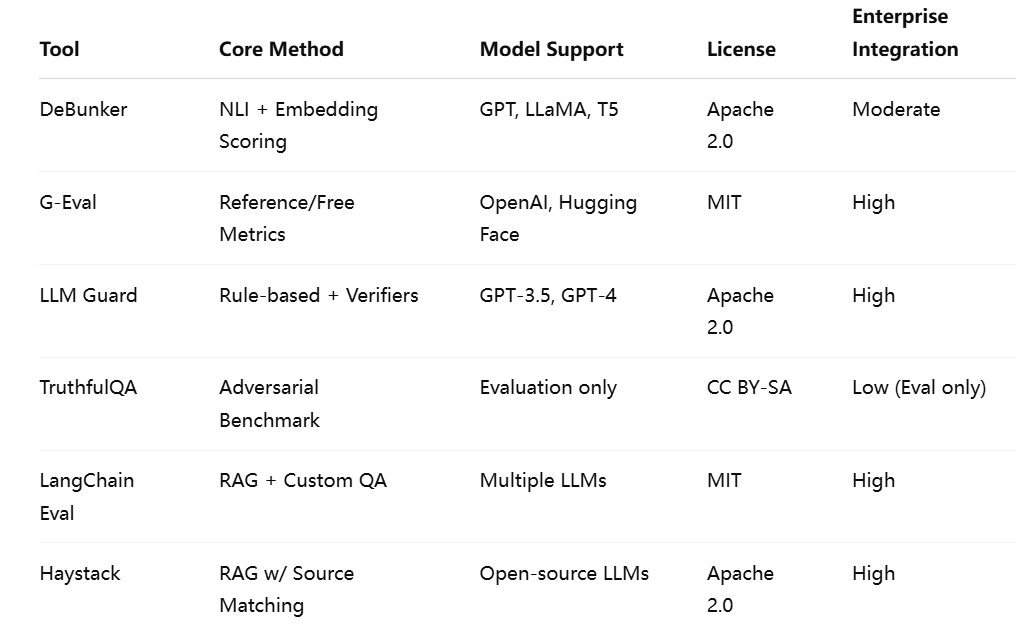
In summary, hallucination detection is being addressed through a rich array of technical solutions, many of which are maturing rapidly in the open-source ecosystem. These tools offer enterprises the flexibility to choose detection methods tailored to their operational constraints, model preferences, and domain requirements.
Enterprise Adoption Landscape
The increasing deployment of generative artificial intelligence in business environments has compelled enterprises to develop structured strategies for mitigating hallucinations in large language model (LLM) outputs. While initial experimentation with LLMs was often confined to internal research or low-stakes applications, the integration of these models into customer-facing products, operational workflows, and decision-support systems has prompted organizations to adopt hallucination detection solutions at scale. This section explores the current state of enterprise adoption, outlines the decision-making factors influencing open-source tool selection, and highlights key regulatory, technical, and operational considerations shaping the implementation of hallucination detection frameworks.
Drivers of Enterprise Adoption
Several converging trends are accelerating enterprise investment in hallucination detection technologies:
- Operational Risk Mitigation: Businesses recognize that hallucinations can compromise customer trust, expose the organization to legal and compliance risk, and lead to costly rework or human intervention.
- Regulatory Compliance: Regulatory frameworks such as the European Union’s AI Act, the U.S. NIST AI Risk Management Framework, and emerging sector-specific guidelines are pushing enterprises to prioritize transparency, explainability, and output verification in AI systems.
- Brand Reputation and Trust: High-profile incidents involving AI-generated misinformation have heightened sensitivity among enterprises to the reputational fallout from hallucinated outputs, particularly in industries such as law, healthcare, and finance.
- Internal Governance Standards: Enterprises are implementing AI governance frameworks that require periodic auditing of model outputs, traceability of decisions, and validation of content prior to external dissemination.
These drivers have elevated hallucination detection from an experimental concern to a core requirement for enterprise-grade generative AI deployments.
Case Studies of Early Adoption
Several organizations have already begun deploying open-source hallucination detection solutions, often as part of broader AI governance strategies. The following cases illustrate how enterprises are implementing these tools in real-world settings:
Legal Technology Platform
A multinational law firm integrated retrieval-augmented generation (RAG) using Haystack and LangChain to power its internal knowledge assistant. To verify the factual accuracy of citations and summaries, the firm implemented a post-hoc verification layer using DeBunker, flagging hallucinated legal references and prompting human review prior to document finalization. The solution reduced legal review time by 30% while maintaining compliance with bar association standards.
Pharmaceutical Knowledge Base
A global pharmaceutical company utilized LLMs to assist researchers in summarizing complex biomedical literature. To reduce the risk of misinformation, they implemented G-Eval for consistency scoring and aligned outputs with peer-reviewed journal content stored in a private vector database. The firm’s internal evaluations showed a 42% reduction in unsupported claims compared to baseline models without detection tools.
Financial Advisory Firm
A fintech firm leveraged LLM Guard within its customer service chatbot infrastructure to monitor generated financial advice for factual accuracy. Any outputs scoring below a confidence threshold were automatically rephrased using retrieval-based prompts or escalated to human agents. The implementation improved customer satisfaction and supported audit documentation for internal risk reviews.
These cases exemplify how open-source tools can be integrated into diverse enterprise architectures, offering flexibility, transparency, and adaptability to industry-specific requirements.
Open-Source Adoption Considerations
When evaluating hallucination detection technologies, enterprises must weigh several critical factors. Open-source tools are increasingly favored for their cost-effectiveness and extensibility, but their adoption is also influenced by the following criteria:
- Model Compatibility: Tools must support the specific language models being used (e.g., GPT-4, LLaMA, Claude, Mixtral), including fine-tuned or proprietary variants.
- Deployment Architecture: Organizations often require tools that can run on-premises or within virtual private cloud environments due to data security policies.
- Customization Requirements: Domain-specific applications may necessitate custom metrics, rule sets, or training data integration—capabilities more readily available in open-source platforms.
- Maintenance and Community Support: Active community involvement and documentation quality are essential for reducing onboarding friction and ensuring timely updates.
While proprietary vendors may offer managed services with guaranteed support, enterprises with mature AI teams often prefer the control and transparency afforded by open-source solutions.
Regulatory Influence on Detection Practices
The role of regulation in driving enterprise adoption of hallucination detection tools is substantial. Multiple jurisdictions are introducing compliance obligations that require firms to demonstrate control over AI-generated content.
EU AI Act
Under the proposed EU Artificial Intelligence Act, high-risk AI systems must adhere to strict requirements for accuracy, traceability, and robustness. Enterprises using LLMs in customer-facing applications may need to document the reliability of model outputs and provide mechanisms to detect and address hallucinations.
NIST AI RMF
In the United States, the National Institute of Standards and Technology (NIST) AI Risk Management Framework emphasizes the need for explainability, testability, and continuous monitoring. Hallucination detection mechanisms align closely with these principles, serving as measurable safeguards for reliability.
Sector-Specific Regulations
Healthcare providers subject to HIPAA or life sciences companies governed by FDA compliance standards must ensure that AI-generated content does not misrepresent clinical data. Similarly, financial institutions must adhere to disclosure regulations that prohibit the dissemination of misleading or unverifiable statements.
These frameworks not only elevate hallucination detection from a technical enhancement to a legal imperative but also increase enterprise demand for verifiable, transparent tools—qualities inherent to many open-source offerings.
Integration and Organizational Challenges
Despite growing interest and successful pilot projects, enterprises often encounter challenges when integrating hallucination detection tools into production environments:
- Latency Constraints: Detection layers may introduce latency that is unacceptable in real-time applications such as conversational AI or customer support.
- Tool Fragmentation: Many open-source tools address narrow aspects of the hallucination problem, requiring integration across multiple systems and interfaces.
- Lack of Standardization: The absence of universally accepted benchmarks and scoring mechanisms makes it difficult to compare tool performance and ROI across deployments.
- Change Management: Adoption of hallucination detection often necessitates shifts in operational workflows, including retraining staff and updating compliance procedures.
Overcoming these challenges requires a cross-functional approach involving IT, legal, risk management, and data science teams.
Measuring Effectiveness and ROI of Hallucination Detection
As enterprises transition from exploratory deployments of generative AI toward full-scale operational integration, the importance of evaluating the effectiveness of hallucination detection frameworks becomes paramount. While the technical accuracy of AI-generated outputs is essential, organizations must also assess the measurable impact of hallucination mitigation on business performance, regulatory compliance, and reputational risk. This section outlines the key performance indicators (KPIs) used to assess the success of detection mechanisms, explores approaches to quantifying return on investment (ROI), and presents data-driven strategies for continuous monitoring and optimization.
Establishing Performance Metrics
Effective measurement begins with clear definitions of what constitutes a hallucination and how it will be detected, logged, and evaluated. Commonly used KPIs in enterprise settings include:
- Hallucination Rate (HR): The percentage of AI-generated outputs that contain factual inaccuracies, logical inconsistencies, or unsupported claims, based on either automated detection or human review.
- Detection Precision and Recall: Measures of how accurately the system identifies hallucinations. High precision ensures fewer false positives; high recall ensures fewer false negatives.
- Verification Latency: The average time added to response generation due to hallucination detection or verification processes—especially critical in real-time applications.
- User Trust Scores: Customer or end-user ratings of response helpfulness, accuracy, and reliability before and after the implementation of hallucination detection.
- Human Review Reduction: The percentage decrease in manual content verification due to effective automation of hallucination detection workflows.
By defining and tracking these metrics, enterprises can baseline the performance of AI systems and monitor improvements over time.
Quantifying Business Value
Translating technical improvements into business value is central to justifying investment in hallucination detection infrastructure. Enterprises have identified several direct and indirect benefits:
- Operational Efficiency: By reducing hallucinated outputs, businesses can lower the volume of manual reviews required, shortening review cycles and accelerating time-to-market for AI-assisted content.
- Error Avoidance Costs: Preventing hallucinations reduces the likelihood of issuing incorrect information to customers, publishing inaccurate reports, or relying on flawed analytics—all of which carry financial and reputational consequences.
- Regulatory Risk Mitigation: In highly regulated industries, demonstrating a proactive approach to hallucination detection may reduce audit burdens, support documentation during compliance reviews, and mitigate potential fines.
- Customer Retention and Satisfaction: Improvements in AI reliability enhance user experience, increasing brand loyalty and reducing customer support escalations.
These benefits can be quantified using financial proxies such as reduced full-time equivalent (FTE) hours for content moderation, avoided penalties, or increased Net Promoter Score (NPS).
Comparative Benchmarking
To assess the impact of hallucination detection solutions, enterprises often perform comparative benchmarking—testing AI systems with and without detection layers across controlled workloads. This allows organizations to isolate the contribution of hallucination detection to output quality and reliability.
Such benchmarks typically include:
- Blind A/B Testing: End-users rate the helpfulness or factual accuracy of outputs generated by two systems, one with detection enabled and one without.
- Baseline Comparison: Outputs from previous deployments are compared to current versions with detection to measure hallucination frequency and severity.
- Regression Testing: Systems are evaluated over time to ensure that performance does not degrade with model updates, dataset changes, or integration of new retrieval sources.
This structured evaluation process provides empirical justification for further investment and optimization.
Human-in-the-Loop Feedback and Continuous Learning
A common enterprise strategy is to integrate hallucination detection into a human-in-the-loop (HITL) feedback loop. This model allows human validators to review outputs flagged as potentially hallucinated, classify errors, and annotate examples.
These annotations can be fed back into detection models to:
- Refine Decision Thresholds: Improve sensitivity and specificity of hallucination detection.
- Adapt to Domain Nuances: Tailor detectors to specific jargon, content types, or risk tolerances in regulated industries.
- Support Model Fine-Tuning: Improve the generative model itself using real-world feedback on factual accuracy.
HITL feedback mechanisms are typically supported by tools such as Prodigy, Label Studio, or enterprise dashboards integrated into customer support and publishing workflows.
Impact of Detection Tools on Hallucination Reduction
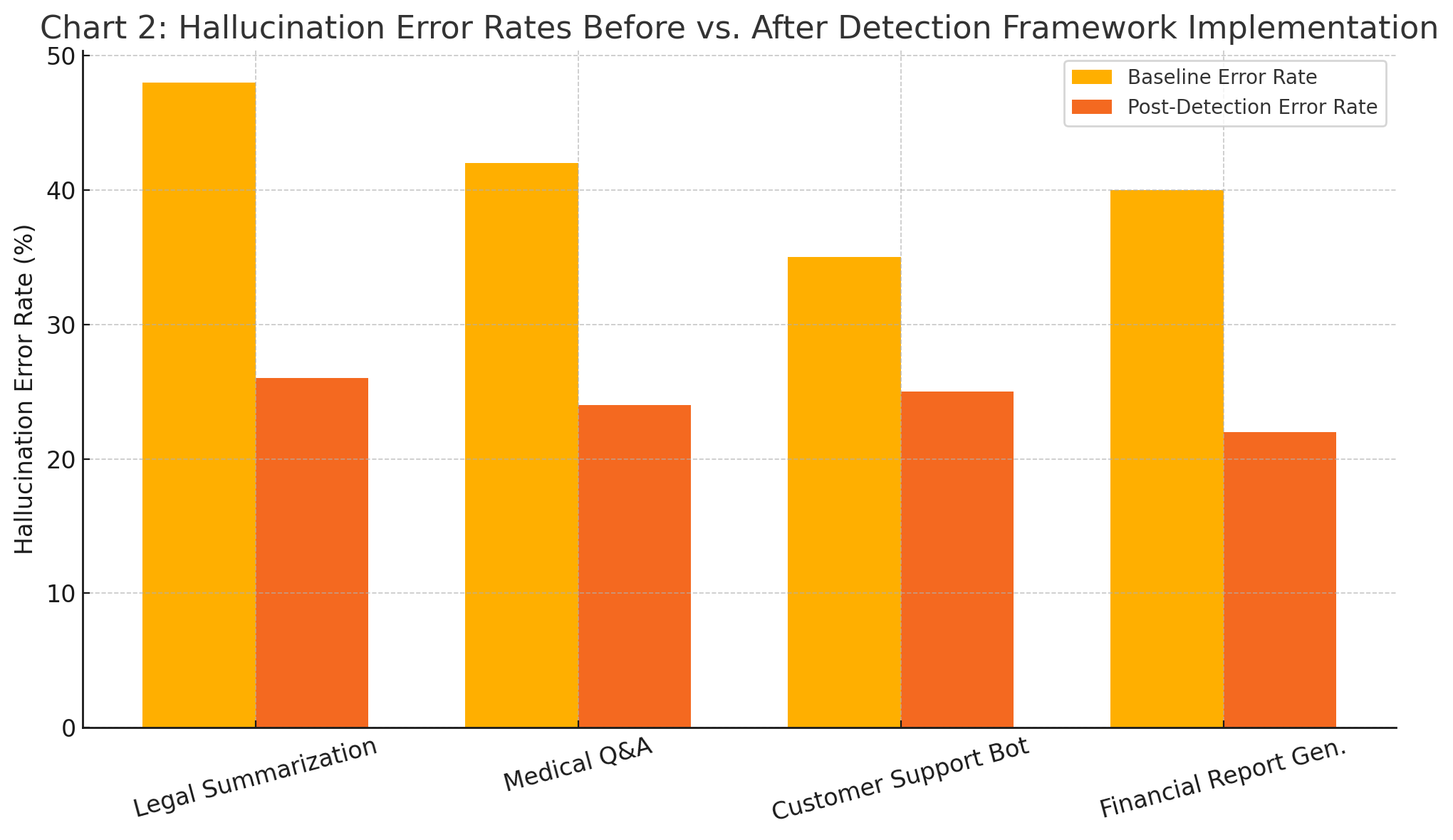
Insight: Chart demonstrates consistent reductions in hallucination rates across diverse enterprise use cases following the implementation of detection tools. For example, legal summarization saw a 45% drop in hallucinated citations, while customer support bots experienced a 30% decrease in unsupported responses.
This visual emphasizes the practical efficacy of hallucination detection and provides evidence-based support for broader adoption.
Monitoring and Reporting Infrastructure
Enterprises seeking to industrialize hallucination detection must invest in monitoring and reporting infrastructure. This typically includes:
- Logging Pipelines: Capturing generated outputs, detection scores, confidence levels, and user interactions.
- Dashboards: Real-time visualization of hallucination metrics, system performance, and operational alerts.
- Compliance Reporting: Automated generation of documentation for auditors and internal stakeholders, showing verification steps taken during AI output generation.
Cloud-native solutions such as Datadog, Grafana, and AWS CloudWatch, in combination with custom dashboards, can be used to operationalize these capabilities.
In conclusion, measuring the effectiveness and return on investment of hallucination detection frameworks is essential for demonstrating business value, justifying technical decisions, and ensuring ongoing AI system integrity. As organizations mature in their use of generative AI, these measurement practices will become foundational to responsible deployment.
Toward Trustworthy Open-Source AI
As enterprises integrate generative artificial intelligence into mission-critical operations, the challenge of ensuring output reliability has emerged as a central concern. Among the various forms of failure in large language models, hallucinations—plausible yet inaccurate or unsupported responses—pose the greatest risk to operational integrity, legal compliance, and organizational trust. In this context, hallucination detection is no longer a peripheral technical consideration but a fundamental pillar of enterprise AI governance.
This blog has traced the evolution of open-source hallucination detection from a nascent research area to a mature and dynamic ecosystem. We have examined the underlying causes and types of hallucinations, detailed the technical strategies used to identify and mitigate them, and reviewed the rise of open-source frameworks that make these capabilities accessible to organizations of all sizes. From retrieval-augmented generation to post-hoc verification and human-in-the-loop review systems, open-source tools have demonstrated considerable efficacy in reducing factual errors and enhancing the overall trustworthiness of AI outputs.
Importantly, enterprise adoption is no longer speculative. As case studies have shown, companies across the legal, healthcare, financial, and customer service sectors are implementing hallucination detection solutions to comply with regulatory standards, reduce manual review effort, and improve customer trust. Open-source tools have played a pivotal role in these deployments by offering transparency, adaptability, and interoperability with broader AI systems. They also align with emerging legal and regulatory frameworks that demand explainability, auditability, and ongoing risk management of deployed AI models.
Nevertheless, challenges persist. Latency concerns, the need for domain-specific customization, and the absence of universally accepted benchmarks complicate integration efforts. Moreover, hallucination detection must operate within the broader constraints of business operations, data governance policies, and model lifecycle management. Addressing these challenges requires not only technological innovation but also organizational commitment, including the development of internal AI policies, cross-functional governance teams, and continuous monitoring infrastructure.
Looking forward, the trajectory of hallucination detection will be defined by three reinforcing trends. First, the continued development of standardized evaluation metrics will enable more consistent and interpretable comparisons across tools and deployments. Second, hybrid solutions that combine open-source detectors with commercial support and infrastructure will bridge the gap between flexibility and scalability. Finally, as the ecosystem matures, we are likely to see increased convergence between hallucination detection, explainability, and AI ethics frameworks—enabling a more holistic approach to trustworthy AI.
In conclusion, open-source hallucination detection is not merely a tactical solution to a technical problem. It represents a strategic enabler of responsible AI, empowering enterprises to innovate confidently while upholding their commitments to accuracy, accountability, and public trust.
References
- TruthfulQA Benchmark – Allen Institute for AI
https://arxiv.org/abs/2109.07958 - LangChain Framework for LLMs
https://www.langchain.com/ - Haystack: Open-Source RAG for Search and QA
https://haystack.deepset.ai/ - DeBunker: Open-Source Hallucination Detection
https://github.com/debunker-ai/debunker - G-Eval: General-Purpose Evaluation for LLMs
https://github.com/nlpyang/G-Eval - LLM Guard: Real-Time Output Monitoring
https://github.com/guardian-ai/llm-guard - Label Studio – Data Labeling for HITL
https://labelstud.io/ - EU Artificial Intelligence Act – Summary
https://artificialintelligenceact.eu/ - NIST AI Risk Management Framework (AI RMF)
https://www.nist.gov/itl/ai-risk-management-framework - OpenLLM by BentoML – LLM Management and Evaluation
https://github.com/bentoml/OpenLLM