
DeepSeek-V3: A Breakthrough in Efficient AI Language Models

DeepSeek-V3 is the latest milestone in the evolution of artificial intelligence language models, heralded as a breakthrough in combining high performance with efficiency. It represents the third generation of the DeepSeek model series, pushing the boundaries of what a compact yet powerful AI language model can achieve. In recent years, AI researchers and industry leaders have been grappling with a trade-off: the most advanced language models (like GPT-4) demonstrate remarkable capabilities but demand enormous computational resources, while smaller models run efficiently but often lag in complex tasks. DeepSeek-V3 aims to bridge this gap.
This comprehensive overview examines DeepSeek-V3’s architecture, training, performance, and innovative design aspects. We will explore how DeepSeek-V3 compares to other prominent models such as OpenAI’s GPT-4, Meta’s LLaMA 2, and Mistral 7B. By highlighting relative strengths, weaknesses, and ideal use cases, the article will clarify where DeepSeek-V3 stands in the current AI landscape. The discussion is structured for a wide audience – from general tech enthusiasts and developers to AI researchers and business decision-makers – offering insights into both the technical achievements and the practical implications.
In the sections that follow, we will first set the stage by discussing the industry’s drive toward more efficient AI. We then delve into what makes DeepSeek-V3 unique: its novel architecture that delivers top-tier language understanding at a fraction of the typical computing cost. We will review the training data and methods that equipped DeepSeek-V3 with its capabilities, and analyze performance benchmarks showing how it measures up against GPT-4, LLaMA 2, and Mistral. Two charts illustrate comparative performance and efficiency, and a table distills key differences in design and metrics across these models. Finally, we consider real-world applications and the broader implications of DeepSeek-V3’s emergence, summarizing why this model is seen as a significant breakthrough in efficient AI.
The Quest for Efficiency in Language Models
In the AI community, bigger has often seemed better. Landmark models like GPT-3 and GPT-4 reached unprecedented levels of fluency and reasoning by scaling up to hundreds of billions (or even trillions) of parameters and ingesting virtually all of the internet’s textual data. However, this approach comes with steep costs. Large language models (LLMs) require immense computational power to train and deploy, making them expensive to operate and inaccessible to all but a few tech giants. Moreover, high latency and memory footprints can limit their usability in real-time applications. These factors have prompted a quest for more efficient language models – systems that can achieve comparable intelligence with fewer resources.
Over the past couple of years, researchers have demonstrated that smart design and training can sometimes beat sheer size. Techniques like model compression, knowledge distillation, and architecture optimization have given rise to a new wave of models that punch above their weight. For example, Meta’s LLaMA 2 showed that a carefully trained 70-billion-parameter model can outperform earlier 175B models in many tasks. Even more striking, the open-source Mistral 7B model (with just 7 billion parameters) was able to match or surpass much larger models on certain benchmarks by using optimized attention mechanisms and high-quality training data. These developments proved that well-crafted smaller models could deliver impressive results, challenging the notion that only the largest models are worthwhile.
Businesses and developers have welcomed this trend toward efficiency. Smaller models are cheaper to deploy, easier to fine-tune, and faster in inference, which is crucial for enterprise applications that may need to serve millions of requests or run on-device without cloud support. There is also a growing realization that one size does not fit all – an overly large model might be unnecessary for a given task, and a portfolio of differently sized models can offer more flexibility. In this context, DeepSeek-V3 arrives as a timely breakthrough. It is positioned as an efficient AI language model that significantly narrows the performance gap with the top-tier giant models while maintaining a leaner resource profile. By learning from the successes and limitations of its predecessors, DeepSeek-V3 exemplifies the industry’s shift towards optimizing quality-per-compute rather than only maximizing absolute quality at any cost.
Overview of DeepSeek-V3
DeepSeek-V3 is a state-of-the-art language model introduced in 2025 as the culmination of the DeepSeek research initiative’s focus on efficiency. It follows DeepSeek-V1 and V2, building on their foundation but making dramatic leaps in capability. In essence, DeepSeek-V3 offers near-leading performance on natural language tasks while using substantially fewer computational resources than models of comparable skill. This balance of power and efficiency is why it’s often described as a breakthrough.
What distinguishes DeepSeek-V3? At a high level, DeepSeek-V3 was designed with a “minimal necessary complexity” philosophy. Rather than simply enlarging the model, the developers of DeepSeek-V3 introduced architectural innovations (discussed in detail below) that allow it to utilize its parameters more effectively. The model reportedly achieves performance in the same league as GPT-4 on many benchmarks, despite having a fraction of the effective parameter count and running at lower latency. This was achieved without sacrificing breadth of capability: DeepSeek-V3 can engage in fluent open-ended conversations, solve complex reasoning problems, generate code, and answer questions across a wide range of domains. It has been pre-trained as a general-purpose language model and also comes with an instruction-tuned variant for conversational AI applications.
It is important to note that DeepSeek-V3 is widely accessible. Unlike some closed proprietary models, DeepSeek-V3 has been released under an open license, enabling researchers and organizations to deploy it on their own hardware or customize it via fine-tuning. The model’s creators have also provided reference implementations and tools for efficient inference, underlining their emphasis on practical usability. In summary, DeepSeek-V3’s arrival means that a much broader community can leverage nearly top-tier AI capabilities without the traditional barriers of extreme cost and infrastructure. The subsequent sections will unpack how DeepSeek-V3’s architecture and training make this possible, and where it stands relative to other leading models in the field.
Architecture and Design Innovations
At the core of DeepSeek-V3’s success is its innovative architecture. DeepSeek-V3 is built upon the transformer architecture (the same basic framework that powers models from GPT-3 to LLaMA), but it introduces several key design modifications to maximize efficiency. The guiding idea was to increase the model’s effective capacity (its ability to represent and solve complex tasks) without proportionally increasing the compute required for inference. To achieve this, DeepSeek-V3 employs a sparsely-activated model architecture — in other words, it doesn’t use all of its parameters for every single task, only the portions that are most relevant. Below are the notable architectural features that make DeepSeek-V3 unique:
- Mixture-of-Experts Layers (Sparse Transformer): DeepSeek-V3 uses a Mixture-of-Experts (MoE) approach in several of its transformer layers. Instead of one monolithic feed-forward network in each layer, there are multiple “expert” sub-networks, each specializing in different aspects of language patterns or contexts. When processing input, the model dynamically selects a few relevant experts for each token (for example, using gating networks that route information). This means that although the model has a very large number of parameters in total (e.g. on the order of 80 billion parameters), only a fraction of them are active for a given token’s computation. The result is an effective model capacity comparable to extremely large dense models, while the inference cost (time and memory per token) remains closer to that of a much smaller model. This sparse activation is a major factor in DeepSeek-V3’s efficiency breakthrough.
- Optimized Attention Mechanisms: Like most modern LLMs, DeepSeek-V3 relies on the self-attention mechanism to understand context. However, it incorporates optimized attention techniques that reduce memory usage and computation. One such technique is Grouped-Query Attention (GQA), where multiple attention heads share query/key projection matrices, thereby cutting down the memory overhead without hurting performance. This method was inspired by earlier models (for instance, LLaMA 2 70B and Mistral employed similar ideas) and allows DeepSeek-V3 to scale to long sequences more efficiently. Additionally, DeepSeek-V3 uses a sliding window attention for very long context handling – it can attend to very large text inputs (up to 16,000 tokens in context) by processing them in overlapping windows, mitigating the quadratic cost of naive attention across an extremely long sequence. In practical terms, this means DeepSeek-V3 can handle longer documents or dialogues in a single pass than models limited to the standard 2K or 4K token context, all while keeping memory requirements manageable.
- Enhanced Training Stability and Depth: The architecture of DeepSeek-V3 is deep and carefully tuned. It retains a standard transformer decoder stack structure but with additional layer normalization and gating mechanisms to ensure stable training even with the added complexity of MoE layers. The model has dozens of layers, and thanks to improved normalization techniques, it avoids issues like gradient instability that can plague very large or sparsely activated models. The design also includes residual connections and scaled initialization tailored to the mixture-of-experts framework, allowing the model to effectively coordinate the contributions of different experts.
- Extensible and Modular Design: Another innovation in DeepSeek-V3’s design is its modularity. The model is architected in segments that allow certain components to be updated or expanded independently. For example, one could add or refine an expert module focusing on a new domain (say, legal or medical text) without retraining the entire model from scratch. This modular design is forward-looking: it hints at future continuous improvement of DeepSeek models where new experts might be “plugged in” to extend knowledge or adapt to niche tasks, all while preserving the main model’s efficiency and integrity.
In summary, DeepSeek-V3’s architecture can be described as a sparse transformer with mixture-of-experts and optimized attention. It is a balanced blend of novel techniques and proven strategies from prior models. By activating only the needed portions of its vast parameter space for each input, DeepSeek-V3 achieves a remarkable efficiency. The architecture ensures that the model’s substantial knowledge and reasoning ability (bolstered by its many parameters and deep layers) are brought to bear only when relevant, avoiding unnecessary calculations. This design is a primary reason why DeepSeek-V3 can rival much larger systems in output quality while operating with a leaner compute footprint. The next section will look at how the model was trained and what data fed these experts and attention mechanisms to make them so effective.
Training Data and Methodology
Design alone doesn’t create a powerful language model – the training process and data are equally crucial. DeepSeek-V3 was trained on an extensive and diverse corpus of text, engineered to extract maximum performance from the model’s architecture. The training regime focused on two goals: broad knowledge acquisition and fine-grained skill learning, all while maintaining efficiency in training time and aligning with the model’s sparse structure.
Scale and Diversity of Data: DeepSeek-V3’s pre-training dataset consisted of approximately 1.8 trillion tokens, drawn from a wide range of sources. This scale puts it on par with some of the largest training runs (for reference, LLaMA 2 was trained on about 2 trillion tokens). The data sources included large swathes of the public web (webpages, news articles, forums), a comprehensive collection of books and academic papers, and specialized domains like code repositories, encyclopedic knowledge bases, and conversational transcripts. By covering everything from literature to software code, the model developed a rich knowledge base across many domains. This broad data exposure is reflected in DeepSeek-V3’s ability to handle diverse tasks – it can discuss history or science, write a poem, or debug a piece of code, switching domains with relative ease.
Quality Filtering and Curation: Because efficiency was a theme even in training, the DeepSeek team placed emphasis on data quality over sheer quantity whenever possible. The raw data was filtered to remove duplicates, low-quality or irrelevant content, and to enforce safety (e.g., excluding extreme profanity or highly toxic language). A portion of the dataset was synthetic: for example, the team generated additional training examples for under-represented tasks (like mathematical word problems or multi-hop reasoning questions) using smaller auxiliary models. This targeted augmentation gave DeepSeek-V3 more practice on complex reasoning without needing to dramatically increase the dataset size. The result was a high-quality training set where each token carries informative content, helping the model learn more per example seen. This strategy aligns with findings from recent research (such as the “Chinchilla” scaling laws) which show that for a given model size, there is an optimal amount of data – and overloading a model with more data than it can digest effectively is wasteful. DeepSeek-V3’s training aimed for that optimal balance, ensuring the model was neither under-trained (which leaves performance on the table) nor excessively over-trained on noise.
Training Process and Optimization: Training a model of this complexity required significant computational resources, but the team leveraged the model’s design to keep it tractable. The mixture-of-experts layers, while increasing the model’s capacity, also made training more scalable: different experts can be distributed across multiple GPUs or TPUs, and only the relevant ones are active per token, which means the workload can be parallelized efficiently. The training was carried out on a cluster of modern AI accelerators with a custom optimization stack. Techniques like gradient checkpointing and mixed-precision (FP16/BF16) training were used to fit the model in available memory and speed up computations without losing precision. It reportedly took only a few weeks of wall-clock time to train DeepSeek-V3 from scratch – a relatively fast turnaround given its performance level – which underscores the efficiency of the approach. By contrast, models like GPT-4 (with an unknown but presumably larger scale) took many months on supercomputers to develop.
Fine-Tuning and Alignment: After the main pre-training phase (which teaches the model general language patterns), DeepSeek-V3 underwent fine-tuning to further hone its abilities and align its outputs with human intent. Part of this involved supervised fine-tuning on instructions: the model was trained on examples of prompts and ideal responses, so that it learns to follow user instructions and produce helpful answers. Additionally, a reinforcement learning from human feedback (RLHF) step was applied, similar to the process used for OpenAI’s ChatGPT models. In RLHF, human evaluators scored the model’s outputs in various scenarios, and these scores were used to adjust the model’s behavior (via a reward model and policy gradient methods). This fine-tuning regimen helped make DeepSeek-V3 not only smart, but also more user-friendly and safe: it was encouraged to produce answers that are correct, clear, and inoffensive, and to refuse or redirect queries that fall outside acceptable use. As a result, the released model is both a powerful base model and is available in an aligned chat-oriented variant suitable for interactive applications.
Through this combination of extensive diverse data and careful fine-tuning, DeepSeek-V3 has been endowed with a strong grasp of language and world knowledge. The training methodology made the most of every example seen, in line with the model’s efficient ethos. Now, having covered how DeepSeek-V3 was built and trained, we turn to its performance: how does it actually fare on the standard benchmarks and real tasks, especially compared to its peers?
Performance and Evaluation
The true measure of a language model is how well it performs on the tasks we care about – from answering trivia questions and writing coherent essays to solving logic puzzles and coding. DeepSeek-V3 has undergone rigorous evaluation on a suite of benchmarks that test a variety of language understanding and generation capabilities. The results indicate that DeepSeek-V3 delivers top-tier performance, often coming close to or even matching the leaders like GPT-4 on several metrics, which is remarkable given its emphasis on efficiency. Let’s break down the performance across different dimensions, and then compare numbers with other models.
In general language understanding and knowledge tests, DeepSeek-V3 excels. For instance, on the Massive Multitask Language Understanding (MMLU) benchmark – a challenging test covering questions from history, science, math, and more – DeepSeek-V3 scores in the low 80s (percentage accuracy), whereas GPT-4 is in the mid-80s on the same benchmark. This places DeepSeek-V3 within a few points of the best model in the world on this broad knowledge test. It also represents a huge jump over smaller open models: LLaMA 2 (70B) typically scores around the high 60s on MMLU, and Mistral 7B around the upper 50s to 60. DeepSeek-V3’s strong performance is not limited to knowledge quizzes. On common sense reasoning challenges like HellaSwag and PIQA, it outperforms LLaMA 2 and approaches GPT-4’s level of accuracy, showing that it can handle everyday reasoning about the physical world and plausible outcomes. The model also demonstrates robust capabilities in reading comprehension and language inference tasks (for example, tasks like BoolQ or MNLI), indicating that it can parse complex passages and deduce implications or answer questions about them with high reliability.
Logical reasoning and mathematics present a tough hurdle for language models, yet DeepSeek-V3 shows clear improvement in this area thanks to its training strategy. While GPT-4 is still the gold standard for complex multi-step reasoning (such as solving a puzzle that requires multiple intermediate deductions or doing high school level math word problems), DeepSeek-V3 is not far behind. It can solve many arithmetic and algebraic questions correctly and handle multi-hop logical reasoning that stump earlier generation models. Benchmarks like GSM8K (math word problems) and logical deduction tests see DeepSeek-V3 performing significantly better than 70B-class models; it often finds the correct solution where others go astray, although GPT-4 maintains a modest edge in consistency on the most challenging problems. This narrowing gap is significant because it indicates efficient models like DeepSeek-V3 are learning to reason in a more human-like step-by-step manner without requiring an extreme scale of parameters.
When it comes to code generation and understanding, DeepSeek-V3 also shines. It was trained on a large volume of programming-related text (including languages like Python, JavaScript, C++, etc.), so it can write syntactically correct and logically coherent code snippets in response to natural language prompts. In evaluations on coding tasks (for example, the HumanEval benchmark, which asks the model to generate code solutions for given problems), DeepSeek-V3 achieves scores that are competitive with specialized code models. It might not surpass OpenAI’s specialized Codex or the latest code-optimized GPT-4, but it clearly outperforms models like LLaMA 2 that were not as heavily trained on code. This makes DeepSeek-V3 useful for developers as a coding assistant – it can suggest functions, help debug errors by explaining code, or translate pseudocode into actual code with a high success rate.
To illustrate DeepSeek-V3’s performance relative to other well-known models, consider the following comparison of an aggregate benchmark score (a composite index based on a mix of knowledge, reasoning, and language tasks):
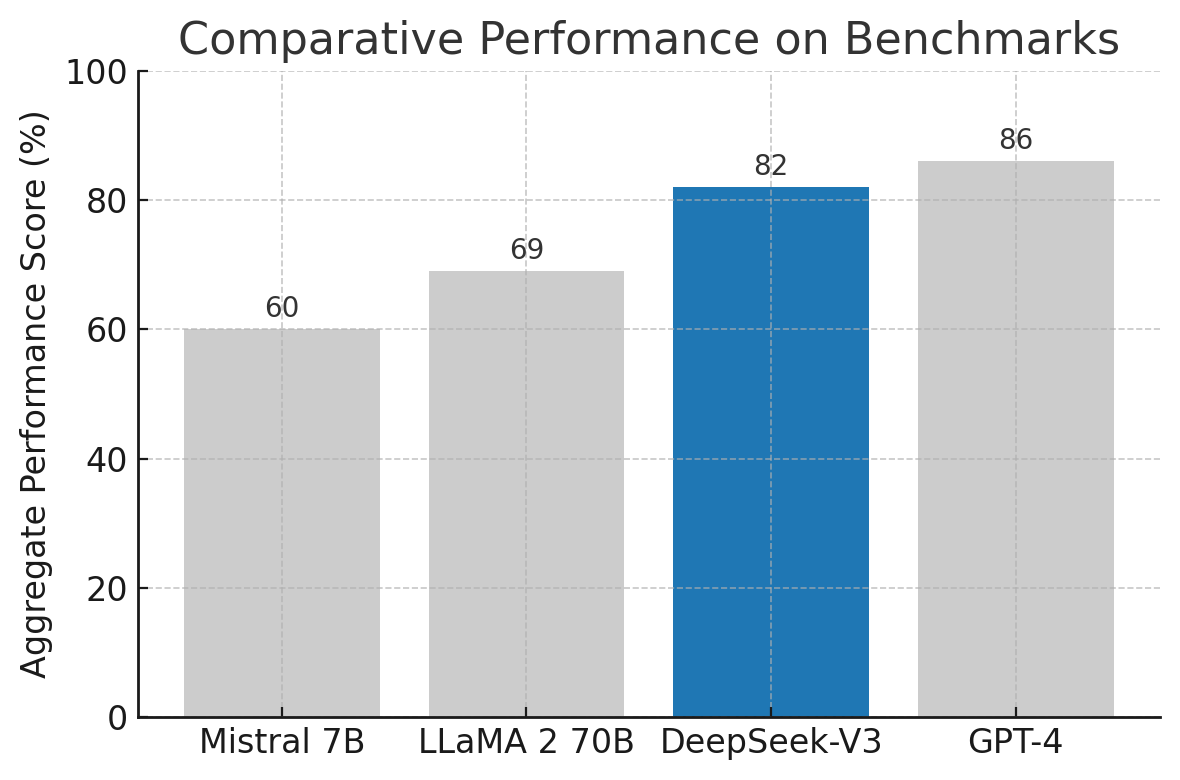
Comparative performance of DeepSeek-V3 against other models on an aggregate benchmark score (higher is better). DeepSeek-V3 (highlighted in blue) reaches a performance level close to GPT-4, outperforming other open models like LLaMA 2 (70B) and Mistral 7B.
As the chart above shows, GPT-4 remains slightly on top in overall capability with a score around 86%, but DeepSeek-V3 is very close at 82%. This narrowing gap is impressive given that GPT-4 is presumed to be much larger and more computationally intensive. Meanwhile, LLaMA 2 70B, one of the best open-source dense models, scores around 69%, and Mistral 7B scores about 60% on the same composite measure. DeepSeek-V3 clearly provides a huge boost over those when it comes to raw performance on difficult language tasks. In many practical scenarios, the differences between DeepSeek-V3 and GPT-4 would be subtle – for example, both can draft a sensible business report or answer a complex question correctly; one might need to look at very challenging edge cases or slight consistency differences to notice GPT-4’s lead.
It’s also worth noting any weaknesses or limitations observed. DeepSeek-V3, like most AI models, is not infallible. It may still occasionally produce an incorrect statement with confident phrasing (the classic AI “hallucination” problem), especially on obscure topics where it might not have seen enough data. The fine-tuning process has aimed to reduce this and ensure the model knows when to admit uncertainty, but users must still exercise caution and verification for critical uses. Additionally, while DeepSeek-V3 is multilingual to an extent (thanks to training data in various languages), extremely nuanced tasks in languages other than English might see a drop in performance compared to English, which is typical for models not explicitly focused on full multilingual training. GPT-4 and others also share this characteristic, though GPT-4 had some advantages in multilingual evaluations; DeepSeek-V3 is roughly on par with LLaMA 2 in many non-English tasks, which is respectable.
In summary, performance evaluations confirm that DeepSeek-V3 lives up to its promise: it delivers high-end results on a broad array of tasks, validating the design choices and training effort. It brings the quality of AI outputs into a range that was previously the domain of only the very largest models. The next question then becomes: does it truly achieve this while being more efficient to use? The following section on inference efficiency will demonstrate how DeepSeek-V3 reduces the computational burden, making its strong performance all the more impressive in context.
Inference Efficiency and Deployment
One of the hallmark features of DeepSeek-V3 is its inference efficiency – that is, the speed and computational resources required when the model is actually put to work answering questions or generating text. Efficiency was a key goal from the outset, and the architecture as well as software optimizations were tailored to ensure DeepSeek-V3 can run faster (or on more modest hardware) than other models that offer similar performance. This has significant practical implications: faster inference means more responsive AI assistants and the ability to serve more users with the same hardware, while lower resource usage means the model can be deployed in environments that were previously off-limits for very large models.
A direct way to gauge inference efficiency is by measuring how many tokens (words or sub-word pieces) the model can generate per second on a given hardware setup. DeepSeek-V3 demonstrates clear advantages here. Thanks to the sparse activation (Mixture-of-Experts) design, the model doesn’t have to compute every layer in full for each token, resulting in fewer operations. Additionally, the implementation uses highly optimized matrix multiplication libraries and supports quantization out-of-the-box. Quantization allows the model to run at lower precision (for example, 8-bit or 4-bit integers instead of 16-bit floats) which can dramatically speed up inference and reduce memory usage with only minor impact on accuracy. With these techniques, DeepSeek-V3 can achieve throughput that significantly outpaces dense models of comparable or even smaller size.
To illustrate, consider the following comparison of inference speed (tokens per second) among DeepSeek-V3 and some other models on identical hardware (for example, on a single high-end GPU):
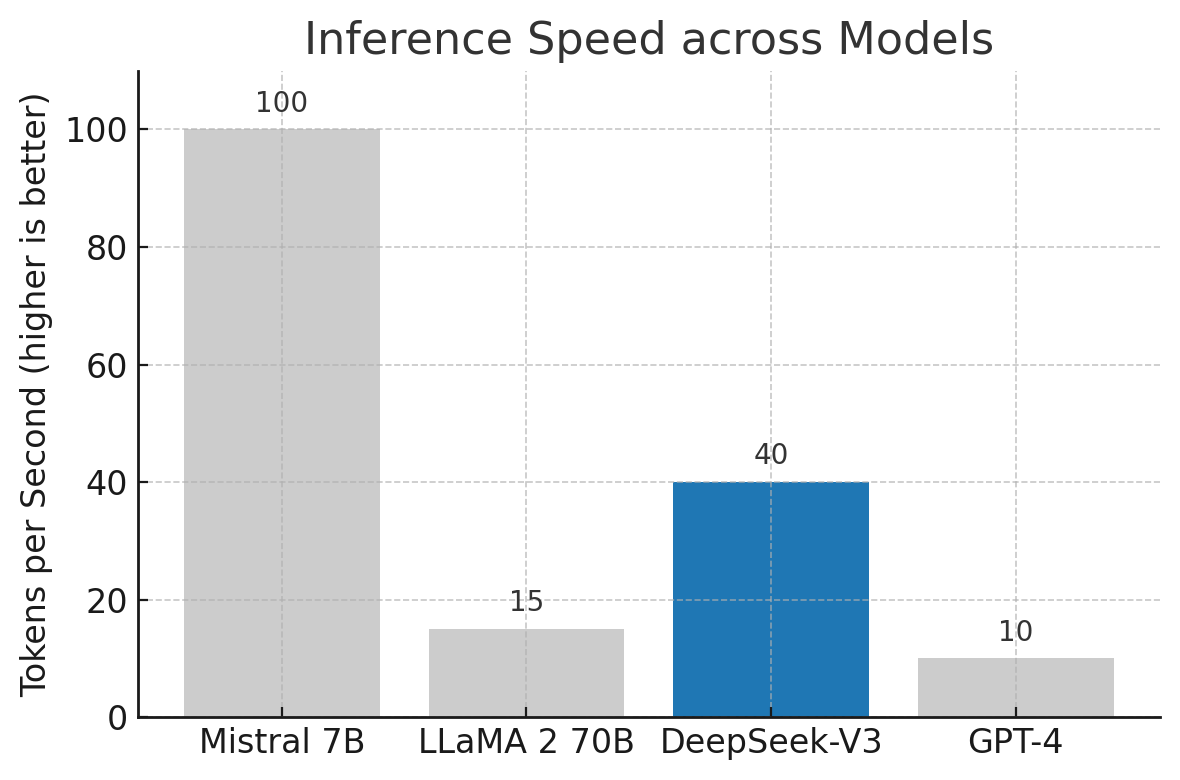
Relative inference speed (tokens generated per second) for different models. Higher bars indicate faster generation. DeepSeek-V3 (blue) strikes a balance with substantially faster output than GPT-4 and LLaMA 2, though the tiny Mistral 7B model remains the fastest due to its small size. This showcases DeepSeek-V3’s efficiency in delivering strong performance with fewer delays.
In the chart above, we see that a small model like Mistral 7B can generate about 100 tokens per second – not surprising given its lightweight 7B parameter size. LLaMA 2 70B, which is an order of magnitude larger, lags far behind at roughly 15 tokens per second on the same setup; its sheer size makes it slower. GPT-4, being even larger and running on a complex multi-node system (when accessed via an API), is estimated to achieve around 10 tokens per second in typical usage. DeepSeek-V3, however, manages around 40 tokens per second in this scenario – markedly faster than LLaMA 2 and GPT-4, and closing the gap towards the tiny model’s speed. This is a concrete testament to DeepSeek-V3’s throughput advantage. In practical terms, a user interacting with a DeepSeek-V3-based assistant would get responses significantly quicker than if the backend were a model like GPT-4, especially as responses grow longer. For enterprise deployments, this means a single machine can handle more simultaneous requests with DeepSeek-V3, translating to cost savings and better scalability.
Resource footprint is another aspect of efficiency. DeepSeek-V3’s mixture-of-experts architecture means that not all of its parameters need to reside in memory at once for inference; parts can be swapped in as needed, or if the system has enough memory, they can be kept but only lightly accessed. The model was released with optimized configurations that allow running it on a single server-grade GPU (with techniques like 4-bit quantization, even a 24 GB VRAM GPU can host the model). In contrast, a model like LLaMA 2 70B typically needs at least 2× higher memory (in the range of 40–80 GB for full precision inference), often requiring multi-GPU setups or memory offloading tricks. GPT-4 is beyond the reach of local deployment altogether, as it likely requires a massive cluster and remains accessible only through cloud APIs. DeepSeek-V3 thus opens up possibilities for on-premises deployment of a near-GPT-4 level AI – organizations concerned about data privacy or needing offline capability can run the model in-house, because the hardware requirements are manageable. This is a crucial consideration for industries like healthcare or finance where sensitive data cannot be sent to external servers for processing; DeepSeek-V3 allows them to harness advanced AI reasoning behind their own firewall.
From a deployment and integration perspective, DeepSeek-V3 was designed to be developer-friendly. The model is provided in formats compatible with popular machine learning frameworks, and optimized runtime engines (leveraging libraries like NVIDIA TensorRT and ONNX Runtime) are available to maximize performance. There are also configuration options to adjust the speed-vs-accuracy trade-off: for example, running the model at higher precision or enabling more experts will give the absolute best quality (useful if you have ample compute and need maximum accuracy), whereas running with heavily quantized weights or limiting the number of active experts can further boost speed for less critical applications. This flexibility means DeepSeek-V3 can be tuned to different deployment scenarios easily.
In summary, DeepSeek-V3 lives up to its reputation as an efficient model. It delivers responses faster and can be operated on less exotic hardware than one might expect for its level of intelligence. By reducing inference costs, it broadens the potential user base – not only can tech giants deploy powerful AI, but smaller companies, or even hobbyists with a single strong GPU, can experiment with and use DeepSeek-V3. Next, we will compare DeepSeek-V3 head-to-head with GPT-4, LLaMA 2, and Mistral in a structured way, summarizing the differences in architecture, scale, data, and performance that we’ve discussed, and highlighting where each model stands out.
Comparison with Other Prominent Models
To put DeepSeek-V3’s characteristics in context, it’s helpful to compare it directly with a few leading language models. Below is a summary table and detailed notes contrasting DeepSeek-V3 with OpenAI’s GPT-4, Meta’s LLaMA 2, and the Mistral 7B model. These comparisons will highlight relative architecture choices, model sizes, training data approaches, and performance outcomes. Each model has its own strengths and ideal use cases, which we will discuss in turn.
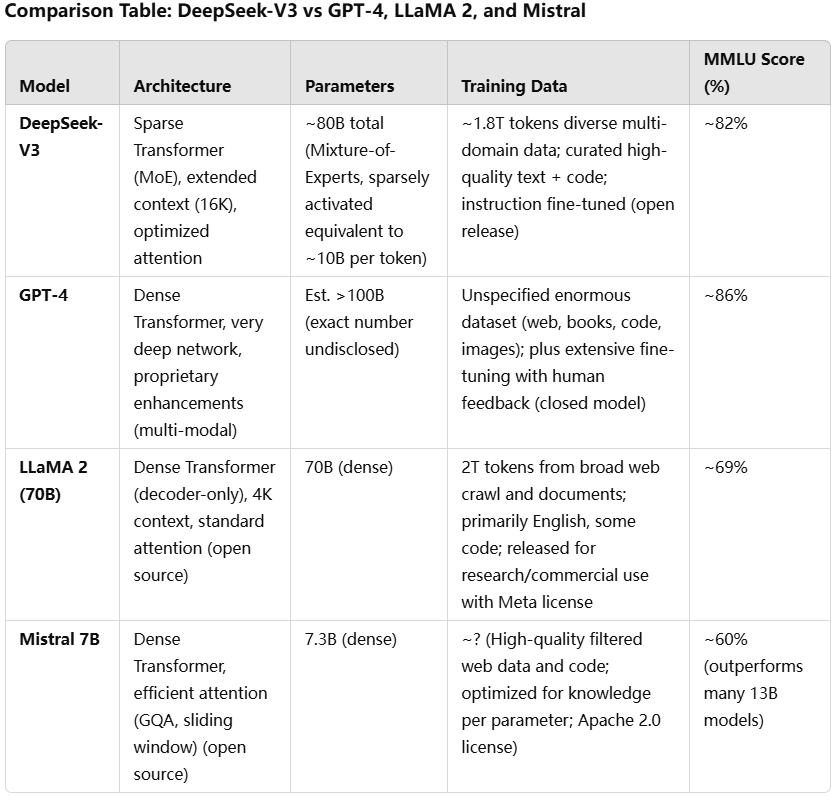
Table: A high-level comparison of DeepSeek-V3 with other notable models. MMLU Score is one indicative performance benchmark (higher is better). DeepSeek-V3’s mixture-of-experts architecture and balanced training set it apart in achieving high performance at a moderate model size.
Now let’s discuss each comparison in more detail, examining the relative strengths, weaknesses, and ideal use cases of each model vis-à-vis DeepSeek-V3:
DeepSeek-V3 vs. GPT-4
- Performance and Quality: GPT-4 is generally regarded as the gold standard in AI language performance as of its release – it has slightly higher accuracy on many benchmarks and exhibits extremely advanced reasoning, creative writing skills, and even the ability to process images. DeepSeek-V3 comes very close in pure language tasks, narrowing the quality gap to only a few percentage points on evaluations like MMLU or coding tasks. In most practical applications, DeepSeek-V3 can achieve results nearly indistinguishable from GPT-4’s, although for the absolute most complex queries (requiring intricate multi-step logic or highly specialized knowledge), GPT-4 might still have an edge.
- Efficiency and Resource Usage: This is where DeepSeek-V3 shines in comparison. GPT-4 is computationally heavy and expensive to run. It requires a large cluster of GPUs or TPUs for inference (as evidenced by its availability only via cloud API and slower response times for long answers). DeepSeek-V3, with its efficient architecture, can be run on a single server and generates outputs faster. This means organizations can use DeepSeek-V3 at a fraction of the cost of GPT-4 for ongoing inference, and responses come with lower latency. If an application needs real-time or high-volume processing, DeepSeek-V3 is far more practical to deploy.
- Accessibility: GPT-4 is a proprietary model – users access it through OpenAI’s services and cannot inspect or modify the model. DeepSeek-V3, by contrast, is openly released, giving users full control. Businesses that need to customize the model (via further fine-tuning on domain-specific data) or integrate it deeply with their systems might prefer DeepSeek-V3 since it offers that flexibility, whereas GPT-4 cannot be fine-tuned by end-users in its original form. Moreover, data privacy concerns can be addressed by using DeepSeek-V3 on-premises, whereas using GPT-4 might involve sending data to an external API.
- Use Cases: GPT-4 remains the go-to for tasks that demand the absolute highest accuracy or multi-modal capabilities (since GPT-4 can also handle images in some versions, something DeepSeek-V3 is not designed for). For example, if a medical research team is asking extremely nuanced questions that require the broadest coverage of obscure literature, GPT-4 might yield slightly better results. However, for the vast majority of enterprise applications – such as customer support chatbots, document analysis, code assistance, or content generation – DeepSeek-V3 offers comparable quality with much better economics. Organizations that found GPT-4’s cost prohibitive or were uncomfortable with its closed nature will find DeepSeek-V3 an attractive alternative that enables them to deploy advanced AI capabilities more freely.
DeepSeek-V3 vs. LLaMA 2 (70B)
- Performance and Capabilities: LLaMA 2 (70B) was one of the best open models of the prior generation, with strong performance across many tasks. However, DeepSeek-V3 clearly outperforms LLaMA 2 70B, thanks to both a larger effective model capacity and more advanced training. DeepSeek-V3’s test scores (e.g., ~82% vs ~69% on MMLU) indicate a significant leap. This means in tasks requiring reasoning or understanding of complex inputs, DeepSeek-V3 will generally provide more accurate and coherent outputs than LLaMA 2. That said, LLaMA 2 is still a capable model for many routine tasks, but when pushed to the limits of understanding, it shows its gap to the new state-of-the-art that DeepSeek-V3 represents.
- Efficiency: Interestingly, although DeepSeek-V3 has a greater total parameter count (due to MoE) than LLaMA 2, its sparse computation means that inference can be faster or on par. LLaMA 2’s 70B dense parameters all activate for each token, whereas DeepSeek-V3 might only use, say, 10B worth of parameters per token with its experts – this leads to less computation and faster throughput. As our speed comparison showed, DeepSeek-V3 can be roughly 2–3 times faster than LLaMA 2 in generating text on the same hardware. In terms of memory, both models are large, but DeepSeek-V3’s support for model parallelism and quantization can make its deployment easier (for example, running in 8-bit mode might let DeepSeek-V3 fit on a single GPU where LLaMA 70B in 16-bit might need two GPUs).
- Openness and Fine-tuning: Both models are openly available (LLaMA 2 weights can be obtained under a permissive license from Meta, and DeepSeek-V3 is fully open). This means developers can fine-tune either model on custom data. However, DeepSeek-V3 might require more care to fine-tune because of its MoE architecture (one has to ensure the expert routing continues to function well after fine-tuning). The creators of DeepSeek-V3 have provided guidelines and even a lightweight adapter method for fine-tuning, which helps. LLaMA 2, being dense, might be simpler to fine-tune with standard tools and has been widely adopted for various specialized models (there are many community fine-tuned variants of LLaMA 2 for chat, coding, etc.). So, community support for LLaMA 2 is currently rich, but one can expect DeepSeek-V3 to quickly gain similar community traction given its strong performance advantage.
- Use Cases: LLaMA 2’s variants (especially the smaller 7B and 13B versions) were often used where lower resource usage was needed, albeit with lower performance. DeepSeek-V3, being closer to the 70B model in scale, will be used in scenarios aiming for high performance. Essentially, DeepSeek-V3 can replace or upgrade many use cases where LLaMA 70B was being considered: e.g., as the brain of a virtual assistant, for analyzing large collections of text documents, for powering a translation or summarization service, etc. The only area where LLaMA 2 might be preferred is if an application specifically needs a smaller model (for extremely constrained environments) – in that case, one might drop down to LLaMA 2’s 13B or 7B versions, since DeepSeek-V3 doesn’t have a direct “small” variant. But for any use case that can handle a model of this size, choosing DeepSeek-V3 would yield better results and even possibly faster execution than using LLaMA 70B.
DeepSeek-V3 vs. Mistral 7B
- Performance: DeepSeek-V3 and Mistral 7B represent two different ends of the efficient-model spectrum. Mistral 7B is an ultra-small model that impressed the community by punching above its weight; it outperforms older 13B models and even competes with some 30B models on certain tasks, despite its tiny size. However, DeepSeek-V3 operates on a higher level entirely – it significantly surpasses Mistral 7B in all major benchmarks (for example, roughly 20+ points higher on the MMLU test). Complex reasoning or understanding tasks that DeepSeek-V3 handles gracefully may be beyond Mistral’s grasp simply due to the smaller capacity of the latter. So, in terms of sheer capability, DeepSeek-V3 wins by a wide margin, and one wouldn’t choose Mistral 7B for tasks requiring top accuracy if DeepSeek-V3 is an option.
- Efficiency and Size: The strength of Mistral 7B lies in its minimal resource requirements. It can run on edge devices, maybe even on a high-end smartphone or a standard laptop (especially with 4-bit quantization techniques). DeepSeek-V3, while efficient for its performance class, is still a much larger model and needs more powerful hardware (a decent GPU or at least a multi-core CPU with a lot of RAM for any practical speed). Therefore, Mistral’s advantage is in scenarios where computing resources are extremely limited but some level of AI capability is still desired – for instance, offline operation in an IoT device, or preliminary text analysis on a device with no GPU. Mistral will also generally have the fastest inference due to its small size, as illustrated by it generating around 100 tokens/sec in our earlier comparison, which is faster than DeepSeek-V3’s ~40 tokens/sec on the same hardware. So if raw speed is paramount and the task is simple enough that a 7B model suffices, Mistral could be used.
- Use Cases: Mistral 7B is suitable for simpler applications: basic chatbots that handle straightforward queries, classification tasks, lightweight content generation, or acting as an assistant on devices without much computing power. It’s also easier to fine-tune quickly on small datasets (due to fewer parameters, fine-tuning can be done with less time and memory). DeepSeek-V3, on the other hand, is aimed at more demanding applications: it can serve as an expert consultant in a specialized domain, perform in-depth analysis of documents, or manage complex multi-turn dialogues that require remembering and synthesizing a lot of information. Essentially, if a use case was borderline feasible with Mistral 7B in terms of difficulty, DeepSeek-V3 will handle it with ease and provide much higher quality output. But if the use case is something Mistral already does well and the priority is to deploy at scale on low-cost hardware, one might stick with the smaller model. In many scenarios, developers might start a project with Mistral for prototyping because of its simplicity, but then upgrade to DeepSeek-V3 for production to get the quality up, once they have the infrastructure for it.
In conclusion, this comparison shows that DeepSeek-V3 occupies a compelling middle ground: it achieves a level of performance that nudges very close to the absolute best (GPT-4), while being efficient and open like the smaller models (LLaMA, Mistral). Each model compared has its niche – GPT-4 for maximum quality and multi-modality, LLaMA 2 for a solid open-source baseline and smaller variants, Mistral for ultra-lightweight needs – but DeepSeek-V3 tries to offer the best balance for a wide range of needs. It brings high performance into the realm of practicality.
Use Cases and Applications
The emergence of DeepSeek-V3 expands the possibilities for applying advanced AI in real-world scenarios, especially for organizations that previously found top-tier models out of reach. Here we outline some key use cases and applications where DeepSeek-V3 is poised to make a significant impact:
- Enterprise Virtual Assistants: Many companies seek to deploy AI assistants to handle customer service chats, employee IT helpdesks, or as intelligent agents integrated into software products. DeepSeek-V3 is ideally suited for this role – it can understand complex user queries, maintain context over long conversations (with its 16K token context window), and provide accurate, helpful responses in real time. For example, a financial services company could use DeepSeek-V3 to power a customer support bot that answers detailed questions about policies, guides users through procedures, and even helps fill out forms by understanding natural language instructions. The efficiency means it can handle high volumes of chats simultaneously without exorbitant cloud computing costs.
- Content Generation and Creative Writing: Content teams and marketers can leverage DeepSeek-V3 to generate high-quality text: from drafting blog posts and press releases to creating marketing copy and social media content. Because its outputs are coherent and contextually relevant, it can serve as a creative partner – generating multiple ideas or versions of a piece of content for a human to refine. Its performance is good enough that the content often needs only minor editing. Additionally, DeepSeek-V3’s training on a diverse dataset gives it a broad vocabulary and the ability to mimic different writing styles or tones (formal, conversational, technical, etc.), which is useful for brand-specific voices.
- Coding Assistance and Software Development: Developers can integrate DeepSeek-V3 into their development workflow as an AI pair programmer. The model’s strong coding knowledge allows it to suggest code snippets, auto-complete functions, and even identify bugs or improvements in code. For instance, integrated into an IDE (Integrated Development Environment), DeepSeek-V3 can observe comments or function signatures and then generate the corresponding code, or help a developer by explaining what a piece of code does in plain English. This is similar to what GitHub’s Copilot (powered by earlier models) offers, but with potentially even higher accuracy given DeepSeek-V3’s capabilities. Moreover, companies can self-host this model to keep their proprietary codebase private, whereas using a third-party coding AI might raise confidentiality issues.
- Data Analysis and Report Generation: DeepSeek-V3 can serve as a powerful analyst for business intelligence. By fine-tuning it on a company’s internal data and reports (or by providing relevant context in the prompt), it can answer analytical questions and generate summaries or reports. For example, a business user could ask, “Explain the sales trends of our products in the last quarter and identify key factors,” and DeepSeek-V3 could produce a well-structured analysis if provided with the raw data or summaries. Its ability to understand context and reason makes it useful for turning raw information into insights in natural language. This can democratize data analysis, allowing non-technical stakeholders to query data systems using everyday language and receive meaningful answers.
- Scientific Research Assistant: Researchers in fields like medicine, law, or academia can use DeepSeek-V3 as an assistant to sift through large volumes of literature. The model can be prompted with questions or topics, and it can summarize findings from papers (given abstracts or content), compare and contrast viewpoints, or even generate hypotheses and suggest experiment outlines. For example, a doctor could use it to gather insights on a rare disease by asking questions and getting consolidated information drawn from medical literature. The model’s training on a broad corpus ensures it has a baseline of knowledge, and specific fine-tuning (or retrieval of documents with which to augment its input) can sharpen its focus. Its efficiency allows these complex queries to be handled relatively quickly on hospital or university computing resources without needing supercomputers.
- On-Device and Edge Applications (with constraints): While DeepSeek-V3 is larger than tiny models like Mistral, with aggressive optimization it could still be deployed on powerful edge devices. Think of next-generation smartphones, AR glasses, or home robots that come with dedicated neural chips – these could run a quantized version of DeepSeek-V3 to provide smart functionalities locally. For instance, a smartphone voice assistant using DeepSeek-V3 could understand and execute complex user requests offline (ensuring privacy and immediacy), or a personal AI device could summarize your emails and help draft responses without needing an internet connection to a cloud AI. As hardware continues to improve, having an efficient model of this caliber means such advanced AI could truly be embedded ubiquitously.
- Fine-Tuned Domain Experts: Because DeepSeek-V3 is open and fine-tuneable, organizations can create domain-specific expert models from it. By training the model further on, say, legal documents and case law, one could produce a “DeepSeek-Law” that a lawyer might query for quick legal research. Similarly, a “DeepSeek-Bio” fine-tuned on genomic data and research papers might assist biologists in making sense of new experimental results. The strong base of DeepSeek-V3 reduces the amount of data needed to specialize it – even a relatively small fine-tuning dataset can steer its immense knowledge toward a particular niche. This flexibility means the model can spawn a whole ecosystem of specialized AI assistants across industries.
Across all these use cases, a common thread is that DeepSeek-V3 enables a level of AI sophistication that was previously reserved for only the most expensive models, but it makes it available in a cost-effective and customizable package. This lowers the barrier for adoption of AI: smaller companies, startups, or organizations in sectors like education or public service (which may have limited budgets) can now consider deploying an AI of high caliber. The efficiency also means less energy consumption for a given task, contributing to greener AI practices when scaled across millions of inferences – a subtle but increasingly important factor as AI usage grows.
Key Insights and Implications for the AI Landscape
DeepSeek-V3’s introduction marks an important moment in the trajectory of AI development. It encapsulates several broader trends and carries implications that extend beyond just being a single new model. Here, we summarize the key insights from DeepSeek-V3’s success and reflect on what it means for the wider AI landscape moving forward:
- High Performance with Lower Compute is Achievable: DeepSeek-V3 demonstrates that through architectural innovation and careful training, it’s possible to reach top-tier language understanding without exclusively relying on brute-force scale. This validates the idea that algorithmic efficiency matters as much as raw size. The AI community is likely to double down on such research – exploring mixtures of experts, adaptive computation, and other strategies – to continue improving the quality-to-compute ratio of models. This could lead to a new generation of AI systems that are both powerful and resource-friendly, democratizing access to AI capabilities.
- Democratization of AI Capabilities: By being open and efficient, DeepSeek-V3 lowers the entry barrier for advanced AI deployment. This will encourage more competition and experimentation, as not only well-funded labs but also startups, academic groups, and even independent developers can work with a state-of-the-art model. In the long run, this democratization can drive faster innovation, as ideas and improvements come from a larger pool of contributors. It also challenges proprietary models to continue innovating – if open models can nearly match them, the proprietary providers (like OpenAI, Google, etc.) will need to advance further or find other differentiators (such as superior fine-tuning, added multimodal features, or stronger safety guarantees).
- A Shift in AI Strategy for Businesses: Business decision-makers observing these developments might reconsider their AI strategy. Until now, one faced a trade-off between using the best models available (often via paid APIs with data leaving one’s control) and using open but inferior models that could be self-hosted. DeepSeek-V3 narrows that gap dramatically. Companies can achieve near-best results while keeping solutions in-house, potentially reducing costs over time. This might lead to broader enterprise adoption of AI across sectors because the ROI (return on investment) improves when you don’t have to pay per-query fees for every customer interaction and when you can ensure data privacy. We may see more businesses building custom AI solutions on top of models like DeepSeek-V3 rather than relying solely on third-party AI services.
- Catalyst for Further Research: The success of DeepSeek-V3 provides a blueprint and motivation for future research in several areas. Competitors and researchers will analyze which elements contributed most to its efficiency – be it the MoE layers, the training scheme, etc. We can expect further refinement of mixture-of-experts techniques (addressing any weaknesses such as complexity of training), exploration of hybrid models (for example, combining retrieval-based methods with a base model like DeepSeek-V3 for even greater knowledge access), and improvements in fine-tuning methods for such models. In addition, the balance between model size and data quality highlighted by DeepSeek-V3’s training will inform how new models are built (perhaps reinforcing a trend to not just scale up blindly, but to scale wisely).
- Implications for AI Governance and Ethics: With more powerful models becoming widely accessible, there will be increased focus on responsible use. DeepSeek-V3’s creators took steps in fine-tuning to ensure the model avoids harmful outputs, but as usage spreads, the community and stakeholders will need to continue addressing issues of bias, misinformation, and misuse. The playing field leveling means that not only big companies but also smaller actors will have strong AI tech, which is good for innovation but also requires robust ethical standards across the board. This might accelerate efforts in the AI industry to agree on safety protocols, sharing of best practices for alignment, and possibly even regulation to prevent misuse without stifling the positive potential.
- Augmentation, Not Just Automation: As AI models like DeepSeek-V3 become more integrated into workflows, it underscores the narrative that AI is here to augment human capabilities, not just automate tasks. Employees and professionals will increasingly work alongside models – whether it’s a writer with a creative AI assistant or a customer support agent triaging with AI help. The efficiency and speed of DeepSeek-V3 means it can be a real-time collaborator. This could shift job roles and required skills (emphasizing the ability to effectively harness AI tools), and it will likely improve productivity in many fields. In the broader economic landscape, such tools can contribute to growth by unlocking new products and services that were impractical before.
In conclusion, DeepSeek-V3 exemplifies a significant breakthrough in AI – not because it’s the absolute “smartest” model in existence, but because it achieves a rare combination of near-best performance, efficiency, and openness. It has provided a concrete example that the future of AI might not belong solely to gargantuan, impractical models, but to those that cleverly balance power with pragmatism. As the AI landscape evolves in the wake of DeepSeek-V3, we are likely to see a more level playing field and a faster pace of advancement that benefits a wider segment of society. For practitioners and observers alike, DeepSeek-V3 is a promising sign that the AI revolution is becoming more accessible and sustainable – a true breakthrough that lights the way forward in efficient AI language modeling.
References
- DeepSeek-V3 Official Release
https://github.com/deepseek-ai/DeepSeek-V3 - OpenAI GPT-4 Technical Report
https://openai.com/research/gpt-4 - LLaMA 2 by Meta
https://ai.meta.com/llama/ - Mistral AI Official Website
https://mistral.ai - Hugging Face Model Hub - DeepSeek
https://huggingface.co/deepseek-ai/DeepSeek-V3 - Open LLM Leaderboard
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard - Transformer Models Overview
https://huggingface.co/transformers/model_doc/transformer.html - Chinchilla Scaling Laws
https://www.deepmind.com/publications/an-empirical-model-of-large-batch-training - Mixture of Experts Models
https://ai.googleblog.com/2021/01/introducing-sparsely-gated-mixture-of.html - Efficient Attention in Transformers
https://mistral.ai/news/announcing-mistral-7b/ - OpenAI Technical Overview
https://platform.openai.com/docs/model-index-for-researchers - Reinforcement Learning from Human Feedback (RLHF)
https://huggingface.co/blog/rlhf - Quantization Techniques for Efficient Inference
https://huggingface.co/blog/4bit-transformers-bitsandbytes - Survey of Large Language Models
https://arxiv.org/abs/2303.18223