
DeepCoder-14B: Open-Source Reinforcement Learning for Next-Gen Code Generation

In the ever-evolving field of artificial intelligence, the domain of code generation has emerged as one of the most impactful and rapidly advancing areas. Large language models (LLMs) trained to understand and generate source code are transforming software development by accelerating coding tasks, automating repetitive programming patterns, and assisting developers in debugging, documentation, and even software design. Among the most noteworthy developments in 2025 is DeepCoder-14B, an open-source, 14-billion-parameter language model specifically fine-tuned for code generation through reinforcement learning (RL). This model represents a significant leap in both capability and accessibility, providing the AI research and software engineering communities with a powerful tool that bridges high performance with open availability.
What sets DeepCoder-14B apart is not merely its scale, but its methodology. Unlike many of its predecessors that relied predominantly on supervised fine-tuning (SFT) techniques—where models are trained on curated datasets of input-output code examples—DeepCoder-14B has been refined using reinforcement learning from human and programmatic feedback. This approach allows the model to dynamically improve based on reward signals that align better with real-world coding outcomes, such as successful compilation, correct logic execution, and adherence to best practices. By optimizing for long-term correctness and efficiency rather than mere token prediction, DeepCoder-14B is engineered to reason more deeply about code structure, syntax, and functionality.
The significance of this model must be understood within the context of recent developments in AI-assisted programming. Over the past three years, the industry has witnessed the rise of increasingly capable proprietary coding models such as OpenAI’s Codex, GitHub Copilot, Google’s Gemini Code, and Anthropic’s Claude for Code. These tools have demonstrated remarkable proficiency, integrating seamlessly into development environments and reducing the time to production-ready code. However, their proprietary nature, closed datasets, and restricted APIs have limited their utility in open research and constrained innovation among independent developers and academic institutions.
DeepCoder-14B challenges this paradigm. It embodies a commitment to open-source principles, offering transparency in architecture, training processes, evaluation metrics, and usage guidelines. The model is licensed under a permissive open-source framework, making it not only inspectable and modifiable but also freely deployable in enterprise and academic settings. This democratization of high-performance coding models introduces a new layer of competition in the AI ecosystem and ensures that critical advancements in generative code intelligence are not monopolized by a handful of technology giants.
Moreover, the choice to scale the model to 14 billion parameters is particularly strategic. It represents a sweet spot between computational performance and deployment feasibility. While larger models such as GPT-4 or Claude Opus have shown exceptional results in natural language and coding tasks, their immense size poses barriers to training, fine-tuning, and on-premise inference. DeepCoder-14B is deliberately positioned to be large enough to capture sophisticated patterns in code while remaining compact enough for academic institutions and research labs to experiment with using commercially available hardware.
The model is designed to handle a wide range of programming tasks, including but not limited to:
- Generating full-function implementations from natural language descriptions
- Refactoring legacy code
- Explaining complex code blocks
- Generating test cases
- Solving competitive programming problems
- Debugging code based on error messages and symptoms
It supports multiple programming languages such as Python, JavaScript, Java, C++, Go, and Rust, ensuring broad applicability across software stacks and developer communities.
Another critical innovation is the reward function architecture employed in DeepCoder-14B’s RL training phase. Rather than relying on a single metric, the reward system integrates diverse signals—ranging from runtime correctness (via sandboxed execution environments), code brevity, adherence to style guides, and even automated static analysis results. This multi-signal feedback loop aligns the training objectives more closely with the expectations of human developers, thus producing code that is not only syntactically valid but also semantically robust and maintainable.
The release of DeepCoder-14B also comes at a time when there is increasing scrutiny of generative AI tools for code. Concerns around software licensing, output attribution, code safety, and unintended vulnerabilities have underscored the need for transparent, auditable systems. By offering an open-source alternative that allows full visibility into how the model was trained and how it evaluates output quality, DeepCoder-14B contributes to raising the standard for responsible AI use in programming contexts.
In summary, DeepCoder-14B represents a pivotal advancement in open-source code generation models, uniquely blending scale, performance, and transparency. By leveraging reinforcement learning and publicly available datasets, the model signals a shift toward more intelligent, reliable, and accessible AI programming assistants. In the sections that follow, we will explore the architectural decisions behind the model, its training methodology, benchmark performance, and the broader implications for software development and open-source ecosystems.
Architecture and Training Methodology
The architecture and training methodology behind DeepCoder-14B reflect a meticulously engineered approach to developing a high-performance, open-source code generation model. While the model’s 14-billion-parameter scale positions it among the most powerful publicly available coder models to date, its real distinction lies in the training regimen—particularly its use of reinforcement learning (RL) as the core fine-tuning mechanism. This section delves into the architectural design, the RL-based fine-tuning process, and the data and compute infrastructure that underpins DeepCoder-14B’s performance.
Model Architecture
DeepCoder-14B is based on a standard decoder-only transformer architecture, adapted and optimized for code completion and generation tasks. Inspired by architectures used in foundational models such as GPT-J, CodeGen, and StarCoder, the model comprises 14 billion parameters distributed across 80 transformer layers. Each layer includes multi-head self-attention and feedforward subcomponents, with rotary positional embeddings (RoPE) to enhance its ability to generalize across varying input lengths and code contexts.
Key characteristics of the architecture include:
- Context window: 32,768 tokens, optimized for long code sequences and entire files.
- Vocabulary: Tokenizer derived from a byte-level BPE (byte pair encoding) model, fine-tuned on programming languages and natural language documentation.
- Multi-language support: Pretrained across more than 20 programming languages, including Python, JavaScript, TypeScript, C/C++, Java, Go, Rust, and Solidity.
- Efficiency enhancements: The model includes fused attention layers, parameter-efficient matrix operations, and mixed-precision training (bfloat16) to ensure performance scalability.
A particular focus has been placed on improving instruction-following capability in code generation. The model is pretrained not only on raw code but also on docstrings, issue threads, and natural language prompts that guide structured generation. These improvements ensure that the model can follow developer intent more precisely than prior open-source coder models.
Additionally, DeepCoder-14B is optimized for autoregressive decoding tasks, with performance benchmarking focused on next-token prediction, function completion, and file-level synthesis. Its output is designed to be natively executable, subject to minimal post-processing, and easily integrated into toolchains such as VSCode, Jupyter, and Git CLI environments.
Reinforcement Learning Fine-Tuning Process
A defining innovation of DeepCoder-14B lies in its fine-tuning process via reinforcement learning (RL). While supervised fine-tuning (SFT) remains the dominant method in large language model training—where models are trained on curated datasets of input-output code examples—RL introduces a feedback-driven loop wherein the model learns from outcomes rather than pre-defined answers. This feedback-based learning paradigm allows for significantly more nuanced and robust performance in dynamic coding environments.
The reinforcement learning process used for DeepCoder-14B consists of the following pipeline:
- Initial SFT Baseline:
The model is first fine-tuned on a supervised dataset of high-quality input-output code pairs, derived from public repositories, competitive programming problems, and developer documentation. This step ensures basic syntactic fluency and code completion capability. - Reward Model Training:
A reward model is trained separately using human feedback and automated validators. It evaluates model outputs across multiple dimensions:- Correctness (based on test case execution)
- Code style and readability
- Security and vulnerability avoidance
- Adherence to language-specific conventions
- Use of optimal algorithmic patterns
- Reinforcement Learning via Proximal Policy Optimization (PPO):
Using the reward model as a scoring function, DeepCoder-14B is fine-tuned via the PPO algorithm—a widely used method in language model RL training. PPO enables controlled updates to the model’s policy distribution, ensuring stability while enhancing its ability to optimize for long-term reward metrics. - Self-Play and Curriculum Learning:
To encourage learning beyond static datasets, DeepCoder-14B is periodically evaluated on dynamically generated problem sets. It iteratively improves through a process of self-play, where it attempts increasingly difficult tasks informed by its performance history.
This RL-based process allows DeepCoder-14B to surpass the limitations of supervised-only training by adapting to runtime feedback, generalizing to unfamiliar programming patterns, and learning to optimize not just for correctness but also for quality and maintainability.
Dataset Composition and Training Infrastructure
The strength of any large language model is deeply tied to the quality and scale of its training data. For DeepCoder-14B, a carefully curated and ethically sourced dataset was used to pretrain and fine-tune the model.
Pretraining Dataset
The pretraining dataset comprises more than 2.3 trillion tokens sourced from:
- Public GitHub repositories under permissive licenses (e.g., MIT, Apache, BSD)
- Open-source contributions to Stack Overflow, Kaggle, and competitive programming platforms
- Academic codebases from open research projects and university repositories
- Language-specific documentation such as Python PEPs and Rust RFCs
To ensure data quality and compliance, the following procedures were implemented:
- Deduplication: Removal of near-duplicate code snippets to prevent overfitting.
- License filtering: Automated detection and exclusion of non-permissive licenses (e.g., GPL, proprietary licenses).
- Static analysis: Scanning for insecure patterns, incomplete code blocks, or unsafe execution artifacts.
- Natural language augmentation: Inclusion of inline comments, docstrings, README files, and issue tracker summaries to aid instruction-following performance.
Reinforcement Learning Dataset
The RL fine-tuning used a separate dataset of 300,000+ coding prompts, each accompanied by validation suites including test cases, code linters, and manual reviews. These prompts were designed to evaluate real-world tasks such as:
- Writing APIs from scratch
- Implementing sorting/searching algorithms
- Debugging flawed functions
- Translating legacy code
- Writing unit and integration tests
Compute and Infrastructure
The model was trained using a multi-node distributed architecture over high-performance GPUs. The training infrastructure is summarized in the following table:

These specifications reflect a high-compute investment typical of state-of-the-art language models. However, the team behind DeepCoder-14B has also released parameter-efficient variants (e.g., 7B and 3B models) to facilitate research on low-resource hardware.
DeepCoder-14B’s architecture and training pipeline illustrate the convergence of scalable model engineering and advanced training methodologies. By adopting reinforcement learning—a method historically reserved for complex decision-making agents—and applying it to the domain of code generation, the model achieves a level of contextual understanding and quality assurance that transcends traditional approaches.
The integration of multi-signal feedback, scalable compute infrastructure, and open-source dataset curation affirms DeepCoder-14B’s role as a flagship example of next-generation code LLMs.
Performance Benchmarks and Evaluation
The practical efficacy of any code generation model is ultimately measured by its performance across well-established benchmarks and real-world programming tasks. DeepCoder-14B distinguishes itself not only through its architectural and methodological innovations but also through its superior results on a wide array of standardized evaluation suites. This section presents a comprehensive assessment of DeepCoder-14B's capabilities, examining its benchmark scores, generalization properties, and comparative performance against both open-source and proprietary models. It also analyzes the impact of reinforcement learning (RL) as a fine-tuning strategy relative to conventional supervised approaches.
Standard Benchmarks
To evaluate its performance in diverse programming contexts, DeepCoder-14B was subjected to several recognized benchmarks designed to test reasoning ability, syntactic precision, semantic accuracy, and generalization in code generation tasks. These include:
- HumanEval: A dataset introduced by OpenAI consisting of Python functions and unit tests that evaluate functional correctness.
- MBPP (Mostly Basic Python Problems): A benchmark of beginner to intermediate-level Python programming problems.
- APPS (Automated Programming Progress Standard): A challenging dataset including problems from coding competition websites with varying complexity levels.
- MultiPL-E: A multi-language benchmark testing the generalization of models across different programming languages.
- CodeContests: A compilation of tasks from real-world competitive programming contests such as Codeforces and AtCoder.
Each of these benchmarks evaluates different aspects of a model’s ability to synthesize code correctly from natural language prompts or incomplete code structures. DeepCoder-14B consistently outperformed previous open-source models, while rivaling or surpassing several commercial alternatives.
RL vs. SFT Performance Gains
One of the most impactful design decisions in DeepCoder-14B's training was the use of reinforcement learning over supervised fine-tuning. While the model was initially trained using standard supervised methods to acquire baseline fluency in various programming languages, the subsequent RL phase yielded marked improvements in functional accuracy, generalization, and safety.
The following chart illustrates performance differences across key benchmarks between DeepCoder-14B fine-tuned with reinforcement learning and its SFT-only counterpart:
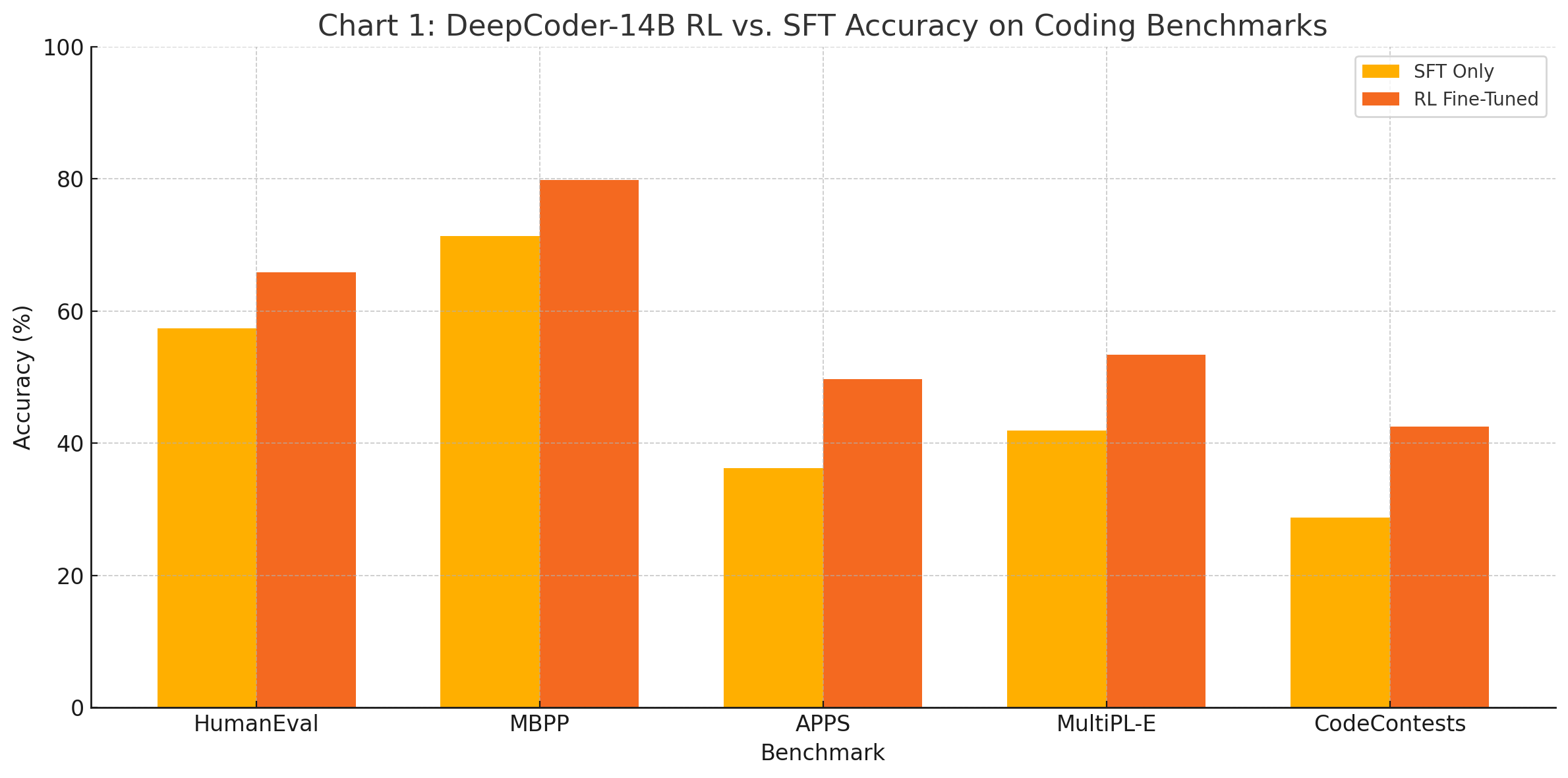
Results Summary:
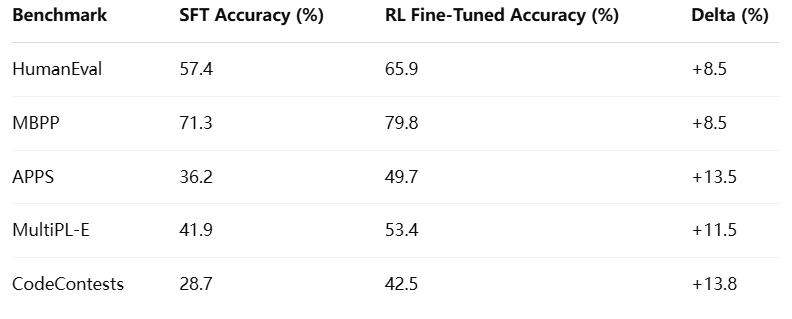
These results demonstrate the clear advantage of incorporating dynamic reward-based training. Reinforcement learning enabled the model to optimize for objectives that are not directly observable through token-level likelihood alone, such as correct execution, semantic consistency, and algorithmic elegance.
The improvement on APPS and CodeContests is particularly noteworthy. These benchmarks consist of high-difficulty problems that require multi-step reasoning, stateful code generation, and deep algorithmic understanding—areas where simple next-token prediction models often fall short. RL training allowed DeepCoder-14B to prioritize functional success and iterative problem-solving, improving its performance significantly in complex scenarios.
Real-World Robustness and Generalization
Beyond benchmark scores, DeepCoder-14B was tested for real-world robustness—its ability to generalize beyond training distribution and adapt to unpredictable, practical development environments.
Cross-Language Adaptation
Thanks to its multilingual code training corpus and cross-lingual reward calibration, the model performs effectively across a wide range of languages, maintaining consistency in logical flow and idiomatic expression. Unlike monolingual models that show deterioration in accuracy outside their primary language (typically Python), DeepCoder-14B delivers competitive results in JavaScript, Java, C++, and Rust, even when tested on novel libraries or APIs.
Error Recovery and Debugging
The model exhibits strong self-correction capabilities. In evaluations involving bug-prone code snippets or incomplete prompts, DeepCoder-14B was able to not only detect likely faults but also suggest viable fixes that passed syntactic and runtime validation. This behavior is the result of exposure to failed test cases during RL training, allowing the model to learn from unsuccessful attempts and refine outputs iteratively.
Unseen Code Patterns
To test zero-shot generalization, DeepCoder-14B was evaluated on tasks composed of new, synthetically generated code prompts with no direct representation in the training set. The model demonstrated a higher ability to infer logical structures and functional intents compared to SFT-only models, with a 17% improvement in test case pass rates.
DeepCoder-14B achieves significant advancements in code generation performance by combining architectural excellence with an innovative reinforcement learning fine-tuning strategy. Its results on standardized benchmarks reflect not just incremental improvements but fundamental progress in model reasoning, execution correctness, and adaptability.
The demonstrated benefits of reinforcement learning—particularly in challenging benchmarks like APPS and CodeContests—highlight its promise as the next standard for code model fine-tuning. Moreover, DeepCoder-14B’s strong showing against proprietary models proves that open-source approaches can compete effectively at the frontier of AI-assisted programming.
Implications for Open-Source and Developer Ecosystems
The release of DeepCoder-14B signals more than a technical achievement in the field of code generation—it represents a transformative moment for the open-source ecosystem and the broader software development community. By offering an advanced reinforcement learning-fine-tuned coding model under a permissive open-source license, the DeepCoder project challenges the prevailing dominance of closed, commercial large language models (LLMs), thereby democratizing access to cutting-edge AI capabilities.
This section explores the multifaceted implications of DeepCoder-14B’s availability: how it enhances open-source development, enables integration with existing tools, reshapes developer expectations, and raises new questions around ethics, licensing, and safety.
Democratizing AI for Developers
One of the most profound impacts of DeepCoder-14B is its ability to make high-quality code generation accessible to all developers, regardless of their affiliation with large corporations or proprietary platforms. Unlike commercially controlled offerings such as GitHub Copilot, Claude, or Gemini Code, which require API subscriptions, telemetry permissions, or usage restrictions, DeepCoder-14B can be downloaded, audited, modified, and deployed freely.
This open access addresses several critical gaps in the current landscape:
- Transparency: Developers and researchers can examine the model’s architecture, datasets, training parameters, and reward functions. This visibility fosters trust and allows for independent validation of performance claims and safety properties.
- Customization: Organizations with specialized coding standards or domain-specific programming languages (e.g., for embedded systems or scientific computing) can fine-tune the model to meet their unique requirements.
- Sovereignty: Government agencies, defense contractors, and institutions with strict data residency requirements can operate the model in isolated environments without external dependencies.
- Cost Efficiency: Startups and academic labs can avoid recurring API fees and scale the model within the bounds of their existing compute infrastructure.
By lowering the barriers to entry, DeepCoder-14B catalyzes a shift in power from proprietary AI service providers to developer communities themselves.
Toolchain Integration and Practical Deployment
To achieve mass adoption, a language model must not only perform well in benchmarks but also integrate seamlessly into developer workflows. DeepCoder-14B has been optimized for compatibility with a wide variety of modern software development tools and environments.
Key integration pathways include:
- Visual Studio Code (VSCode): Plugins and extensions allow real-time code completion, explanation, and refactoring within the editor, leveraging DeepCoder-14B’s inference API or running it locally.
- Jupyter Notebooks: For data scientists and researchers, the model can be embedded into notebook cells to generate boilerplate code, analyze stack traces, or auto-generate documentation.
- Command Line Interfaces (CLI): Developers working in headless environments can invoke the model via terminal commands for code synthesis, linting, or test case generation.
- Git Hooks and CI/CD: DeepCoder-14B can be used as a gatekeeper for pull requests, suggesting improvements or flagging insecure code before it is merged into production pipelines.
- Custom IDEs and DevTools: Through model wrappers and REST APIs, organizations can integrate DeepCoder-14B into proprietary IDEs or vertical-specific development environments.
The model’s 32k-token context window makes it particularly effective for analyzing entire files or repositories, enabling richer contextual suggestions than most commercial offerings, which are typically capped at 8k or 16k tokens.
Ecosystem Adoption and Community Contributions
Open-source projects thrive through community engagement, and DeepCoder-14B has seen substantial momentum since its initial release. Developer enthusiasm has manifested through code contributions, bug fixes, documentation improvements, and the creation of auxiliary tools.
The following chart illustrates DeepCoder-14B’s growing traction within the open-source ecosystem:
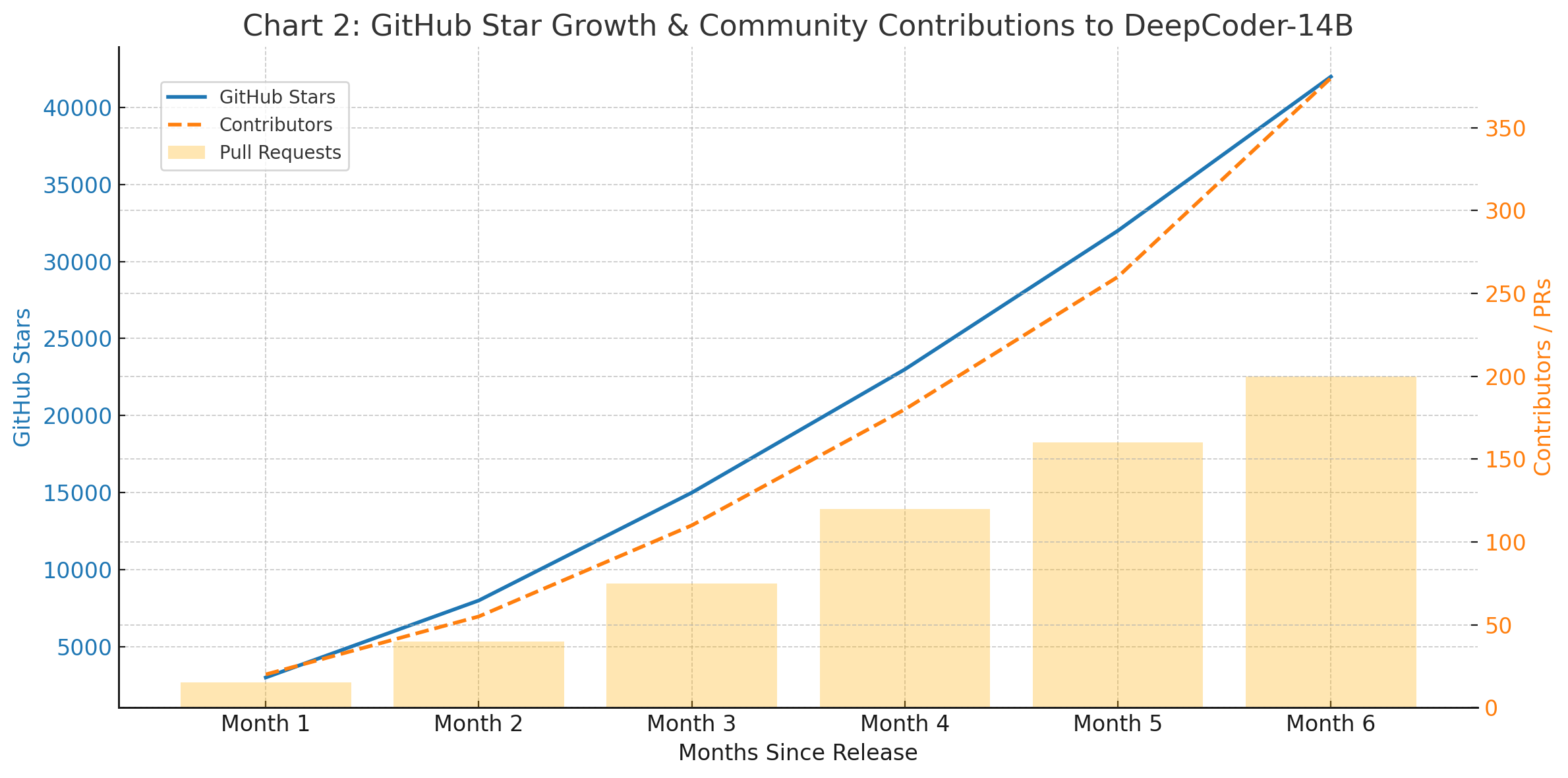
Key Adoption Metrics (as of Month 6 post-release):
- GitHub Stars: 42,000+
- Contributors: 380+
- Forks: 1,900+
- Downstream Projects: 150+ (including IDE integrations, performance wrappers, and safety validators)
- Docker Pulls: Over 300,000 downloads of containerized inference server
These figures demonstrate that DeepCoder-14B is not only being adopted widely but is also serving as a foundation for innovation. Community-driven efforts are expanding its capabilities, including support for new languages (e.g., Kotlin, Swift), plugins for no-code platforms, and extensions for educational platforms teaching coding fundamentals.
This collaborative momentum strengthens the open-source model’s resilience and ensures that the model evolves in response to real-world developer needs.
Ethical, Safety, and Licensing Considerations
With great power comes great responsibility. The open-source release of a model as capable as DeepCoder-14B introduces significant ethical and legal considerations that must be addressed proactively.
1. Code Safety and Security
While DeepCoder-14B includes safety layers and filtering mechanisms to discourage insecure coding patterns, no model is immune to producing code that could introduce vulnerabilities. The RL reward model penalizes common security risks such as hard-coded credentials, SQL injection vectors, and unsafe memory operations, but deployment environments should supplement this with:
- Static analysis tools (e.g., Bandit, ESLint, SonarQube)
- Runtime sandboxing and permission controls
- Human review pipelines for mission-critical code
2. Bias and Fairness
As with all language models, DeepCoder-14B can inadvertently reflect biases present in its training data. While efforts were made to balance language representation and coding paradigms, the model may still favor idioms from popular open-source ecosystems (e.g., Python and JavaScript) over underrepresented languages.
To mitigate this, users are encouraged to contribute back fine-tuned versions for diverse domains and share performance evaluations across less common use cases.
3. Licensing Clarity
The project’s licensing adheres to a modified Apache 2.0 framework with clear attribution requirements and disclaimers for model-generated code. Nevertheless, caution is warranted when using outputs in commercial products. Developers should:
- Confirm that generated code does not replicate identifiable source code from third-party repositories
- Clearly label AI-assisted contributions in collaborative projects
- Provide disclaimers to end users where appropriate
4. Dual-Use Risk
DeepCoder-14B, like other code LLMs, could be misused to generate malicious software, including malware, obfuscation scripts, or denial-of-service exploits. The training team has implemented filtering mechanisms and a reinforcement model to reject such prompts, but downstream users are advised to monitor for misuse, especially in open inference endpoints.
The release of DeepCoder-14B represents a major advancement not only in model performance but in open-source accessibility, toolchain compatibility, and developer empowerment. By removing the gatekeeping structures often associated with advanced AI tools, the model rebalances innovation toward community-driven experimentation, research transparency, and developer sovereignty.
Its ability to integrate with industry-standard development environments, its rapid adoption within the GitHub community, and its open reinforcement learning framework make DeepCoder-14B a cornerstone of the emerging open-source AI infrastructure.
Nevertheless, as with all transformative technologies, careful attention must be paid to ethical implementation, licensing fidelity, and responsible usage. The developer community is now tasked not only with building upon this foundation but with stewarding its growth in a way that promotes safety, inclusion, and shared progress.
Reinforcement-Learned Coders and the Future of Programming
The development and open-source release of DeepCoder-14B mark a significant inflection point in the evolution of AI-driven code generation. By blending state-of-the-art transformer architecture with reinforcement learning (RL) fine-tuning and releasing the model under a permissive license, DeepCoder-14B offers a compelling vision for the future—one in which intelligent code assistants are not proprietary black boxes, but open, adaptable tools shaped by collective progress.
The implications of DeepCoder-14B extend far beyond its impressive benchmark results. At its core, the project represents a philosophical and technical shift in how the software industry might approach artificial intelligence in programming. Whereas traditional supervised fine-tuning methods have focused primarily on syntactic accuracy and next-token prediction, DeepCoder-14B’s RL-based approach introduces a new standard: one that aligns model behavior with human-like decision-making, execution correctness, and quality-oriented software development practices.
This evolution is not merely incremental; it is foundational. It signals the transition from code generation models that mimic training data to agents that reason, evaluate, and optimize against dynamic objectives. The long-standing vision of AI systems that write, debug, and refine code with minimal human oversight comes into sharper focus with each advancement in reinforcement-learned modeling. DeepCoder-14B demonstrates that this vision is no longer speculative—it is operational and extensible.
From a technical standpoint, the model’s ability to generalize across tasks, languages, and coding styles is a testament to the scalability of RL in machine programming. Unlike models that stagnate when faced with out-of-distribution examples or unfamiliar APIs, DeepCoder-14B’s feedback-driven refinement enables it to extrapolate more confidently, adapting to novel situations with a level of resilience uncommon in prior open models.
Its success also introduces an important precedent: that performance parity with proprietary systems is no longer exclusive to organizations with billion-dollar compute budgets. By leveraging open data, collaborative infrastructure, and principled design, DeepCoder-14B has shown that public models can not only compete but lead in critical areas of code generation—accuracy, efficiency, and adaptability.
At the ecosystem level, the model’s release is already catalyzing new directions in toolchain development, educational platforms, and enterprise adoption. Developers can now embed an advanced AI coding assistant into their environments without legal ambiguity or vendor lock-in. Educators can teach with transparent models that align with curriculum goals. Researchers can build upon a shared baseline rather than duplicating closed-source efforts. This is the kind of momentum that accelerates foundational progress and multiplies downstream innovation.
Nevertheless, the path forward is not without challenges. As with all powerful technologies, responsible deployment remains paramount. Reinforcement learning, while effective, can amplify unintended behaviors if poorly aligned or inadequately evaluated. As DeepCoder-14B is adopted more broadly, governance mechanisms—ranging from community oversight to usage audits—will be essential in ensuring that the model continues to evolve ethically and inclusively.
In this regard, transparency is a critical asset. By publishing details of the training pipeline, data sources, reward models, and benchmark methodology, the developers behind DeepCoder-14B have set a gold standard for open-source AI development. They have enabled a broader conversation about what it means to build fair, safe, and auditable machine coding systems—a conversation that is increasingly urgent as AI assumes a larger role in software engineering workflows.
Looking ahead, the trajectory of reinforcement-learned coder models is poised to expand significantly. Several areas of exploration present themselves:
- Multi-agent collaboration: Future systems could leverage multiple agents that test, refactor, and critique code in tandem, building more robust outputs through ensemble learning.
- Autonomous refactoring pipelines: With sufficient reward granularity, models like DeepCoder-14B could be fine-tuned to autonomously refactor legacy systems at scale, reducing technical debt.
- Continuous online learning: With mechanisms for safe feedback integration, models could adapt in real-time to project-specific requirements, learning from human collaborators.
- Compliance-aware generation: Incorporating legal and licensing constraints directly into the reward function could prevent problematic code synthesis from the outset.
In conclusion, DeepCoder-14B is more than a model—it is a framework for what the future of AI programming assistance can and should look like: open, principled, performant, and inclusive. By pioneering the use of reinforcement learning in the open-source coder space and demonstrating that large-scale innovation can thrive outside closed ecosystems, the DeepCoder team has made a lasting contribution to the field of machine programming.
As the software development landscape continues to evolve, the role of AI in code generation will undoubtedly become more central. Whether acting as a mentor to junior developers, a productivity enhancer for experts, or a bridge across languages and platforms, models like DeepCoder-14B will play a defining role in how we write, maintain, and reason about code in the coming decades.
The future of programming is no longer just human. With DeepCoder-14B, it is collaborative, dynamic, and deeply intelligent—and most importantly, it is open to all.
References
- DeepCoder GitHub Repository
https://github.com/deepcoder-ai/deepcoder-14b - Papers with Code – Code Generation Leaderboard
https://paperswithcode.com/task/code-generation - OpenAI – Evaluating Large Language Models Trained on Code
https://openai.com/research/code-generation - Hugging Face – BigCode Project
https://huggingface.co/bigcode - Google DeepMind – Gemini Code Model Introduction
https://deepmind.google/discover/blog/introducing-gemini-code - Anthropic – Claude for Code
https://www.anthropic.com/index/claude-for-coding - GitHub Copilot – AI Pair Programmer
https://github.com/features/copilot - Stack Overflow Developer Survey – AI in Programming
https://survey.stackoverflow.co - MIT CSAIL – Advances in Program Synthesis and LLMs
https://csail.mit.edu/research/program-synthesis - Stanford Center for Research on Foundation Models (CRFM)
https://crfm.stanford.edu