
ByteDance’s Seed-Thinking-v1.5 – A New Milestone in AI Reasoning

Artificial intelligence has made remarkable strides in generating fluent language, but a newer frontier is emerging: reasoning AIs. Unlike standard large language models that produce answers in one step, reasoning-focused models “think” through problems by breaking them into intermediate steps (a process often called chain-of-thought reasoning). These models effectively perform metacognition – reasoning about their own reasoning – to verify answers and solve complex tasks that previously stumped AI. By reflecting step-by-step and even checking their work, reasoning AIs can provide more comprehensive and well-founded answers at the cost of a bit more computation time. This approach has attracted enormous interest as it promises AI systems that are not just fluent, but trustworthy and adept at tackling advanced problems in math, coding, science and beyond.
The race to build better reasoning AIs kicked off in earnest in late 2024 when OpenAI previewed its first reasoning-optimized model (internally code-named “o1”). OpenAI’s o1 (part of its “Strawberry” series of models) demonstrated how adding chain-of-thought could significantly improve problem-solving on challenging benchmarks. This sparked a new wave of innovation: multiple AI labs and companies began developing their own “thinking” models. In January 2025, Chinese startup DeepSeek open-sourced DeepSeek-R1, a model trained via reinforcement learning to think through problems, achieving performance on par with OpenAI’s o1 – but at a fraction of the size and cost. Notably, DeepSeek-R1 was offered openly (via Hugging Face) and boasted 96% lower usage cost than OpenAI’s model, highlighting how efficient training and open collaboration could democratize advanced AI. The rush was on: other Chinese firms like Moonshot AI, MiniMax, and iFlyTek also rolled out reasoning models in quick succession. The clear message was that reasoning capabilities are the new battleground for AI, with big implications for which companies lead the next era of intelligent systems.
Now it’s TikTok parent ByteDance’s turn to enter this arena in a big way. ByteDance had already signaled its ambitions with its flagship large model Doubao-1.5-Pro launched in January 2025, which it claimed could outperform OpenAI’s o1 on certain reasoning benchmarks like AIME (a challenging math/logic exam). Building on that momentum, ByteDance’s AI lab (often dubbed the “Doubao Team”) has unveiled a new reasoning-focused AI model called Seed-Thinking-v1.5. Announced in April 2025, Seed-Thinking-v1.5 is described as an “upcoming” advanced large language model (LLM) explicitly designed to push the state of the art in logical reasoning across STEM fields and general domains. This model isn’t just a minor tweak – it represents a convergence of cutting-edge techniques (like Mixture-of-Experts architecture and reinforcement learning fine-tuning) aimed at creating an AI that effectively “thinks before it speaks.” ByteDance’s technical report on Seed-Thinking-v1.5 highlights that the model “prioritizes structured reasoning and thoughtful response generation,” meaning it internally works through problems in a disciplined way before delivering answers. Although as of this writing the model weights are not publicly available for download or use, the detailed paper and results shared by ByteDance give a glimpse into a system poised to compete with the best from OpenAI, Google, and others in reasoning prowess.
So what exactly is Seed-Thinking-v1.5, and why is it garnering attention? In short, it’s ByteDance’s bid to join (and possibly lead) the new “reasoning AI” race. The model leverages a unique combination of a Mixture-of-Experts (MoE) neural architecture and a multi-stage training process heavy on reinforcement learning (RL) to achieve exceptional performance on tasks that require multi-step reasoning. ByteDance reports that Seed-Thinking-v1.5 can solve difficult math problems, write and debug code, answer scientific questions, and even handle general knowledge queries with impressive accuracy. In their internal evaluations, Seed-Thinking-v1.5 achieved 86.7% accuracy on AIME 2024, 55.0% pass@8 on Codeforces (a competitive coding benchmark), and 77.3% on the Graduate-level Physics Questions (GPQA) science benchmark. These scores are at or near the level of the very best models in the world, like OpenAI’s latest GPT-based reasoners and Google’s Gemini, despite Seed-Thinking-v1.5 being much smaller in active size. Perhaps most strikingly, ByteDance achieved this with an architecture that uses only 20 billion parameters per inference (the “experts” engaged for a given query) out of a total pool of 200 billion parameters available. In other words, it’s a highly efficient model that dynamically taps into specialized “skills” as needed – more on this shortly. Early results even show Seed-Thinking-v1.5 outperforming other state-of-the-art reasoners on certain challenges (for example, it tops Google’s Gemini and OpenAI’s model on the tricky ARC-AGI test of broad problem-solving). With such credentials, Seed-Thinking-v1.5 is being hailed as a new milestone for reasoning AIs and a strong sign that ByteDance intends to be a serious player in advanced AI research.
In the rest of this article, we’ll delve into how Seed-Thinking-v1.5 is built and what makes it different, examine its performance relative to peers like GPT-4, Claude, and Gemini, explore potential real-world applications, and consider the broader implications and industry reactions to this development. By the end, it should be clear why Seed-Thinking-v1.5 is a fascinating case study in the evolving landscape of AI – one where simply predicting text is giving way to reasoning through problems, and where companies like ByteDance are leveraging novel strategies to close the gap with AI giants. Let’s start by unpacking the technical design that underpins Seed-Thinking-v1.5’s “seed of thought.”
Inside Seed-Thinking-v1.5
Architecture and Reasoning Approach
Seed-Thinking-v1.5’s Architecture – Mixture-of-Experts (MoE): One of the core differentiators of Seed-Thinking-v1.5 is that it’s built on a Mixture-of-Experts architecture. In a traditional transformer-based language model (like GPT-4 or Claude), all the model’s parameters are usually “dense,” meaning every query activates all layers and weights of a giant neural network. By contrast, a Mixture-of-Experts model consists of multiple sub-models (experts) each specializing in certain types of data or tasks, and only a subset of these experts are activated for a given input. This can dramatically improve efficiency because the computation is focused on the most relevant parts of the network for each query. Seed-Thinking-v1.5 follows this approach: it reportedly has 200 billion parameters in total, spread across many expert subnetworks, but uses only 20 billion of them for any single query. In effect, the model is as if one had a team of 10 experts (each ~20B parameters) and, depending on the question, the model routes the query to the few experts best suited to answer it. According to ByteDance, this design makes Seed-Thinking-v1.5 “a relatively small [model]” in terms of active compute, yet with the knowledge capacity of a much larger model. The idea of MoE has been gaining popularity (Meta’s research on a MoE LLaMA and Mistral’s “Mixtral” experiments are noted examples), because it offers a tantalizing prospect: scaling model size without a proportional scaling of inference cost. By combining multiple specialists, an MoE model can cover broad knowledge and skills, but at inference time it’s fast and cost-effective since only relevant experts fire.
In Seed-Thinking-v1.5’s case, ByteDance hasn’t detailed exactly how the experts are divided (e.g. by domain like math vs. coding, or by some other clustering), but they emphasize that each expert specializes in different domains and that the system learns to route queries appropriately. This modular design likely contributes to the model’s strong performance across disparate areas – from math competitions to coding challenges – because the model can invoke highly tuned circuits for each type of problem. MoE does introduce complexity (e.g. a gating mechanism to choose experts), but ByteDance has experience from earlier models (like Doubao) and presumably fine-tuned this process. The payoff is significant: efficiency. For context, if OpenAI’s GPT-4 is (hypothetically) hundreds of billions of parameters dense, it means every query involves that entire network, whereas Seed-Thinking-v1.5 manages to rival GPT-4-level performance while only utilizing 1/10th of that at a time. VentureBeat notes that Seed-Thinking-v1.5 is “positioned as a compact yet capable alternative to larger state-of-the-art models” thanks to this architecture. In practice, a smaller active model not only means faster responses and lower inference costs, but it can also reduce overfitting – each expert can generalize well on its domain without interfering with others. This helps the model maintain high accuracy on “a wide range of benchmarks” including both STEM and general tasks.
Training with Reinforcement Learning and Chain-of-Thought: If the MoE architecture gives Seed-Thinking-v1.5 the capacity and efficiency, it’s the training methodology that imbues it with advanced reasoning ability. ByteDance took a reinforcement learning (RL)-heavy approach to train this model, explicitly encouraging it to perform chain-of-thought reasoning before final answers. The journey began with supervised fine-tuning: the team curated a high-quality dataset of 400,000 examples for initial training. Notably, 300k of these were “verifiable” problems – things like math, logic puzzles, and coding tasks where there is a definitive correct answer – and 100k were “non-verifiable” open-ended prompts (creative writing, roleplay, general Q&A). This balance ensured the model had a strong grounding in tasks where reasoning can be objectively evaluated, while still being exposed to free-form instructions.
However, the true secret sauce is in the RL fine-tuning phases that followed. Seed-Thinking-v1.5 was further trained via reinforcement learning to refine its reasoning strategies and align its outputs with what humans prefer. ByteDance devised custom RL algorithms – referred to as VAPO (Value Aware Policy Optimization) and DAPO (Dynamic Advantage Policy Optimization) – to stabilize the training process. Why custom RL? Training large language models with RL can be tricky; straightforward approaches often lead to model collapse or erratic behavior, especially with long, multi-step outputs (the reward signal can be sparse or misleading over a long reasoning chain). The VAPO and DAPO frameworks introduced by ByteDance tackle these issues by reducing reward sparsity and mitigating instabilities. Essentially, they combine elements of actor-critic methods with dynamic adjustments, so the model can safely learn from trial and error even when solving complex problems that require many steps of thinking. This allowed Seed-Thinking-v1.5 to practice chain-of-thought reasoning in a controlled way – making mistakes, getting feedback, and improving its step-by-step approach iteratively.
A critical part of this RL training was the use of specialized reward models to guide the AI’s learning. ByteDance employed a two-tier reward system to evaluate the model’s intermediate reasoning and final answers. First, they built Seed-Verifier, a rule-based tool (likely an automated math checker) that can tell if the model’s answer is actually correct in problems with a known solution. For example, if the model is solving a math equation or coding challenge, Seed-Verifier can compare the model’s answer against ground truth or test cases to give a reward signal. Second, they introduced Seed-Thinking-Verifier, which is described as a “step-by-step reasoning-based judge”. This component likely examines the chain-of-thought itself, checking whether the reasoning process is logically consistent and not cheating (to avoid the model simply writing nonsense steps to appease the reward). By combining these, the model gets nuanced feedback: it learns not just to get the right answers but to follow a sound reasoning process. This innovation helps resist reward hacking (where a model might exploit loopholes in a reward function) and ensures the model’s explanations are aligned with correctness. In essence, Seed-Thinking-v1.5 was trained to be its own harsh critic: it generates potential solutions with reasoning, then an internal judge (the verifier) evaluates those steps, and the model adjusts accordingly.
The training dataset for RL was also carefully segmented into verifiable vs. non-verifiable tasks. For verifiable tasks (e.g. math puzzles, logic riddles), ByteDance curated 100,000 high-quality questions from sources like elite competitions and expert-written problems. These are tasks where a definite answer exists and the model’s reasoning can be checked exactly – perfect for chain-of-thought training because the model can be told unambiguously when it’s right or wrong. In fact, over 80% of these STEM problems were advanced mathematics questions, reflecting a heavy emphasis on math reasoning. They even included things like Sudoku and 24-point card puzzles, incrementally ramping up difficulty as the model improved. This curriculum-style training likely helped Seed-Thinking-v1.5 acquire robust problem-solving skills. For non-verifiable tasks (open-ended queries without a single correct answer), the team used human preference modeling: they gathered prompts and had a reward model that scored outputs based on human-like judgments (which answer is more helpful or well-written). This way, the model also learns how to produce coherent and preferred answers in general conversational settings – ensuring that the heavy focus on math/logic doesn’t make it too rigid or unfriendly for everyday use. The result of this multi-phase training is a model that excels at reasoning while remaining general-purpose. Interestingly, the developers observed that focusing on verifiable, structured tasks had a spillover benefit: the model generalizes strongly to creative and open-ended domains as well, arguably because the rigorous training in reasoning “imbued” it with a structured way of thinking even when dealing with imaginative prompts. In other words, teaching an AI to be good at math and logic can make it a better all-around thinker, even for tasks like storytelling – a fascinating insight from Seed-Thinking-v1.5’s development.
Infrastructure and Engineering Feats: Training a 200B-parameter MoE model with custom RL is a monumental undertaking, and ByteDance had to innovate on the systems side as well. They built their training pipeline on a platform called HybridFlow, orchestrated with Ray clusters (a distributed computing framework), and introduced what they call a Streaming Rollout System (SRS). The SRS is particularly interesting: it separates model evolution from runtime execution, allowing them to asynchronously manage partially completed generations across different model versions. In plainer terms, while one version of the model is exploring solutions, another could be training, and the system streams experiences between them. This decoupling reportedly gave a 3× speedup in RL training cycles. Faster iteration means the team could run more training experiments in the same time, likely accelerating the model’s improvement. They also deployed a host of efficiency tricks: FP8 mixed precision was used to save memory (FP8 refers to 8-bit floating point, an even lower precision than the more common 16-bit, allowing more data to be packed into GPU memory with minimal accuracy loss). They implemented “expert parallelism” (to distribute the MoE experts across GPUs efficiently) and kernel auto-tuning to optimize the low-level operations for maximum throughput. A custom “ByteCheckpoint” system was developed for robust checkpointing of the massive model, ensuring training could resume smoothly if interrupted. Additionally, an AutoTuner was used to automatically find the best parallelism and memory allocation strategies as the training progressed. All these engineering enhancements contributed to pulling off an incredibly complex training regimen without breaking the bank (or the hardware).
In summary, the architecture and approach behind Seed-Thinking-v1.5 reads like a tour-de-force of modern AI techniques: a Mixture-of-Experts transformer giving it scale and specialization, chain-of-thought reinforcement learning giving it reasoning skill, and a suite of infrastructure optimizations ensuring it all runs efficiently. It’s worth noting that this recipe wasn’t developed in isolation – it builds upon trends in the community. For instance, DeepSeek-R1 had already demonstrated that pure RL can “teach” an LLM to reason (their R1-Zero model learned to self-verify and reflect with RL alone). OpenAI’s own research into reasoning models (the o1, o2, etc.) and Google’s push for “thinking” models like Gemini likely provided inspiration. ByteDance synthesized these ideas and added innovations of its own (like the dual verifier system and SRS). The end result is a model that literally has thinking in its name – and by all accounts, it lives up to it by thinking things through before answering. Next, let’s see how all these design choices translate into performance metrics, and how Seed-Thinking-v1.5 stacks up against the likes of GPT-4, Claude, and Gemini in the arena of reasoning.
Performance Metrics and Comparison with Other Reasoning AIs
When it comes to raw performance, Seed-Thinking-v1.5 has proven itself on an array of challenging benchmarks. ByteDance’s team evaluated the model on tasks spanning mathematics, coding, science, and general knowledge – essentially stress-testing the AI’s reasoning across domains. The results are impressive: on several key benchmarks, Seed-Thinking-v1.5 is right up there with the best models from industry leaders. Let’s break down some of the notable metrics:
- AIME (American Invitational Math Exam): This is a famously difficult math contest used to test advanced problem-solving. Seed-Thinking-v1.5 scored 86.7% on the 2024 AIME and 74.0% on the 2025 AIME problems. These scores indicate the percentage of problems answered correctly, and they put Seed-Thinking-v1.5 in elite territory. For context, ByteDance reports that OpenAI’s state-of-the-art model (often equated with GPT-4 or its “o3” successor) scored about 87% on AIME 2024 and 86.5% on AIME 2025, while Google’s Gemini 2.5 Pro achieved around 92% on AIME 2024 and 86.7% on AIME 2025. This means Seed-Thinking-v1.5 essentially matches OpenAI’s model on AIME 2024, and although it trails on the newer 2025 test, it is not far off the leaders in absolute terms. Considering math Olympiad problems are something even many humans struggle with, an ~74–87% range is remarkable.
- Codeforces (Coding Competition) Pass@8: Codeforces is a popular competitive programming platform. The “pass@8” metric indicates the model’s success rate at solving coding problems with 8 attempts (allowing for some retries). Seed-Thinking-v1.5 achieved 55.0% pass@8 on a curated set of Codeforces challenges. This is again very high – by comparison, OpenAI’s model managed about 67.5%, and Google’s Gemini around 56.3% on the same benchmark. Seed-Thinking-v1.5 isn’t quite at GPT-4’s level for coding (GPT-4 is known to be extremely good at code generation), but it’s on par with Gemini 2.5 Pro and well above earlier models like DeepSeek-R1 (which scored ~45% here). For a model that isn’t primarily a coding-specialized system, a >50% solve rate on competitive programming problems is strong evidence of robust logical reasoning and the ability to do multi-step computations (e.g. writing and testing code in its own “mind”).
- GPQA (Graduate-level Physics Questions & Answers): This benchmark tests scientific and common-sense reasoning, especially in physics. Seed-Thinking-v1.5 scored 77.3% on the “GPQA Diamond” set. This places it near the top of the pack: OpenAI’s model scored ~79.7%, and Gemini 2.5 Pro about 84.0% on the same set. In other words, ByteDance’s model has essentially matched or slightly trailed the very best on a graduate-level science QA task. DeepSeek-R1 by comparison was around 71.5%. These high scores indicate the model’s chain-of-thought approach isn’t limited to math and code – it also can reason through science questions, likely by recalling relevant formulas, making inferences, and double-checking its answers (the kind of task where an internal chain-of-thought really helps).
- ARC-AGI: This is a particularly interesting evaluation – the ARC-AGI test is derived from the Advanced Reasoning Challenge and is used as a proxy for progress towards artificial general intelligence. It includes a variety of puzzle-like problems that require broad knowledge and reasoning. Here, Seed-Thinking-v1.5 actually outshines its competitors: it achieved 39.9%, whereas OpenAI’s model scored ~25.8% and Gemini 2.5 Pro about 27.6%. This was highlighted in media coverage: ByteDance’s model beat both Google and OpenAI on ARC-AGI, which is notable because this test is sometimes seen as an indicator of a model’s “general problem-solving” prowess. The absolute numbers are lower (since ARC-AGI is very challenging and no model gets extremely high scores yet), but the relative win suggests Seed-Thinking-v1.5’s particular training regimen (lots of logical puzzles, perhaps) gave it an edge on these out-of-the-box questions.
To better visualize how Seed-Thinking-v1.5 compares to other major reasoning AIs, consider the chart below which illustrates its performance versus a few peers on selected benchmarks:
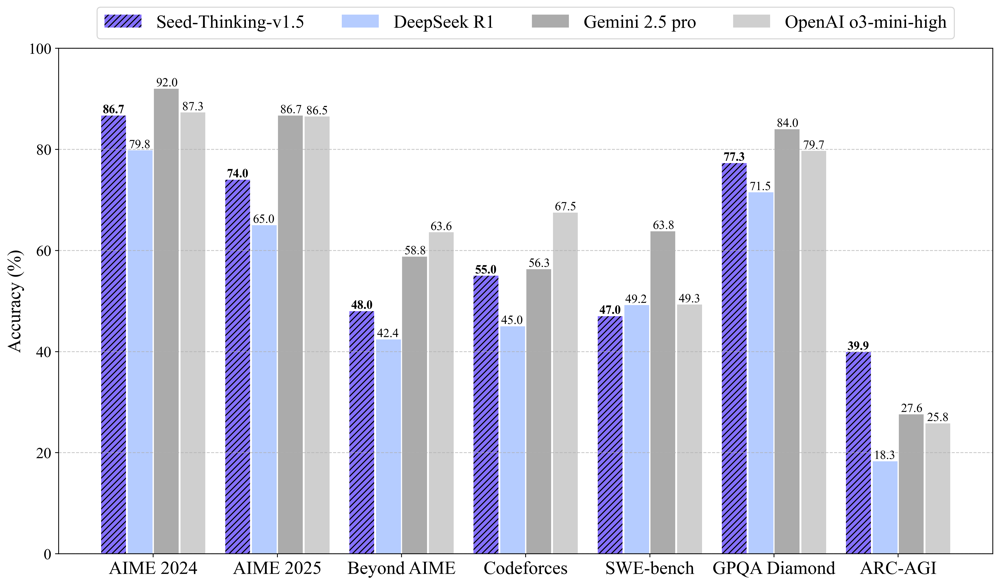
Seed-Thinking-v1.5 benchmark performance comparison with peer models (higher is better). Purple bars are Seed-Thinking-v1.5, blue are DeepSeek R1, and gray shades represent top models from Google (Gemini 2.5 Pro) and OpenAI (o3/GPT-4). On most tasks (AIME math, Codeforces coding, GPQA science), Seed-Thinking-v1.5 is close to the leaders, and it notably leads on the ARC-AGI general reasoning test.
As the above chart shows, Seed-Thinking-v1.5 (purple) is extremely competitive across the board. For instance, on AIME 2024 it reaches ~86.7%, not far below Google’s Gemini (gray) which tops that test, and ahead of DeepSeek R1 (blue) by a significant margin. On AIME 2025, the newer and harder math set, it scores lower (74%) but still respectable, while Gemini and OpenAI’s model are in the mid-80s. On the Codeforces coding challenge, Seed-Thinking-v1.5’s 55% is essentially neck-and-neck with Gemini’s performance and well above DeepSeek’s prior model. The GPQA science benchmark shows a similar story: Seed-Thinking trails Gemini’s best by a few points, but significantly outperforms older models like DeepSeek R1. And then there’s ARC-AGI, where Seed-Thinking-v1.5’s bar stands tallest – a testament to its strong general reasoning ability in comparison to even OpenAI’s and Google’s latest.
To provide a concise summary, here is a table comparing Seed-Thinking-v1.5 with a few other prominent reasoning AIs on a handful of key metrics:
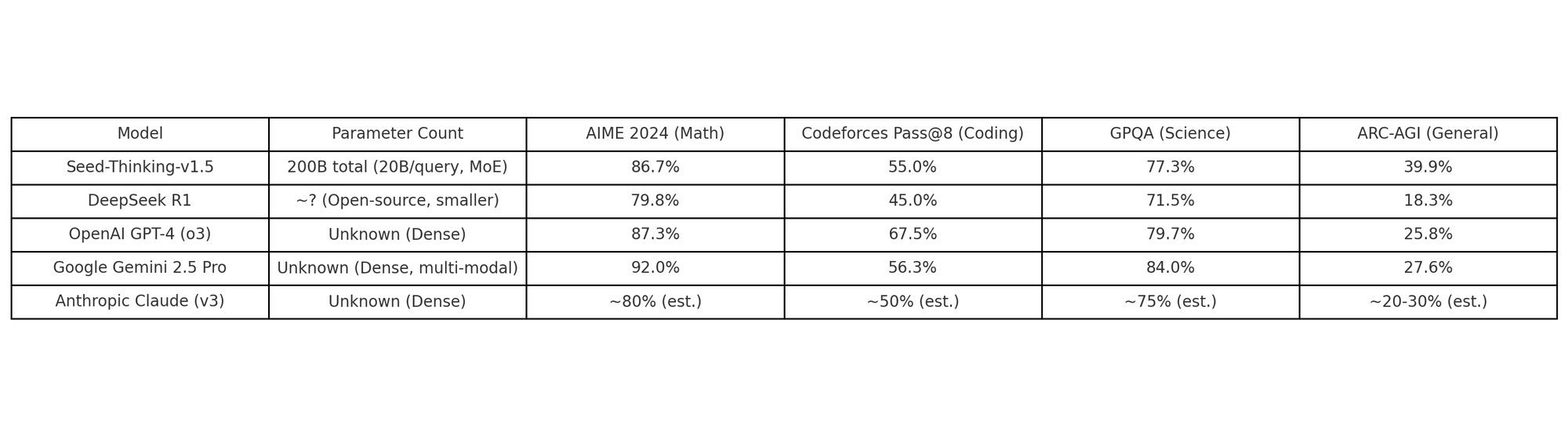
As we can see, Seed-Thinking-v1.5 holds its own against the giants. On a math benchmark like AIME, it’s within a few points of GPT-4 and Gemini, despite using fewer active parameters. In coding, it’s competitive with Google’s best, though OpenAI’s model currently leads. In science and general reasoning, Seed-Thinking-v1.5 is among the top performers, even outright winning on at least one measure (ARC-AGI). Also worth noting is the scale vs. performance consideration: GPT-4 and Gemini are closed models with unknown (but presumably very large) parameter counts and massive training regimes. By contrast, ByteDance’s model uses an innovative MoE to achieve similar results more efficiently. An IBM research blog commented on this trend, noting that Chinese AI companies like ByteDance and DeepSeek are “closing the gap with their American rivals” by embracing new techniques and sometimes open-sourcing their code. Indeed, DeepSeek-R1 and others have spurred competition that likely pushed ByteDance to leap forward with Seed-Thinking-v1.5.
It’s also instructive to compare Seed-Thinking-v1.5 with Anthropic’s Claude, another major AI known for its reasoning and large context capabilities. While we don’t have exact benchmark numbers for the latest Claude in the table above, Anthropic’s Claude 2 (and the experimental Claude 3 series like “Claude 3.7 Sonnet”) are generally considered on par with GPT-4 in many areas by early 2025. Google’s internal testing includes Claude 3.7 in comparisons; for example, Google reported bar charts where Gemini 2.5 Pro was compared against “OpenAI GPT-4.5” and “Claude 3.7 Sonnet,” with Gemini showing strong results across reasoning, science, and math. The takeaway is that the current generation of top models (GPT-4/4.5, Claude 2/3, Gemini 2.5, etc.) are all extremely powerful, and Seed-Thinking-v1.5 is right in that mix. In some niches, it may lag a bit (for instance, OpenAI’s models still have an edge in certain coding tasks, likely due to specialized code fine-tuning), but in others it shines (its math and logic performance is outstanding). ByteDance even noted that beyond these standard benchmarks, they assessed Seed-Thinking on general tasks via human evaluations, where it won 8% more often in head-to-head comparisons against DeepSeek-R1, indicating better overall quality and correctness in assorted prompts. This suggests that the model’s skills translate to real-world scenarios, not just controlled tests.
Another interesting point is that ByteDance created new benchmarks like BeyondAIME (an even harder math test designed to prevent models from simply memorizing known problems) to further challenge their model. On this BeyondAIME set, Seed-Thinking-v1.5 scored 48.0%, which, while lower in absolute terms, was still ahead of DeepSeek R1 and not far from some closed models. ByteDance plans to publicly release BeyondAIME and their Codeforces problem set to support future research. This openness is a positive sign – it means the community will have harder benchmarks to keep pushing reasoning AIs, and it reflects a collaborative spirit similar to how DeepSeek open-sourced R1. We might soon see GPT-4, Claude, or others tested on BeyondAIME as well, leveling the playing field for comparisons.
In summary, performance-wise Seed-Thinking-v1.5 is a top-tier reasoning AI. It doesn’t absolutely dominate every metric (nor would we expect a single model to do so across all possible tasks), but it shows consistently strong results. It often comes within a few percentage points of industry-leading models despite its clever efficiency, and in some cases exceeds them. This validates ByteDance’s approach of combining MoE with heavy reasoning-oriented training. For general tech enthusiasts, these numbers show that the AI landscape is no longer just “GPT-4 vs the rest” – new challengers like Seed-Thinking-v1.5 and Gemini are proving their merit. For AI researchers, it underscores how specific design choices (like reasoning via RL) can yield large gains on difficult benchmarks. And for industry observers, it highlights that competition is heating up: we now have multiple organizations (OpenAI, Google, Anthropic, ByteDance, DeepSeek, etc.) each with their own flavor of “reasoning AI,” pushing each other to new heights.
Having looked at the numbers, the next logical question is: what do these capabilities mean in practice? In the following section, we’ll explore some real-world and enterprise use cases where a model like Seed-Thinking-v1.5 could make a difference, and how companies might leverage such advanced reasoning abilities in their products and workflows.
Real-World and Enterprise Use Cases of Seed-Thinking-v1.5
A model like Seed-Thinking-v1.5 isn’t just about winning benchmark bragging rights – it’s designed with practical applications in mind. Its strong reasoning abilities open up a range of use cases in real-world scenarios and enterprise settings. Let’s consider a few domains where Seed-Thinking-v1.5 (and reasoning AIs in general) can be particularly impactful:
- Advanced AI Tutors and Education: Given Seed-Thinking-v1.5’s prowess in mathematics and science, one immediate use case is as an intelligent tutor or problem-solving assistant in education. It could guide students through complex math problems step-by-step, essentially demonstrating solutions the way a human teacher would. Because the model “thinks out loud” with a chain-of-thought, it can show the intermediate steps – this transparency is valuable in learning environments. For example, a student preparing for math contests could pose an AIME question to the model; instead of just giving the answer, the AI could walk through the proof or solution strategy, identifying where the student might have gone wrong. Similarly, in coding education, the model can help debug code by logically tracing the code execution in plain language and pinpointing errors. This is far more useful than just providing an answer – it helps the user learn the process of reasoning. ByteDance’s own human evaluations found Seed-Thinking-v1.5 able to generalize its structured reasoning to even creative domains, meaning it could potentially help in subjects like history or literature by constructing well-reasoned arguments or analyses. An AI tutor powered by such a model would not only answer questions but also teach critical thinking skills, making education more interactive and personalized.
- Enterprise Decision Support and Data Analysis: Businesses constantly need to analyze complex data and make decisions based on incomplete information. A reasoning AI like Seed-Thinking-v1.5 can serve as a powerful decision support assistant. Imagine feeding the model a stack of company reports, financial statements, and market research – with its multi-step reasoning, it could synthesize insights (“Given the trends, Product A’s sales dip seems correlated with factor X, here’s the likely reason…”) and even perform scenario analysis (“If we increase budget in Q3, what are the potential outcomes?”). Because the model was trained with a mix of verifiable logical tasks and general tasks, it has the rigor to handle data and the flexibility to discuss open-ended scenarios. In enterprise settings, such a model could be integrated into business intelligence tools, where an analyst could ask natural language questions and get back a reasoned response complete with the chain-of-thought (which might reference figures from the data). The structured approach that Seed-Thinking-v1.5 uses – verifying intermediate steps – is crucial here, as enterprises need trustworthy outputs. ByteDance’s introduction of Seed-Verifier (to check correctness) is particularly relevant: it offers a mechanism to ensure the model’s advice or analysis stands up to scrutiny. For regulated industries like finance or healthcare, having an AI that can explain why it reached a conclusion (and show that it checked its work) can make the difference between adoption and rejection of the technology. We can imagine, for instance, a financial advisor AI that uses Seed-Thinking-like reasoning to craft an investment strategy for a client and then provides a step-by-step justification, including verifying calculations against known financial formulas – this builds trust with the human user.
- Complex Customer Service and Troubleshooting: Many customer support queries, especially in tech domains, require reasoning through a problem. For example, diagnosing why a piece of software isn’t working involves gathering information, applying logical rules, and iteratively narrowing down possibilities. A reasoning AI can excel here by handling multi-turn, multi-step support dialogues. Seed-Thinking-v1.5’s training included role-play and open-ended Q&A, meaning it can converse naturally, but its added strength is keeping track of a longer reasoning chain. Picture a support chatbot for a cloud service that can help a developer debug their deployment issues: the chatbot could systematically ask questions, use chain-of-thought internally to hypothesize causes (“Could it be a network issue? Let’s check config A, then B…”), verify each hypothesis (perhaps by simulating an outcome or referencing documentation), and lead the user to a solution. Traditional chatbots might get confused or give up on such tasks, but a model optimized for reasoning would persist methodically. In a sense, it acts like a Tier-2 support engineer. Enterprise IT helpdesks could similarly use such AI to troubleshoot internal issues (like “My email isn’t syncing, what are possible reasons?” – the AI could walk through credentials, server status, etc.). The reinforced chain-of-thought means the model is less likely to make a random guess; instead it will weigh evidence and even say, “I suspect X because of Y” which is exactly what you want in a high-stakes support scenario.
- Creative and Generative Applications with Coherence: It might seem counterintuitive, but even creative tasks can benefit from a reasoning AI. For instance, content generation that requires logical consistency (like writing a mystery novel where clues must line up, or a screenplay with a complex plot) could leverage Seed-Thinking-v1.5. The model could plan out a storyline in a stepwise fashion – essentially doing plot reasoning – which reduces plot holes and inconsistencies. For game design or interactive fiction, the model could act as a narrative engine that keeps track of cause and effect. Moreover, enterprises in media (like ByteDance’s own TikTok or content platforms) could use such AI to moderate and analyze content in a more nuanced way. Content moderation often involves understanding context and reasoning about intent; a model that can reason (“This comment might be sarcasm, which changes its meaning”) could outperform models that rely on shallow pattern matching. Similarly, market research or trend analysis could be enhanced: the AI can comb through social media data and reason about public sentiment (“People are complaining about feature X because it might be causing Y issue, which they infer from Z – here’s the likely root concern”). These are tasks where just pattern recognition isn’t enough; a chain of reasoning is needed to get the full picture.
- Scientific Research and Problem Solving: Research labs and engineering firms can use reasoning AIs to assist in R&D. A model that has been trained on rigorous STEM problems (like Seed-Thinking-v1.5) can help in formulating hypotheses or checking work. For example, in drug discovery, a scientist could ask the model to reason about a molecular interaction: the model might recall relevant chemistry knowledge and logically deduce possible outcomes or suggest next experiments, all while explaining its thought process. Or an engineering team working on a complex system could use the AI to go through a fault tree analysis – the AI could systematically enumerate possible failure modes given the evidence. The key advantage is that the model doesn’t tire and can consider edge cases that humans might overlook, yet thanks to its training, it does so in a structured manner. We already see inklings of this: some researchers use large models to double-check proofs or come up with creative solutions to math problems. Seed-Thinking-v1.5’s high scores on math and logic indicate it could be a useful collaborator in research brainstorming sessions – not replacing human experts, but augmenting them with a tireless logical assistant.
- Enterprise AI Integration and AI Development: Interestingly, Seed-Thinking-v1.5’s design itself offers lessons to enterprise AI teams building their own models. ByteDance’s techniques (like the dual verifier for reward modeling) could be incorporated by others aiming to fine-tune models for reliability. In a meta-use-case, an enterprise might use Seed-Thinking-v1.5 as a quality assurance tool for AI outputs. For example, an insurance company using a different AI to generate policy reports might run those outputs through Seed-Thinking as a “reasoning validator” to catch any inconsistencies or errors. Because Seed-Thinking can evaluate content step-by-step, it might flag, say, a financial summary that doesn’t add up logically. This kind of cross-model ensemble, where one model’s reasoning checks another’s work, could improve reliability. ByteDance’s own introduction of things like Seed-Thinking-Verifier is an example of using one AI (or a specific mode of the AI) to judge another’s output for alignment. Enterprises highly value such guardrails for AI – especially when deploying models in sensitive applications – and Seed-Thinking-v1.5 provides a blueprint for how to implement them.
From an adoption perspective, ByteDance has highlighted that the structured, modular training process of Seed-Thinking-v1.5 can appeal to teams that want fine-grained control. For enterprise AI leaders, this is important: it means you can potentially tweak or specialize parts of the model (like specific experts or specific reward criteria) to fit your domain, rather than treating it as an opaque monolith. Also, the fact that Seed-Thinking is relatively stable under RL (thanks to innovations like VAPO/DAPO and dynamic sampling) could make it easier to fine-tune further for domain-specific needs without the model collapsing. For instance, a healthcare company might fine-tune one of the “experts” in the model on medical data to create a medical reasoning assistant, confident that the rest of the model’s structure will remain intact and that the fine-tuning won’t cause unpredictable behavior. ByteDance’s approach basically introduces trustworthiness and control into the training pipeline, which enterprises absolutely require when deploying AI in production systems.
Lastly, we should mention that ByteDance itself could integrate Seed-Thinking-v1.5 (or its components) into its products. TikTok might get smarter content recommendation or moderation algorithms that reason about trends. ByteDance’s office productivity apps or news aggregators could use the model to better summarize information with logical coherence. And of course, ByteDance could offer Seed-Thinking-v1.5 as a service or API for other businesses (depending on whether they open it or keep it in-house). We’ve already seen companies like Microsoft, AWS, and Google rushing to host models like DeepSeek-R1 and others on their cloud platforms. If ByteDance chooses to, Seed-Thinking-v1.5 could similarly be deployed via cloud for enterprise customers, giving them a powerful reasoning engine at their fingertips.
In summary, the real-world use cases for Seed-Thinking-v1.5 are plentiful wherever complex, multi-step reasoning is needed. Its arrival has implications not just for performance benchmarks, but for how AI can be applied to solve intricate problems in education, business, science, and daily life. A key theme in these applications is trust and reliability – the very attributes that ByteDance’s training strategy aimed to bolster (through verification and structured thinking). This makes Seed-Thinking-v1.5 especially attractive for enterprise adoption, where a predictable and interpretable AI behavior is as valued as its raw intelligence. As companies begin to experiment with such reasoning AIs, we are likely to see a new generation of AI-powered solutions that tackle tasks we once thought only humans could handle, from debugging code to composing detailed reports – all with a logical clarity that builds user confidence.
Implications, Future Directions, and Industry Reactions
The debut of Seed-Thinking-v1.5 carries several broader implications for the AI industry and research community. It represents not just a single model’s advancement, but a validation of certain trends and a harbinger of what’s to come.
Closing the AI Gap and Competitive Dynamics: One clear implication is that the gap between AI industry leaders is narrowing, especially with respect to high-level reasoning tasks. For a while, OpenAI’s GPT-4 was seen as the unchallenged king of LLM performance. But now we have multiple models – Gemini 2.5, Claude 2/3, DeepSeek R1, and ByteDance’s Seed-Thinking – all competing closely. Reuters noted that these developments by ByteDance, DeepSeek, and others could “challenge the market share of OpenAI… in terms of both performance metrics and fees”. In particular, Chinese tech companies are demonstrating that they can innovate and even leapfrog in certain areas (DeepSeek with low-cost open source models, ByteDance with advanced RL techniques). This competitive pressure is great for consumers of AI technology: it likely means faster improvements and possibly more affordable access. Indeed, DeepSeek’s strategy of undercutting OpenAI’s pricing (offering their model at a tiny fraction of GPT-4’s cost), combined with ByteDance’s efficiency focus, suggests a future where high-quality reasoning AI is not confined to Big Tech or high paywall services. Seed-Thinking-v1.5 itself hasn’t announced pricing or availability details, but if ByteDance were to offer it commercially, they would need to consider the open-source alternatives – which might encourage more openness or lower pricing from ByteDance as well.
Reinforcement Learning and “Thinking Time” as the New Norm: Technically, Seed-Thinking-v1.5 underscores that how a model thinks can be as important as how much it knows. The success of chain-of-thought reasoning and RL fine-tuning in this model (and peers like DeepSeek-R1) will likely encourage more AI developers to integrate these ideas. We may see future LLMs (like a GPT-5 or a future Claude) place even greater emphasis on an internal reasoning process, perhaps by default generating reasoning traces for every query. Anthropic has already explored techniques to improve the faithfulness of chain-of-thought – ensuring the reasoning a model outputs is truly reflective of its internal process, not just an afterthought. If models start to consistently “show their work,” it could greatly ease debugging and trust. ByteDance’s approach of training with rewards for correct reasoning steps is one way to enforce that faithfulness. We might see these methods borrowed or extended by others (for example, OpenAI might incorporate a similar verifier for math in GPT’s training to reduce mistakes). The notion of giving models a bit more “thinking time” – even if it slows response slightly – is now validated by better outcomes. This might become a standard setting: AI systems could have a fast mode for simple queries and a deliberation mode for complex ones, much like how Seed-Thinking-v1.5 would internally spend more effort on a harder problem. Such a paradigm shift moves AI away from being just reflexive auto-completers toward being closer to problem-solving agents.
Trustworthiness and Alignment: With reasoning models like Seed-Thinking-v1.5, there is hope for more trustworthy AI outputs. Because these models are trained to verify answers and think stepwise, they have a better shot at avoiding blatant errors or unsupported claims. ByteDance’s use of Seed-Verifier to check mathematical equivalence of answers, for instance, directly cuts down on mistakes in that domain. For industry, this approach can be extended – imagine a future customer service AI that has a built-in “verifier” for legal compliance, or a medical AI with a verifier that cross-checks against known medical guidelines before giving advice. The modular approach of Seed-Thinking (with separate verification modules) is a blueprint for safer AI in deployed settings. Moreover, having the AI explain its reasoning gives humans a chance to catch errors or biases. We should note, however, that reasoning models are not a panacea for all alignment issues. They can still produce a confident, step-by-step argument for a wrong conclusion if the training or reward model is flawed. Anthropic’s research points out that a chain-of-thought can be misleading if the model learns to game the system. The flip side of all this reasoning power is that these AIs could become very persuasive. A well-reasoned but incorrect answer might be harder for a layperson to doubt than a simple incorrect answer. Thus, the onus is on developers to ensure the verifiers and reward models truly align with truth and human values. ByteDance’s two-tier verifier is a step in that direction, but continued vigilance is needed. In industry reactions, Anthropic (the maker of Claude) has actually raised the question of whether we can always trust the reasoning these models provide, calling for methods to ensure the honesty of the chain-of-thought. So while Seed-Thinking-v1.5 improves trustworthiness by structure, it also brings to light the importance of robust alignment techniques as these models get more autonomous in their thinking.
Future Improvements and Research Directions: The team behind Seed-Thinking-v1.5 has indicated they are already looking ahead to refine their approach. One focus is on improving training efficiency and reward modeling especially for non-verifiable tasks. Non-verifiable (open-ended) tasks are tricky because you don’t have a simple ground truth reward; ByteDance will likely develop more nuanced human feedback mechanisms or advanced preference models to handle these. We might expect Seed-Thinking-v2.0 or beyond to close the gap in creative tasks with OpenAI’s models, for example, by better aligning the model’s long-form outputs with human preferences without sacrificing the structured approach. There is also the question of multi-modality. Google’s Gemini is natively multimodal (text, images, etc.) and even boasts a 1 million token context window. Seed-Thinking-v1.5 as described is primarily a text-based model focusing on text reasoning. ByteDance might extend this reasoning paradigm to images or other data – imagine a model that can not only solve a math word problem but also interpret a diagram or chart as part of its reasoning. Given ByteDance’s product portfolio (which includes video and image platforms), a multimodal reasoning model could be in their plans. If so, applying the MoE + RL method to multi-modal data would be a cutting-edge research challenge.
Another area is integration with agents and tools. The IBM blog mentioned ByteDance’s UI-TARS, a reasoning agent that can interact with graphical interfaces and take actions step-by-step, reportedly outperforming GPT-4 and others on certain benchmarks. This suggests ByteDance is looking beyond static Q&A models to interactive agents. It’s plausible that the core reasoning engine of Seed-Thinking-v1.5 (or a variant of it) could be embedded in an agent that can control a computer (for example, an AI that can use software, click buttons, and so on, while reasoning about how to accomplish a user’s goal). This would put ByteDance in competition with efforts like OpenAI’s ChatGPT Plugins or Autonomously reasoning agents. The combination of UI-TARS’ capabilities with Seed-Thinking’s reasoning could yield very powerful AI assistants that don’t just respond with text, but actually perform tasks on behalf of users (booking things, organizing information, etc.) with a reasoning trace. That could revolutionize productivity tools – imagine telling an AI to “set up a budget spreadsheet analyzing last quarter’s expenses,” and it actually operates spreadsheet software logically to do so. The industry is watching such developments keenly; any model that reliably takes actions based on reasoning is a step closer to more generalized AI assistants in daily life.
Industry Reactions: The reception to Seed-Thinking-v1.5 in the tech community has been largely positive and intrigued. Observers note that ByteDance’s entry “raises the bar” for what new models need to deliver. The fact that ByteDance even published a technical paper on GitHub (in a somewhat open fashion) was welcomed by researchers, as it contributes to the collective knowledge. Some analysts have pointed out that ByteDance’s AI lab (the “Seed” team) is now on the map alongside OpenAI, DeepMind, Meta AI, etc., whereas before Chinese efforts were sometimes seen as playing catch-up. Now they are originating novel approaches (like VAPO/DAPO frameworks) that others might adopt. Enterprise decision-makers are certainly taking note. VentureBeat’s piece specifically addressed technical leaders, noting that Seed-Thinking-v1.5 “presents an opportunity to rethink how reasoning capabilities are integrated into enterprise AI stacks”. It highlights how ByteDance’s methods (like the verifiers and modular RL) offer mechanisms for more trustworthy AI, which is a selling point for companies hesitant to deploy black-box models. The model’s stable training and improved iteration cycle (SRS) also drew interest, as it suggests a path to developing custom models faster and potentially with fewer resources. In China, specifically, having native advancements in AI reduces reliance on foreign models. We’ve seen a surge of local startups (e.g., DeepSeek) which – supported by cloud providers like Alibaba or Tencent – are making these models widely available. ByteDance adding its weight could accelerate the ecosystem there. It would not be surprising if ByteDance eventually offers Seed-Thinking-v1.5 via cloud APIs or licenses to strategic partners, further stirring the competitive pot.
One notable reaction came from AI researchers who see this as a sign of a paradigm shift. The community is increasingly viewing “size isn’t everything” – clever training (reasoning, RL, MoE) can outperform brute-force parameter counts. We might recall how in early 2020s, models just kept getting bigger to get better. Now, models like Seed-Thinking-v1.5 challenge that narrative by being relatively efficient yet highly capable. This could inspire more research into sparse models, adaptive computation, and self-reflection mechanisms. OpenAI and others are surely paying attention. In fact, Sam Altman’s mention of “o3 mini” (a smaller reasoning model OpenAI was launching) shows OpenAI itself is experimenting with efficient reasoning-specific models. We can expect an “arms race” not just in performance but in approaches to reasoning. This is healthy for the field – multiple independent implementations of similar ideas will teach us what truly works and what doesn’t.
In terms of future directions for Seed-Thinking specifically, the team signaled continuing work on RL techniques and possibly releasing more benchmarks. The public release of BeyondAIME and other internal testbeds will be a boon for transparency: we’ll have harder puzzles to solve, and broader collaboration in improving reasoning. If ByteDance were to open-source even a smaller version of Seed-Thinking (as a few commenters hoped when the technical report was released), it could galvanize community efforts to reproduce and build on their results. This hasn’t happened yet, and given ByteDance’s commercial interests, they might keep full models proprietary (Doubao-1.5 Pro was also not fully open). But even a restricted API access or research partnership availability would have impact.
To conclude, ByteDance’s Seed-Thinking-v1.5 marks an important moment in the evolution of AI. It shows that reasoning ability is now a primary goal for cutting-edge AI models, not just an afterthought. By combining a clever architecture with intensive reasoning training, ByteDance has created an AI that can go toe-to-toe with the best of Silicon Valley. The model’s success reinforces the idea that the next generation of AI won’t just be judged by how eloquently it can chat, but by how deeply it can reason and how reliably it can produce correct, reasoned answers. For general tech enthusiasts, this is exciting – it means future AI assistants will be much better at complex tasks and less likely to give nonsense answers. For AI researchers, Seed-Thinking-v1.5 provides a rich case study of integrating RL, MoE, and verification into large-scale training, likely influencing many papers and projects to come. For industry professionals, it’s a sign that they should start considering reasoning-focused models in their AI strategy, as these can unlock new applications and improve user trust. And for the global AI landscape, it underscores that innovation is happening worldwide, with collaboration and competition jointly pushing us toward more “intelligent” intelligence.
In the grand scheme, Seed-Thinking-v1.5 is more than just an AI model – it’s a statement that the era of “AI reasoning” is here. We can anticipate that its legacy will be seen in how future AI systems are built: with structured thinking, modular expertise, and a penchant for reflection baked in. The seed has been planted; now we watch as this new approach to AI thinking grows and transforms what machines can do.
References
- Seed-Thinking-v1.5: Advancing Superb Reasoning Models with Reinforcement Learning
https://github.com/FlagOpen/flagopen/blob/main/docs/seed-thinking-v1.5-en.md - Seed-Thinking-v1.5 Result Tables and Leaderboards
https://github.com/FlagOpen/flagopen/tree/main/seed-thinking-v1.5 - Now it’s TikTok parent ByteDance’s turn for a reasoning AI: enter Seed-Thinking-v1.5
https://venturebeat.com/ai/bytedance-reasoning-ai-seed-thinking-v1-5/ - ByteDance Official GitHub Repository for FlagOpen
https://github.com/FlagOpen/flagopen - ByteDance and DeepSeek Challenge OpenAI with Reasoning AIs
https://www.reuters.com/technology/tiktok-owner-bytedance-deepseek-lead-chinese-push-ai-reasoning-2025-01-22/ - DeepSeek-R1 Reasoning Model Release on Hugging Face
https://huggingface.co/deepseek-ai/deepseek-moe-16b-instruct - Gemini 1.5 and Reasoning Benchmarks
https://blog.google/technology/ai/google-gemini-1-5/ - OpenAI GPT-4 and Reasoning Capabilities Overview
https://openai.com/research/gpt-4 - Anthropic Claude 3 Model Introduction
https://www.anthropic.com/news/introducing-claude-3 - China’s Reasoning AIs and Global Implications
https://research.ibm.com/blog/china-reasoning-ai-models