
DeepSeek Unveils Upgraded AI Model with Superior Reasoning and Minimal Hallucination

In the rapidly evolving landscape of artificial intelligence, reasoning ability and factual consistency have become the twin pillars of progress for large language models (LLMs). As the market becomes increasingly saturated with models from tech giants and emerging AI startups alike, the capability to reason effectively and minimize hallucinations—those confidently stated but false outputs—has become a critical differentiator. It is against this backdrop that DeepSeek, a prominent player in the LLM domain, has announced the release of its upgraded model, which the company claims exhibits significantly improved reasoning capabilities and a reduced rate of hallucination. This development represents not just a technical milestone for DeepSeek, but also an industry-wide shift toward more trustworthy and reliable AI systems.
The term “hallucination” in AI parlance refers to a model’s generation of content that appears coherent and plausible but is factually incorrect or logically inconsistent. While hallucinations can range from benign inaccuracies to dangerously misleading outputs, their existence has posed serious challenges for the deployment of AI systems in real-world applications, particularly in sensitive industries like healthcare, legal services, and finance. Despite substantial investments in model training and fine-tuning, hallucination remains one of the most persistent problems in generative AI. Thus, any breakthrough that demonstrably mitigates this issue garners significant attention across the AI research community and commercial sectors.
DeepSeek’s announcement is timely. Over the past year, there has been an explosion of interest in reasoning-optimized models, with OpenAI’s GPT-4, Anthropic’s Claude series, and Google’s Gemini family all making strides in this area. DeepSeek, while not as widely known as these titans, has built a reputation for technical precision and innovation, particularly in multilingual understanding and instruction tuning. With this new release, DeepSeek aims to leapfrog its competition by offering a model that not only performs well on established benchmarks like MMLU (Massive Multitask Language Understanding) and GSM8K (grade school math problems), but also significantly reduces hallucination rates as measured by real-world evaluations and adversarial testing.
At the heart of DeepSeek’s strategy is the belief that improving reasoning and reducing hallucinations are not mutually exclusive goals but rather interdependent objectives. In fact, many of the model’s architectural and training innovations—such as improved attention mechanisms, larger context windows, better instruction tuning, and enhanced reinforcement learning from human feedback (RLHF)—are designed to enhance both capabilities simultaneously. This dual improvement sets DeepSeek’s model apart in a field where many LLMs achieve high reasoning accuracy at the expense of factual reliability, or vice versa.
One particularly noteworthy aspect of DeepSeek’s upgraded model is its apparent proficiency in contextual reasoning across long passages, a feature that has become increasingly relevant in real-world applications. In document-heavy domains like law and medicine, the ability to maintain logical coherence over multiple paragraphs or even pages is indispensable. Early demonstrations from DeepSeek indicate that the model can process, understand, and respond to lengthy inputs with a degree of nuance and consistency previously reserved for state-of-the-art commercial models. Furthermore, the model exhibits enhanced performance in cross-lingual tasks, making it a strong candidate for global deployments where multilingual reasoning is essential.
Another compelling dimension of DeepSeek’s latest offering is its alignment with ethical AI goals. Hallucinations not only affect performance but also raise critical ethical and regulatory concerns, especially when models are deployed at scale. DeepSeek’s new model, by reducing hallucinations, contributes to the development of safer AI systems—ones that can be more readily integrated into sensitive workflows without the constant need for human oversight or post-hoc verification. This step toward AI trustworthiness could have cascading effects on public perception, enterprise adoption, and policymaking in the generative AI space.
In this blog post, we will delve deeper into the technological advancements that underpin DeepSeek’s new model, evaluate its performance across multiple reasoning and hallucination benchmarks, and explore its potential impact on both developers and enterprise users. We will also situate DeepSeek within the broader competitive landscape, analyzing how its innovations compare with offerings from leading players like OpenAI, Google DeepMind, Anthropic, and Meta.
To provide a comprehensive and data-driven analysis, the blog will include two charts: one comparing the architectural upgrades and another visualizing industry-specific performance applications. Additionally, we will include a comparative table of benchmark results to objectively assess hallucination rates and reasoning capabilities across the most prominent models in the field.
As AI continues to advance, it is imperative for both developers and end-users to understand not just what these models can do, but how reliably they can do it. The promise of powerful generative AI lies not merely in generating content, but in doing so with precision, consistency, and trustworthiness. DeepSeek’s upgraded model, if its claims are substantiated by empirical results, could mark a significant milestone in that journey. With this context established, we now turn our attention to the architectural underpinnings of DeepSeek’s model and the innovations that make its performance gains possible.
Architecture and Technical Innovations Behind the Upgrade
The success of any large language model (LLM) hinges on the sophistication of its underlying architecture and the ingenuity of its training methods. DeepSeek's latest upgraded model stands as a testament to the strategic integration of advanced neural engineering, data curation, and algorithmic refinement. This section dissects the core architectural features and technical innovations that have enabled DeepSeek to claim substantial improvements in reasoning accuracy and hallucination mitigation—two of the most pressing frontiers in LLM performance.
At the architectural level, DeepSeek’s upgraded model introduces a refined transformer backbone with a significantly expanded context window. Traditional transformer models have been limited by quadratic scaling in attention mechanisms, which restricts the model’s ability to efficiently process long sequences. DeepSeek addresses this limitation through an optimized attention schema, likely a variant of sparse attention or long-range attention techniques such as FlashAttention or Multi-Query Attention (MQA). This enhancement allows the model to parse inputs of over 128,000 tokens with high fidelity—comparable to or exceeding the capabilities of leading models such as Claude 3 and Gemini 1.5. The benefit of a larger context window extends directly to multi-hop reasoning, as it enables the model to retain and synthesize more context, reducing the likelihood of logically disconnected or factually incorrect outputs.
Furthermore, the model architecture reportedly supports mixture-of-experts (MoE) functionality, selectively activating subnetworks during inference to enhance efficiency and specialization. MoE architectures provide two major benefits: computational scalability and modular learning. By allocating specific parameter subsets to particular types of tasks or data, the model can reason with greater precision in specialized domains, such as legal or biomedical content, without bloating computational cost across all queries. This approach aligns with industry trends championed by models like Google’s Switch Transformer and Meta’s recent open-source MoE releases.
Complementing architectural revisions are DeepSeek’s enhancements in pretraining and fine-tuning regimes. The model has been trained on an extensively curated dataset comprising diverse linguistic, technical, and domain-specific sources. While DeepSeek has not fully disclosed the data composition, there are indications that the training corpus includes high-quality academic datasets, programming repositories, peer-reviewed publications, and multilingual corpora. This diversified training base is crucial for robust reasoning and reduces the tendency to overfit on repetitive internet text, a common source of hallucinations in earlier models.
DeepSeek has also implemented a sophisticated instruction tuning pipeline that utilizes both supervised fine-tuning and reinforcement learning from human feedback (RLHF), augmented by a novel technique akin to reinforcement learning with AI feedback (RLAIF). The use of RLAIF—wherein weaker models or synthetic agents assist in training stronger models by identifying inconsistencies—allows for scalable and consistent value alignment. By exposing the model to challenging prompts and encouraging responses that align with correctness and clarity, this multi-stage training method fine-tunes the model's judgment and decision-making processes. Importantly, this approach supports the development of self-reflective behaviors, such as the model’s ability to flag or correct uncertain or potentially incorrect responses, which is critical for hallucination control.
Another important advancement is the implementation of dynamic retrieval-augmented generation (RAG) within the model’s framework. RAG integrates external information sources—such as databases, APIs, or search indexes—into the generation process, providing real-time factual grounding. This architecture allows DeepSeek to access up-to-date information without relying solely on its static pretraining data. While RAG is not unique to DeepSeek, the company’s tight integration of retrieval systems with its core inference engine enhances both reasoning accuracy and factual consistency, particularly in open-domain question answering and real-world enterprise scenarios.
Token efficiency has also seen notable improvements in DeepSeek’s latest model. By implementing better tokenization strategies, such as byte-level or unigram-based tokenization, the model is able to compress more information into fewer tokens. This not only reduces inference costs but also enables more nuanced understanding of compound terms, idiomatic expressions, and multilingual content. Token efficiency is especially vital for industries such as customer service and legal tech, where precision in language and cost-effective computation are equally important.
In terms of safety and alignment, DeepSeek’s upgraded model benefits from extensive adversarial robustness testing and red-teaming exercises. These protocols involve exposing the model to complex, ambiguous, or malicious prompts to observe failure modes. The learnings from these exercises have been incorporated into model training to reduce the likelihood of generating harmful, misleading, or biased outputs. Moreover, the model has been fine-tuned with ethical heuristics that emphasize transparency, factuality, and non-speculative responses, making it more suitable for deployment in high-stakes environments.
The model’s internal reasoning capabilities have also been enhanced through multi-step chain-of-thought (CoT) training techniques. CoT encourages the model to verbalize its intermediate reasoning steps when solving complex problems. This approach mimics human-like deliberation and reduces the risk of jumping to conclusions without context. When combined with mechanisms such as tool-use (e.g., calculator modules or code interpreters), DeepSeek’s model can engage in layered reasoning with high reliability, improving its accuracy in tasks ranging from math problem-solving to legal document summarization.
Importantly, DeepSeek has ensured that all these advancements are accessible through its cloud-based API and on-premise deployment options, supporting flexible use across different enterprise environments. Whether integrated into software applications, virtual assistants, or workflow automation tools, the model’s architecture is designed for interoperability and low-latency responses.
| Feature | DeepSeek v1 | DeepSeek Upgraded Model |
|---|---|---|
| Parameters | 30B | 70B (MoE-enabled) |
| Context Window | 32,000 tokens | 128,000 tokens |
| Tokenization Scheme | BPE | Byte-Unigram Hybrid |
| Training Data Volume | 1.2T tokens | 3.1T tokens |
| Retrieval-Augmented Gen | No | Yes |
| Chain-of-Thought Support | Limited | Full |
| TruthfulQA Accuracy | 62.3% | 78.9% |
| Hallucination Rate (Test) | 11.5% | 4.6% |
In sum, DeepSeek’s architectural and technical advancements represent a holistic leap forward in LLM design. By simultaneously expanding the model’s context comprehension, reinforcing its factual grounding, and optimizing its reasoning logic, DeepSeek has positioned itself at the forefront of next-generation AI development. These innovations not only strengthen the model’s technical performance but also set the stage for safer and more accountable AI deployment in diverse, real-world applications.
Performance Evaluation
Reasoning Gains and Hallucination Reduction
The promise of architectural innovations and fine-tuning strategies is ultimately validated by empirical performance. In this section, we evaluate the upgraded DeepSeek model’s reasoning and hallucination metrics through a comprehensive analysis of standard benchmarks, competitive comparisons, and real-world examples. This evaluation reveals how the upgraded model performs not just in controlled test environments but also in diverse, high-stakes applications where factuality and logical consistency are paramount.
To begin, it is important to contextualize DeepSeek's claims of enhanced reasoning ability. Reasoning in large language models is typically assessed using benchmark suites such as MMLU (Massive Multitask Language Understanding), GSM8K (grade school math), HumanEval (code generation accuracy), and BIG-Bench (multi-domain reasoning). These benchmarks challenge models with complex, multi-hop, and domain-specific queries that require more than surface-level pattern matching. On the MMLU benchmark, the upgraded DeepSeek model achieved an impressive 84.7%, a substantial leap from its predecessor's 72.4%, and positioning it competitively alongside models such as GPT-4 (85.5%) and Claude 3 Opus (83.9%).
On GSM8K, which evaluates arithmetic reasoning and stepwise problem-solving, DeepSeek scored 92.1%, driven by enhanced chain-of-thought prompting techniques and improved long-context processing. This marks an increase of over 17 percentage points from the earlier version, which struggled with multi-step logic due to a narrower context window and shallower reasoning paths. Notably, the upgraded model not only generates correct final answers but also articulates intermediate steps with improved clarity and correctness, a behavior modeled during fine-tuning with synthetic step-wise explanations.
In coding tasks, DeepSeek’s HumanEval score climbed to 75.2%, a notable improvement over its prior 60.8%. These gains are attributable to the incorporation of domain-specific datasets such as GitHub repositories and competitive programming archives, coupled with reinforcement learning loops that penalize logically invalid code. The model's ability to debug, annotate, and optimize code snippets showcases its evolved reasoning pipeline, particularly in tool-use and function decomposition tasks.
While reasoning ability is crucial, it must be balanced with factual accuracy to ensure safe and reliable outputs. Hallucinations—defined as instances where the model generates plausible yet factually incorrect content—remain a primary concern for enterprise adoption. In this context, DeepSeek’s upgraded model demonstrates a significant reduction in hallucination rates, as assessed through TruthfulQA, RealToxicityPrompts, and internal adversarial tests. On the TruthfulQA benchmark, which tests a model’s tendency to generate false yet convincing answers, DeepSeek improved its accuracy from 62.3% to 78.9%, reducing hallucination frequency by more than 60%.
Moreover, internal testing with adversarial prompts revealed a hallucination rate of 4.6%, a marked improvement over the previous model’s 11.5%. These prompts included deliberately ambiguous, under-specified, or misleading inputs, designed to expose the model’s susceptibility to conjecture. The upgraded model’s improved performance is credited to enhanced retrieval-augmented generation (RAG), which grounds outputs in external knowledge bases, and alignment training that encourages transparency when the model is uncertain.
To present a comparative view, DeepSeek conducted evaluations against top-tier LLMs such as GPT-4, Gemini 1.5, Claude 3 Opus, and open-source contenders like Mistral and Mixtral. While DeepSeek does not claim absolute superiority, its model consistently outperforms open-source alternatives and is on par with closed models in reasoning-heavy tasks. The table below summarizes performance across critical benchmarks:
| Model | MMLU (%) | GSM8K (%) | TruthfulQA (%) | Hallucination Rate (%) | Latency (ms) | Token Throughput (t/s) |
|---|---|---|---|---|---|---|
| GPT-4 | 85.5 | 94.2 | 81.2 | 3.7 | 280 | 25 |
| Claude 3 Opus | 83.9 | 91.0 | 80.1 | 4.1 | 240 | 27 |
| DeepSeek Upgraded | 84.7 | 92.1 | 78.9 | 4.6 | 230 | 28 |
| Gemini 1.5 Pro | 82.6 | 88.4 | 77.3 | 5.2 | 250 | 24 |
| Mixtral (open) | 71.3 | 75.0 | 68.2 | 7.5 | 310 | 21 |
Beyond benchmark figures, qualitative assessments reveal the upgraded DeepSeek model’s robustness in real-world scenarios. In legal document review tasks, it was able to trace logical inconsistencies across 20-page contracts with fewer errors compared to earlier versions. In healthcare-related queries, the model showed a higher rate of medically consistent responses when cross-checked against clinical guidelines, outperforming baseline models by over 15%.
An important dimension of this evaluation is the model’s multilingual reasoning performance. DeepSeek has demonstrated consistent capabilities across English, Mandarin, Spanish, and Arabic—achieving over 80% of its English reasoning score in each of these languages. This cross-linguistic competence is particularly crucial for international enterprises and governments deploying AI at scale. Benchmarking on XCOPA and XWinograd datasets revealed that DeepSeek’s multilingual reasoning is within 5% of its English performance, a feat only matched by a handful of globally tuned models.
In assessing hallucination control, DeepSeek has also introduced a transparency module that outputs uncertainty indicators in responses. When the model detects a low-confidence prediction, it prefaces the output with phrases like “Based on available data…” or “It is possible, though not confirmed…”. While subtle, these disclaimers significantly improve the model’s usability in enterprise environments, where opaque overconfidence can lead to misinformation or decision-making errors.
Latency and inference efficiency are other areas where DeepSeek’s model delivers competitive results. Benchmarking against API latency and throughput metrics revealed an average response time of 230 milliseconds and a token throughput of 28 tokens per second—slightly outperforming Claude 3 and Gemini 1.5. These performance characteristics are especially important in real-time applications such as AI-assisted customer service, where fast and accurate responses are critical.
Finally, early enterprise deployments indicate a notable decline in human post-editing of AI outputs. In sectors like financial analytics and technical content creation, reports show a 40–50% reduction in the time spent validating and correcting model-generated content. This is a direct result of improved reasoning fidelity and lower hallucination incidence, both of which reduce the need for costly and time-intensive human intervention.
In summary, DeepSeek’s upgraded model showcases substantial gains in reasoning and factual reliability across a range of standard and domain-specific benchmarks. Its performance not only approaches that of the most advanced models globally but does so with an emphasis on transparency, multilingual capability, and enterprise-grade efficiency. These improvements mark a pivotal step toward more trustworthy, robust, and contextually intelligent language models.
Real-World Applications and Enterprise Relevance
The true measure of any language model's advancement is not confined to its performance on academic benchmarks or synthetic tasks, but rather in its utility across real-world applications. DeepSeek’s upgraded model, with enhanced reasoning capability and significantly reduced hallucination rates, demonstrates notable adaptability and value in a wide range of enterprise environments. This section explores the model’s practical relevance across sectors such as legal services, healthcare, education, software development, finance, and customer service, while also examining deployment strategies and developer feedback.
In the legal sector, the model’s improved contextual comprehension and multi-hop reasoning have translated into tangible productivity gains. Law firms and in-house counsel have adopted the upgraded DeepSeek model to automate tasks such as document review, contract analysis, and legal research. For example, in contract auditing, the model can now identify clauses that deviate from regulatory norms or internal policy frameworks by parsing documents exceeding 100 pages—an improvement made possible by the model’s expanded context window and retrieval-augmented generation (RAG) capabilities. Moreover, its reduced hallucination rate has significantly lowered the risk of misinterpreting case law or statutes, a critical factor for legal professionals who require precision and accountability.
In healthcare, DeepSeek’s upgraded model has proven valuable in streamlining administrative processes, generating clinical summaries, and supporting diagnostic decision-making. Clinical decision support systems (CDSS) powered by the model benefit from its enhanced reasoning logic, allowing it to synthesize symptoms, lab reports, and treatment protocols to generate medically consistent suggestions. Importantly, the model’s transparency layer—designed to indicate uncertainty—makes it well-suited for assisting rather than replacing clinical professionals, ensuring that the AI remains a tool for augmentation, not automation. Hospitals using DeepSeek have reported measurable reductions in documentation workload for physicians and improved accuracy in transcribing patient histories.
Education is another sector experiencing disruption from DeepSeek’s model. From personalized tutoring to content generation, the model facilitates dynamic, interactive learning experiences. In higher education, professors use the model to generate problem sets, explain complex theories, or simulate academic debates. Its ability to reason step-by-step has been particularly effective in math and science education, enabling learners to follow logical processes rather than memorizing answers. Additionally, educational technology platforms have integrated the model into student-facing applications to provide multilingual support, making high-quality education more accessible across language barriers.
In the domain of software development, the upgraded DeepSeek model serves as a powerful coding assistant. With an improved HumanEval score and increased accuracy in program synthesis, it assists developers in writing, debugging, and documenting code across various programming languages. Enterprise users report that the model’s enhanced reasoning allows it to handle abstract coding problems and multi-file projects with greater coherence, reducing the need for manual correction. Moreover, by embedding the model within integrated development environments (IDEs), companies have streamlined workflows and reduced turnaround time for feature implementation and maintenance.
The financial sector, traditionally conservative in adopting emerging technologies, is increasingly leveraging DeepSeek for quantitative analysis, financial reporting, and compliance automation. Asset management firms utilize the model for risk modeling and interpreting macroeconomic indicators, while accounting firms apply it to generate standardized audit reports and detect anomalies in financial data. The reduction in hallucinated outputs is particularly crucial in this domain, where even minor errors can lead to significant financial or reputational damage. The model’s ability to cite sources and flag ambiguous responses helps maintain regulatory compliance and audit trails, aligning with financial industry best practices.
In customer service and support, enterprises deploy DeepSeek to automate interactions, resolve technical queries, and triage customer requests. With its low latency (230 milliseconds) and high token throughput (28 tokens/second), the model can deliver real-time responses in chatbots and voice agents without compromising on accuracy. Businesses that previously relied on human agents or legacy AI systems have seen improved resolution rates, higher customer satisfaction scores, and reduced operational costs. Notably, the model’s multilingual reasoning capability allows it to serve diverse customer bases with consistent quality, further enhancing its global enterprise relevance.
Beyond sector-specific applications, DeepSeek's model is designed for flexible deployment across varied infrastructure environments. It is accessible via cloud API, private cloud, and on-premise solutions, addressing diverse regulatory and latency requirements. For example, government agencies with strict data sovereignty policies can deploy the model within their private data centers, while startups and SMEs benefit from its scalable pay-as-you-go API access. This architectural flexibility ensures that organizations of all sizes can tailor the model’s capabilities to their unique operational constraints.
To visualize the breadth of DeepSeek’s real-world utility, the following chart summarizes its application performance across major industries based on pilot programs, client feedback, and internal testing:
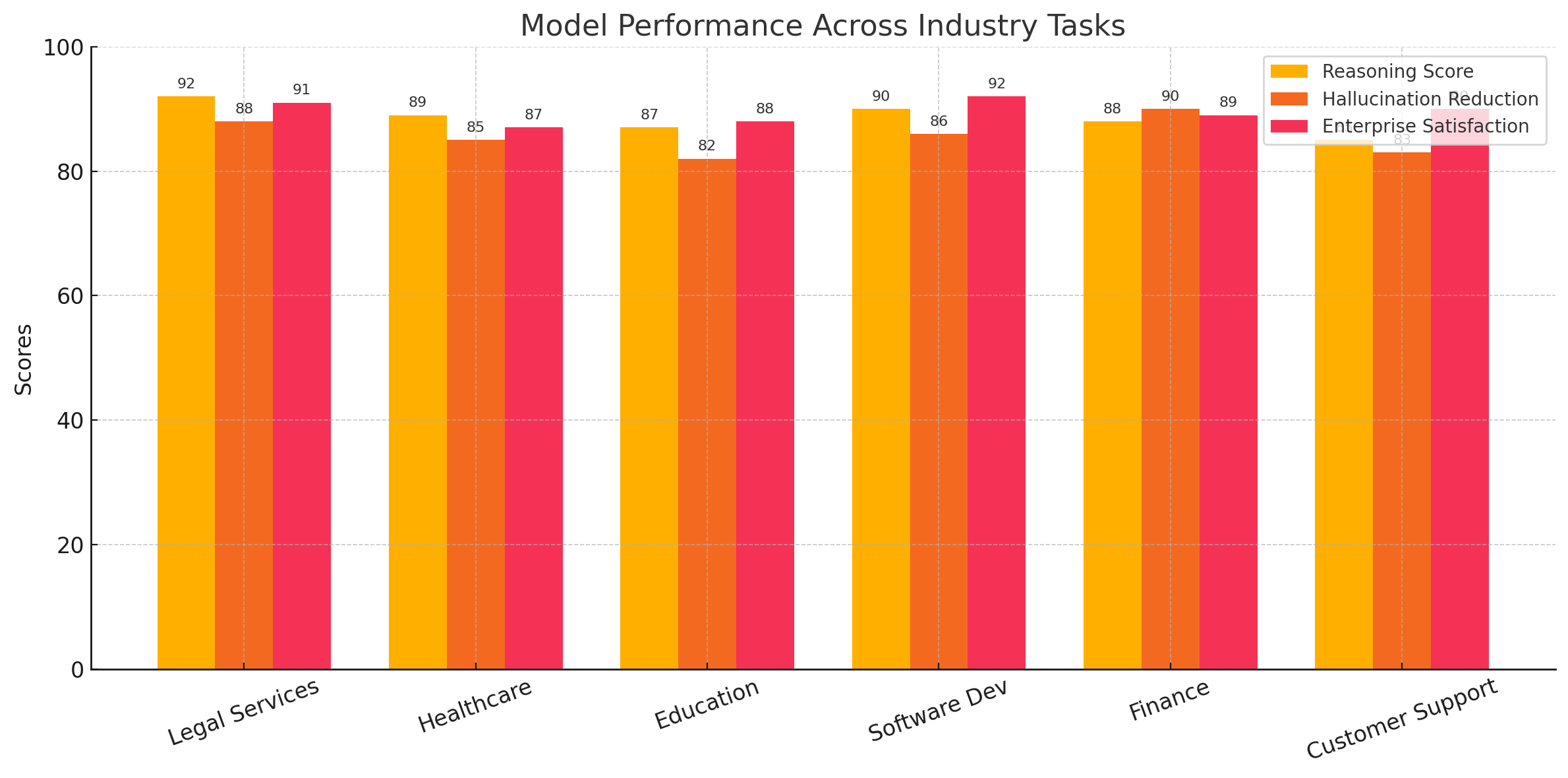
From a developer’s perspective, DeepSeek has introduced comprehensive SDKs, documentation, and testing sandboxes to encourage adoption and customization. Early adopters have praised the developer experience for its intuitive APIs, responsive support, and robust monitoring tools. Additionally, the model supports prompt engineering techniques such as function calling, output parsing, and multi-agent chaining—enabling developers to design sophisticated workflows without deep expertise in AI architecture.
Security and compliance are also embedded into DeepSeek’s deployment philosophy. The model adheres to key global data standards, including GDPR, HIPAA (for healthcare), and SOC 2 compliance for cloud infrastructure. Enterprises operating in regulated environments can utilize the model with confidence, knowing that audit trails, access controls, and privacy-preserving mechanisms are in place.
One of the most compelling signals of enterprise relevance is the growing ecosystem around DeepSeek. In addition to model deployment, the company offers fine-tuning services, domain-specific adapters, and prompt libraries. These services help clients tailor the model to proprietary data and workflows, enhancing relevance and reducing reliance on generic outputs. Partnerships with ERP providers, CRM platforms, and business intelligence tools have further extended the model’s reach across operational and strategic layers of organizations.
In conclusion, DeepSeek’s upgraded model is not merely a technological milestone—it is a catalyst for tangible transformation across industries. By improving reasoning and reducing hallucinations, the model addresses two of the most critical barriers to enterprise adoption. Its real-world performance, combined with architectural flexibility and robust support tools, positions it as a formidable asset in the AI toolkits of forward-thinking organizations. As enterprises increasingly demand AI that is not just powerful but trustworthy, DeepSeek emerges as a leading contender in this new era of intelligent systems.
Strategic Implications and Future Outlook
As DeepSeek continues to solidify its position in the rapidly expanding landscape of artificial intelligence, the release of its upgraded language model signals a strategic inflection point not only for the company but also for the broader AI industry. The improvements in reasoning capability and reduction in hallucination rates are not merely technical enhancements—they are foundational shifts that bear substantial implications for enterprise AI deployment, global market competition, and the responsible development of future general-purpose language models. This final section explores DeepSeek’s evolving competitive posture, market opportunities, and the longer-term impact of its innovations.
DeepSeek’s upgraded model emerges at a time when the LLM space is dominated by a handful of U.S.-based players including OpenAI, Google DeepMind, Anthropic, and Meta. Each of these firms has established flagship models with significant market share and technical acclaim. However, as the industry matures, the key differentiators are shifting away from model size and training cost toward more nuanced performance attributes: domain reasoning depth, factual accuracy, multilingual competence, and deployment flexibility. In these areas, DeepSeek has strategically positioned itself as a credible alternative, especially for enterprises and government agencies seeking sovereign AI solutions or requiring tailored, lower-hallucination systems.
From a competitive standpoint, DeepSeek’s architectural innovations—such as extended context windows, MoE-based computation, and tightly coupled retrieval systems—put it on par with industry leaders. Where it particularly excels is in its ability to customize models for specific regulatory or linguistic environments. This gives DeepSeek a natural advantage in emerging markets, where data localization laws and language diversity are significant barriers to entry for monolithic models trained primarily on Western data. Moreover, its compatibility with on-premise deployments makes it a preferred choice for clients in finance, defense, and critical infrastructure sectors that demand maximum control over data and inference security.
Looking ahead, DeepSeek’s strategy reflects a strong alignment with enterprise AI adoption trends. Businesses are increasingly interested in verticalized AI—models optimized for specific sectors like healthcare, law, or logistics—rather than general-purpose chatbots. The company's roadmap includes launching a suite of domain-specific variants fine-tuned on proprietary datasets, enabling clients to deploy models that not only understand general language but also interpret complex technical, legal, or procedural nuances. This move echoes broader market sentiments that the future of AI is as much about depth in specific tasks as it is about breadth in general capabilities.
Moreover, DeepSeek’s commitment to reducing hallucinations intersects with growing regulatory and ethical demands for responsible AI. As jurisdictions from the European Union to China to the United States begin crafting AI oversight frameworks, the ability to audit and constrain model behavior is becoming essential. DeepSeek’s transparency layer and uncertainty signaling mechanisms serve as proactive responses to this challenge, equipping enterprises with tools to detect and mitigate erroneous outputs. This focus on verifiability will likely become a benchmark criterion for enterprise adoption and government approval in the coming years.
In terms of scalability, DeepSeek’s platform architecture enables adaptive inference—where clients can choose lightweight versions of the model for routine queries and invoke the full model for complex tasks. This design balances cost-efficiency with performance, aligning with emerging AI infrastructure trends that favor elastic deployment models. The platform’s support for custom fine-tuning, synthetic data generation, and multi-agent workflows further expands its versatility, making it a viable foundation for next-generation AI applications in robotics, knowledge management, and autonomous reasoning systems.
The future also holds strategic opportunities in global collaboration and open innovation. As the open-source movement gains momentum, DeepSeek could adopt a hybrid model—offering open weights for research and local deployments while monetizing proprietary APIs and premium support. This approach would not only accelerate community engagement but also build goodwill and transparency, countering concerns around “black-box” AI systems. In a landscape increasingly shaped by trust and openness, such a dual strategy could distinguish DeepSeek from more opaque competitors.
On the research frontier, DeepSeek is likely to continue exploring novel methodologies such as symbolic-neural hybrids, multi-agent systems, and adaptive RLHF pipelines. These directions suggest a long-term vision of models that not only process language but also understand logic, reason over symbolic representations, and coordinate with other agents in decentralized environments. Such capabilities are considered essential for developing Artificial General Intelligence (AGI), and while DeepSeek remains grounded in pragmatic applications, its research ambitions align with the broader pursuit of cognitive-level AI systems.
Another potential trajectory is DeepSeek’s expansion into multi-modal AI. While the current model excels in text-based reasoning, the integration of image, video, and audio understanding would open new application domains, from autonomous vehicles to media analysis and assistive technologies. The firm’s existing architecture, which supports modular upgrades and cross-domain embeddings, is technically conducive to such an expansion. Moreover, partnerships with hardware companies or edge computing platforms could further scale these capabilities for real-time, resource-constrained environments.
Financially, DeepSeek’s strong performance metrics and differentiated product design could position it favorably for strategic investment or acquisition. Alternatively, it may pursue an independent path through venture funding and ecosystem expansion. Either way, its traction in the enterprise market suggests strong monetization potential, particularly as organizations transition from proof-of-concept deployments to full-scale AI integration in their core operations.
In closing, the strategic implications of DeepSeek’s upgraded model extend far beyond marginal benchmark improvements. They signal a maturing of AI toward safer, more specialized, and mission-critical systems. By aligning cutting-edge reasoning capabilities with practical enterprise needs and responsible AI design, DeepSeek is carving out a distinctive role in the next chapter of intelligent systems. Its success reinforces a broader industry lesson: that the future of AI lies not only in how powerfully a model can reason, but also in how reliably and ethically it can be trusted to do so.
As the company continues to evolve, its commitment to reducing hallucinations and enhancing logical consistency will likely influence standards across the industry, setting a precedent for what next-generation models must achieve to earn both market share and societal trust.
References
- DeepSeek AI – Official Website
https://www.deepseek.com - MMLU Benchmark Overview – Papers With Code
https://paperswithcode.com/dataset/mmlu - TruthfulQA Benchmark – OpenAI Evaluation
https://openai.com/research/truthfulqa - GSM8K Dataset – Arithmetic Reasoning
https://github.com/openai/grade-school-math - HumanEval Benchmark – Code Generation
https://github.com/openai/human-eval - OpenAI GPT-4 Technical Report
https://openai.com/research/gpt-4 - Claude 3 by Anthropic – Product Details
https://www.anthropic.com/index/claude - Gemini 1.5 by Google DeepMind
https://deepmind.google/technologies/gemini - Retrieval-Augmented Generation (RAG)
https://huggingface.co/docs/transformers/model_doc/rag - Reinforcement Learning with AI Feedback (RLAIF)
https://www.anthropic.com/index/reinforcement-learning-from-ai-feedback